
linux -- shell 编程
linux -- shell 编程
一、正则表达式
1、正则表达式 PK 通配符
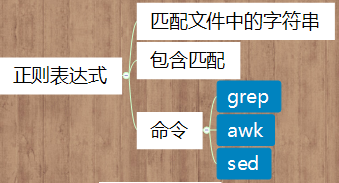

2、基础正则表达式
1)、* 前一个字符匹配 0 次或者任意多次
~ grep "a*" test_rule.txt # 匹配所有内容,包括空白行
~ grep "aa*" test_rule.txt # 匹配至少包含两个连续 a 的字符串
~ grep "aaa*" test_rule.txt # 匹配最少包含两个连续a的字符串
~ grep "aaaa*" test_rule.txt # 匹配最少包含四个个连续a的字符串
2)、. 匹配除了换行符之外的任意一个字符
~ grep "s..d" test_rule.txt # “ s..d ”会匹配在 s 和 d 这两个字母之间一定有两个字符的单词
~ grep "s.*d" test_rule.txt # 匹配在 s 和 d 字母之间有任意字符
~ grep ".*" test_rule.txt # 匹配所有内容
3)、^ 匹配行首
~ grep "^M" test_rule.txt # 匹配以大写“ M ”开头的行
4)、$ 匹配行尾
~ grep "n$" test_rule.txt # 匹配以小写“ n ”结尾的行
~ grep -n "^$" test_rule.txt # 会匹配空白行
5)、[] 匹配中括号中制定的任意一个字符,只匹配一个字符
~ grep " s[ao]id " test_rule.txt # 匹配 s 和 i 字母中,要不是 a 、要不是
~ grep "[0-9]" test_rule.txt # 匹配任意一个数字
~ grep "[a-z]" test_rule.txt # 匹配用小写字母开头的行
6)、[^] 匹配除中括号的字符以外的任意一个字符
~ grep "^[^a-z]" test_rule.txt # 匹配不用小写字母开头的行
~ grep "^[^a-zA-Z]" test_rule.txt # 匹配不用字母开头的行
7)、\ 转义符
~ grep "\.$" test_rule.txt # 匹配使用“ . ”结尾的行
8)、\{n\} 表示其前面的字符恰好出现 n 次
~ grep "a\{3\}" test_rule.txt # 匹配 a 字母连续出现三次的字符串
~ grep "[0-9]\{3\}" test_rule.txt # 匹配包含连续的三个数字的字符串
9)、\{n,\} 表示其前面的字符出现不小于 n 次
~ grep "^[0-9]\{3,\}[a-z]" test_rule.txt # 匹配最少用连续三个数字开头的行
10)、\{n,m\} 匹配其前面的字符至少出现n次,最多出现m次
~ grep "sa\{1,3\}i" test_rule.txt # 匹配在字母 s 和字母 i 之间有最少一个 a ,最多三a
二、字符截取命令
1、cut
1)、字段处理命令
2)、cut [options] 文件名
[options]

-f 行号: 提取第几列
-d 分隔符: 按照指定分隔符分割列
3)、example:
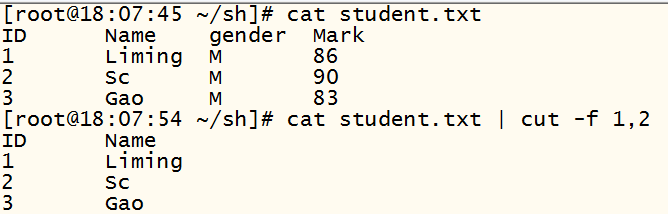
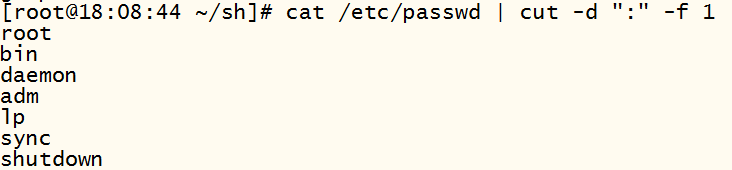

4)example局限性(无法匹配空格)

2、printf
1)、用法
printf ‘ 输出类型 输出格式 ’ 输出内容


2)、练习(多少个%s,就代表以多少个数字为一个字符)




3)、与 awk 之间的关系(printf 单独使用没什么屌用,主要是可以和 awk 配合使用)
print : print 会在每个输入之后自动加入一个换行符(linux 默认没有 print 命令)
printf :是标准格式输出命令,并不会手动加入换行符,如果需要换行,需要手工加入换行符
example:
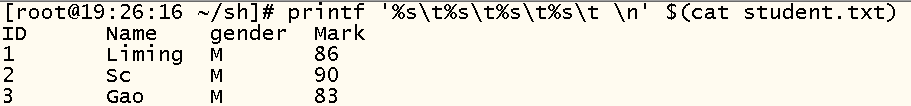
3、awk
1)、使用:awk ‘ 条件1 {动作1} 条件2 {动作2} ... ’
条件:一般使用关系表达式作为条件
x>=10 大于等于
x > 10 判断变量 x是否大于10
x<=10 小于等于
动作
格式化输出
流程控制语句
2)、BEGIN、END、FS内置变量、关系运算符






4、sed
1)、简介:
sed 是一种几乎包括在所有 UNIX 平台 (包括 linux)的轻量级流编辑器。
sed 主要是用来将数据进行选取,替换,删除,新增的命令。
2)、用法:
sed【options】【actions】文件名
【options】
- n :一般 sed 命令会把所有数据都输出到屏幕,如果加入此选择,则只会吧经过 sed 命令处理的行输出到屏幕
- e :允许对输入数据应用多条 sed 命令编辑
- i : 用 sed 的修改结果直接修改读取数据的文件,而不是由屏幕输出
【actions】
a \ :追加,在当前行后添加一行或多行。

c \ :行替换,用 c 后面的字符串替换原数据行。

i \ :插入,在当前行插入一行或多行。

d:删除,删除制定的行。

p:打印,输出指定的行。

s:字符串替换,用一个字符串替换另一个字符串。“ s/old/new/g ”

三、字符处理命令
1、sort (排序)
sort [选项] 文件名
sort --help
2、wc
wc --help
四、条件判断
1、按照文件类型进行判断



2、按照文件权限进行判断


写一个脚本 判断一个文件是否有读写执行权限 要能判断出是 用户 组 和其他人
3、两个文件之间的比较


4、两个整数之间进行比较


5、字符串的判断


6、多重条件判断



 浙公网安备 33010602011771号
浙公网安备 33010602011771号