实验4 汇编应用编程和c语言程序反汇编分析
一、实验目的
-
理解80×25彩色字符模式显示原理
-
理解转移指令jmp, loop, jcxz的跳转原理,掌握使用其实现分支和循环的用法
-
理解转移指令call, ret, retf的跳转原理,掌握组合使用call和ret/retf编写汇编子程序的方法,掌握
参数传递方式
-
理解标志寄存器的作用
-
理解条件转移指令je, jz, ja, jb, jg, jl等的跳转原理,掌握组合使用汇编指令cmp和条件转移指令实
现分支和循环的用法
-
了解在visual studio/Xcode等环境或利用gcc命令行参数反汇编c语言程序的方法,理解编译器生成
的反汇编代码
-
综合应用寻址方式和汇编指令完成应用编程
二、实验准备
实验前,请复习/学习教材以下内容: 第9章 转移指令的原理
第10章 call和ret指令
第11章 标志寄存器
三、实验内容 略
四、实验结论
1. 实验任务1
task1.asm汇编源程序代码
assume cs:code, ds:data data segment db 'Welcome to masm!' data ends font segment db 8AH, 0ACH, 0FBH font ends code segment start: mov bx, 0b86EH mov es, bx mov di, 0040H mov si, 0 mov cx, 3 mov bx, 0 a: push cx mov si, 0 mov cx, 16 s: mov ax, data mov ds, ax mov al, [si] mov ah, 0 mov es:[di], ax mov ax, font mov ds, ax mov al, [bx] inc di mov es:[di], al inc si inc di loop s inc bx pop cx add di, 0080H loop a mov ah, 4ch int 21h code ends end start
经过反复调试,编译连接后执行结果
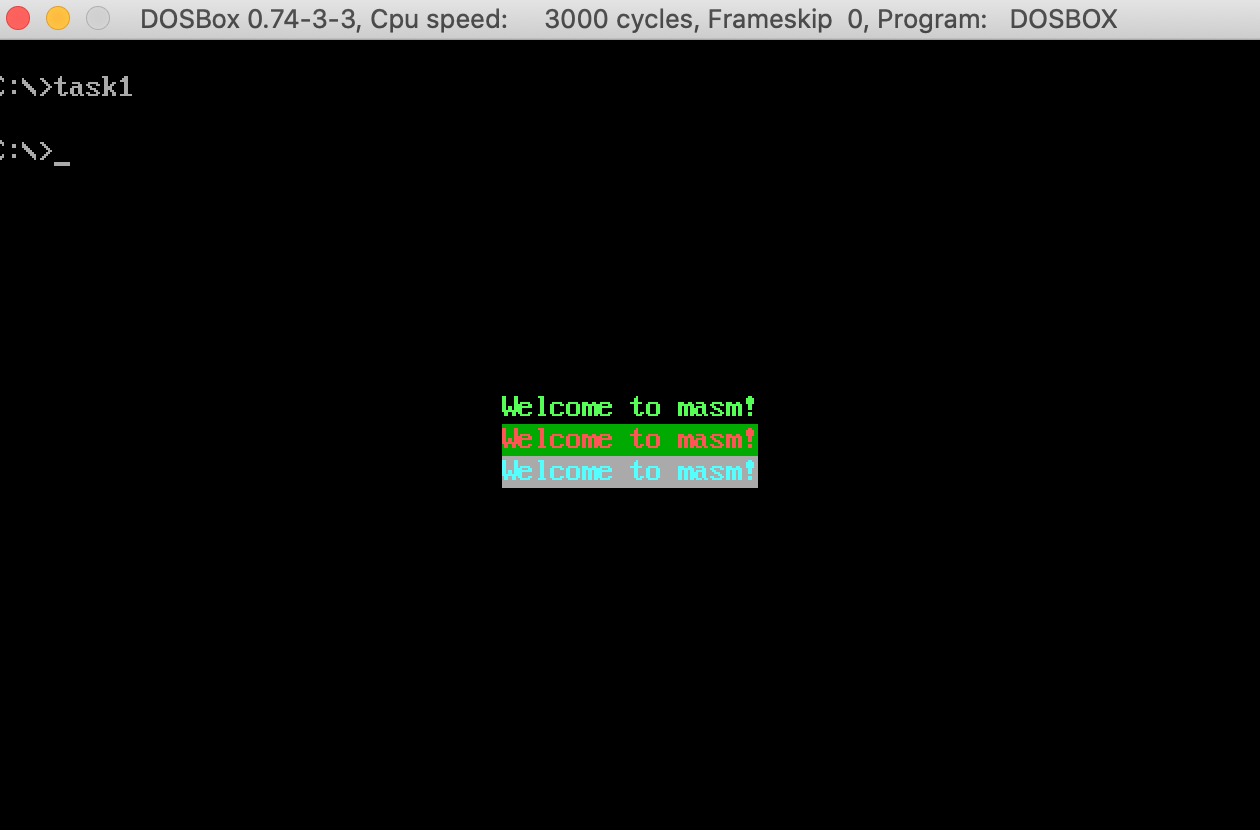
输出样式计算
经过试验任务1的摸索,掌握了输出位置的计算:B800H:0000开始的4000byte显存区域,彩色字符模式80*25彩色字符模式,每一个字符第一byte决定内容,第二byte决定样式
7 6 5 4 3 2 1 0
BL R G B I R G B
这样可以通过需要的样式计算出效果的数据,存放在数据segment中,用于输出时调用
例如最后一排字符,闪烁1,背景白色111,高亮1,字体蓝色011,得出十进制251,转换为十六进制0BFH,作为单字节数据放在数据段中,其余同理

