198周赛
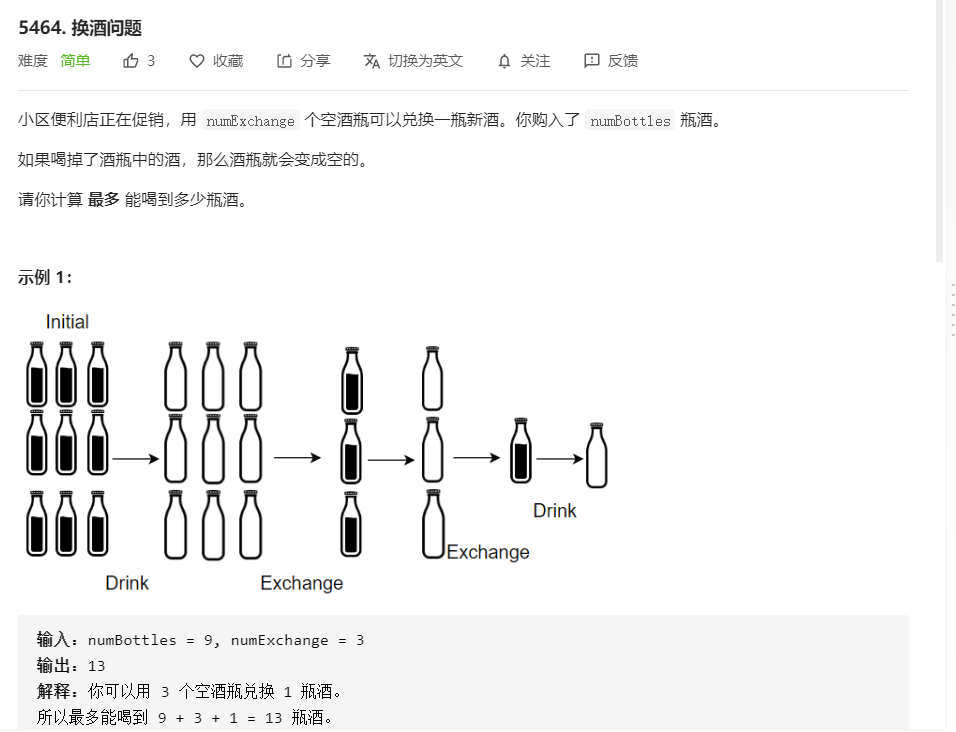
1 class Solution { 2 public int numWaterBottles(int numBottles, int numExchange) { 3 int res = numBottles; 4 while(numBottles / numExchange != 0) { 5 res += numBottles / numExchange; 6 numBottles = numBottles / numExchange + numBottles % numExchange; 7 } 8 return res; 9 } 10 }
简单的数学题,不做过多解释
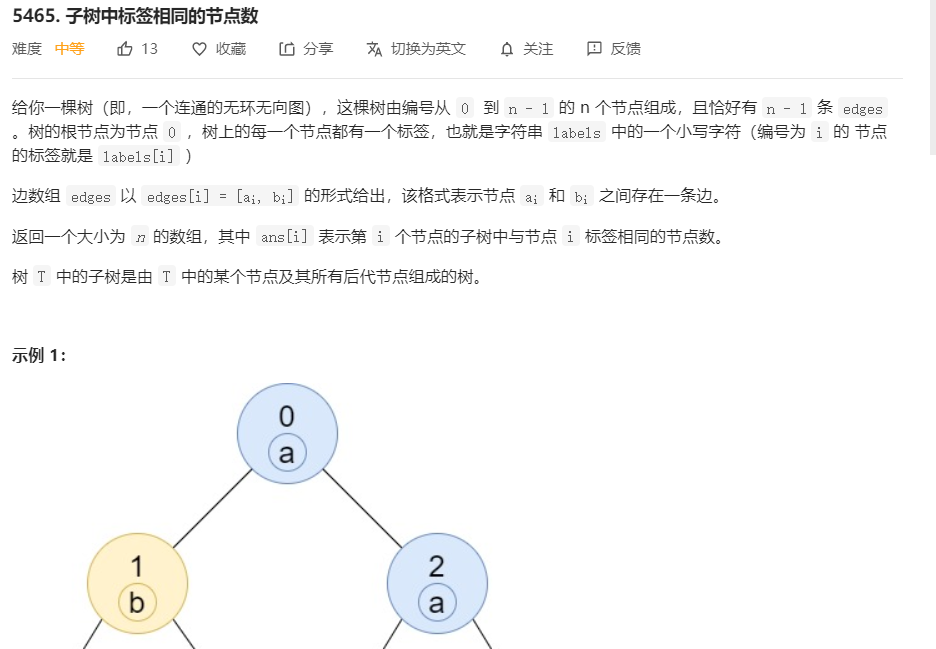
1 class Solution { 2 public int[] countSubTrees(int n, int[][] edges, String labels) { 3 Map<Integer, ArrayList<Integer>> link = new HashMap<Integer, ArrayList<Integer>>(); 4 for(int i = 0; i < n - 1; i++) { 5 int a = edges[i][0]; 6 int b = edges[i][1]; 7 if(!link.containsKey(a)){ 8 link.put(a, new ArrayList<Integer>()); 9 } 10 if(!link.containsKey(b)){ 11 link.put(b, new ArrayList<Integer>()); 12 } 13 link.get(a).add(b); 14 link.get(b).add(a); 15 } 16 int[] dp = new int[n]; 17 boolean[] visit = new boolean[n]; 18 dfs(0, labels, link, dp, visit); 19 return dp; 20 } 21 public int[] dfs(int n, String labels, Map<Integer, ArrayList<Integer>> link, int[] dp, boolean[] visit) { 22 visit[n] = true; 23 int[] res = new int[26]; 24 res[labels.charAt(n) - 'a']++; 25 for (int j = 0; j < link.get(n).size(); j++){ 26 if (!visit[link.get(n).get(j)]){ 27 int[] child = dfs(link.get(n).get(j), labels, link, dp, visit); 28 for (int k = 0; k < 26; k++){ 29 res[k] += child[k]; 30 } 31 } 32 } 33 dp[n] = res[labels.charAt(n) - 'a']; 34 return res; 35 } 36 }
解题思路:
根据题目要求,显然先要根据所给数组构造树,再利用dfs深度遍历,由于需要求每个节点的自数字母重复个数,在递归遍历时就需要用数组存储当前子树的字母重复情况,由于题目要求字母为a-z,可使用int[26]的数组进行存储,基本的思路便是,记录子树的字母情况,更新当前节点的字母情况,最后将当前节点重复数返回给dp[n],最后作为结果输出。当然,仍有不少细节需要考虑。
注意点:
首先是构造树时,起初以为数组中情况必定为ai作为父节点,bi作为子结点,便利用哈希表存储了ai作为key,bi作为value,后测试发现,有样例为bi为父节点,ai为子结点,程序不通过,于是改进程序,查看value中是否有ai,有则说明ai为父,bi为子,实际测试下来,内存又超标了。
最后便采取了使用双向连接的形式,将ai,bi都存入哈希表内。
这时新的问题又产生了,由于dfs中是利用与节点n连接的所有节点,遍历实现dfs,双向连接,将会出现死循环,即ai,bi不停地互相遍历。这时便在dfs中加入了一个新的数组visit[n],记录当前节点是否访问过,若已访问,便不进入递归,这样便不会出现死循环了。
在dfs遍历中同样需要注意数组的保存,由于需要将子树的情况存储,显然需要一个child[26]的数组来存取dfs递归的结果,而一个父节点又有多个子树,所以对应父节点又需创建一个res[26]的数组存取所有子树的情况,利用循环,将child数组的情况赋值给父节点的res数组,最后再根据当前节点的字母,即res[labels.charAt(n) - 'a']赋值给dp[n]即可。
-----------------------------------------待------------------------------------------------------------------续--------------------------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号