多行输出原理
由于需要多行输出,每行需要遍历data段中16个字符 ,采用了双重循环的结构,外层循环进入内层循环时需要保存CX寄存器当前值,所以push入栈保存,当内层循环结束时在将其pop取回。需要注意的是每次循环需要将di,si重新设定。
关于输出位置定位,似乎在我笔记本上第0行(B800:0000)不能在黑框中显示出来,第一个能显示的行是B800:0000加上80*2个字节,(160)dec=00A0H,B80A:0000
*修正:如果运行前使用cls指令清屏则能显示第0行
同理计算出显示初始位置:
行号(总共25行-显示3行)/2=开始显示的11行,11行*80输出列*2byte/列=1760byte,(1760)dec=06E0H,B800:0000+06E0=B86E:0000
故设置开始位置存放在附加段寄存器es中,mov es, B86E
列号(总共80列-显示16列)/2=开始列号32列,32列*2byte/列=64byte,(64)dec=0040H
设置偏移量目的变址寄存器di,mov di, 0040H
试验时遇到的错误以及修正,可以看到下图中每行多出一个字符

一开始在向显存地址输入样式时使用通用寄存器AX作为容器取出字数据,向显存单字节输入时也是输入字数据,从而推测想显存输出时多输出了一个字节(向高位传入了脏数据),从而会多显示一个字符。将AX改为AL后,传入单字节数据,从而问题解决。
OMT
同样十六个字节,有内味了
2. 实验任务2
task2.asm汇编源程序代码
assume cs:code, ds:data data segment str db 'try', 0 data ends code segment start: mov ax, data mov ds, ax mov si, offset str mov al, 2 call printStr mov ah, 4ch int 21h printStr: push bx push cx push si push di mov bx, 0b800H mov es, bx mov di, 0 s: mov cl, [si] mov ch, 0 jcxz over mov ch, al mov es:[di], cx inc si add di, 2 jmp s over: pop di pop si pop cx pop bx ret code ends end start
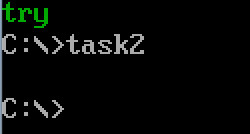
编译链接后运行结果
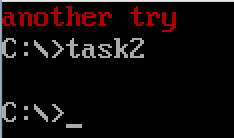
修改line3, line12后运行结果
对问题的解答
- line19-22, line36-39,这组对称使用的push、pop,这样用的目的是什么?
答:19-22push操作将寄存器中的值暂时存放在栈中,以便在跳转到当前程序段时将宝贵的寄存器空出以便使用。在当前程序段执行完后,line36-39使用pop还原寄存器先前的值,以便继续正常执行调用当前程序段的外层程序段。
- line30的功能是什么?
答:mov es:[di], cx输出操作,这里巧妙地对显存输出的两个比特位同时写入了数据。cl读取的是输出字符的单个字节,将预先设置好的彩色字符编码2(00000010红色)传入ch。值得注意的是,由于小端法存放,cl字节存放在低地址,ch存放在高地址。平时书写双字节数据时习惯HHLL,然而在内存中(debug时)内存自左向右地址从小到大排序,比较容易搞混淆。
3. 实验任务3
task3.asm汇编源程序代码
assume cs:code, ds:data data segment x dw 1984 str db 16 dup(0) data ends code segment start: mov ax, data mov ds, ax mov ax, x mov di, offset str call num2str mov ah, 4ch int 21h num2str: push ax push bx push cx push dx mov cx, 0 mov bl, 10 s1: div bl inc cx mov dl, ah push dx mov ah, 0 cmp al, 0 jne s1 s2: pop dx or dl, 30h mov [di], dl inc di loop s2 pop dx pop cx pop bx pop ax ret code ends end start
子任务1
反汇编查看MOV AH, 4C的地址
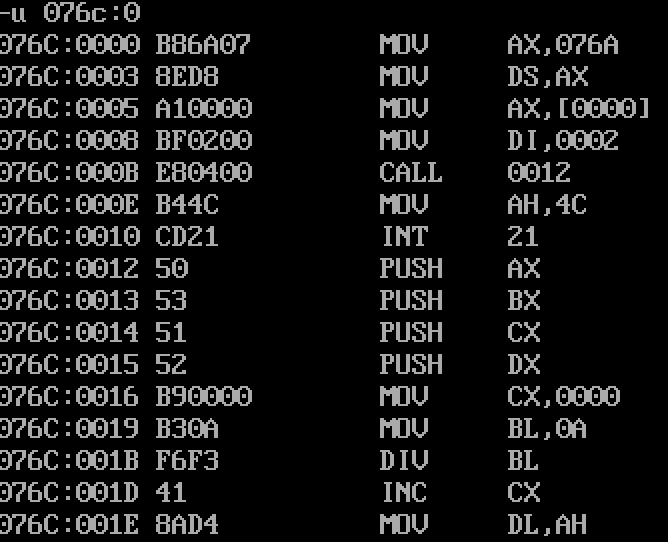
直接使用debug中-g命令执行到程序结束前

查看数据段中内容
C007->07C0H->(1984)dec
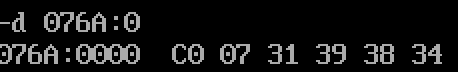
Q: 为什么这里dw 1984 没有占据16字节?
以字符形式存放的1984
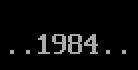
子任务2
修改后的部分代码
start: mov ax, data mov ds, ax mov ax, x mov di, offset str call num2str mov di, offset str mov si, 0 print: mov ax, 0B800H mov es, ax mov ch, 0 mov cl, [di] jcxz over mov ch, 7 mov es:[si], cx inc di add si, 2 jmp print over: mov ah, 4ch int 21h
运行结果
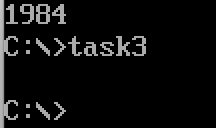
注意mov di, offset str的地方应该在循环外,否则每次都初始化自增将无效,导致程序陷入死循环
4. 实验任务4
task4.asm汇编程序源代码
assume cs:code, ds:data data segment str db 80 dup(?) data ends code segment start: mov ax, data mov ds, ax mov si, 0 s1: mov ah, 1 int 21h mov [si], al cmp al, '#' je next inc si jmp s1 next: mov cx, si mov si, 0 s2: mov ah, 2 mov dl, [si] int 21h inc si loop s2 mov ah, 4ch int 21h code ends end start
汇编链接后运行结果

问题解答
- line12-19实现的功能是?
答:int 21h调用功能1,从标准输入设备键盘读取字符,重定向存储到内存数据段中,知道遇到输入符号#结束循环。

- line21-27实现的功能是?
答:将刚刚从键盘输入并存储到数据段的字符逐个输出到标准输出流显示器上。

5. 实验任务5
在Xcode中创建Command Line Tool工程,语言选择为C
在Debug选项中将Debug Workflow中总是显示反汇编(disassembly)选项勾选
C语言源程序
#include <stdio.h> int sum(int, int); int main() { int a = 2, b = 7, c; c = sum(a, b); return 0; } int sum(int x, int y) { return (x + y); }
设置断点Debug查看其反汇编结果
主函数

被调用函数

体会:不太懂
- 可以看出sum函数入口地址0x100000fa0,在主函数中使用callq调用。
- 参数使用值传递方式放入寄存器di和si中,最后借助通用寄存器ax实现加法?
- 进入函数(代码段)时都要push %rbp,执行完后pop并且ret。
五、实验总结
1、虽然汇编课程已经接近尾声,但是在实践中一些基础的细节仍然经常混淆
- 一个字节byte有8比特bit 0000 0000,在十六进制表示时就是两个字符00,而字数据有两个字节所以格式形如0000H
- 在汇编源程序编写时,如果数据不带H,则是十进制数据,然而在debug中,数据默认为十六进制
- 数据传送时注意是一个字节还是两个字节,一个寄存器有两个字节,拆分成h和l使用则为一个字节
- inc指令给寄存器加1,如果要加多个则用多次或者用add指令。这里+1是(通常对偏移地址)增加一个字节,而非一个字(2byte)。
2、从试验任务2中学习的一个技巧:在字符串后跟一个0,使用cx读取输出到显存,使用jcxz(cx equals zero时)判断跳转,从而不需要人为数字符个数设置循环次数。在实验3中子任务2进行使用。
3、在X86中寄存器个数有限,通常要出入栈暂时保存,以便将寄存器挪作他用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号