

day5
1.编程的方法有:1)面向对象--->类--->class
2)面向过程--->过程--->def
3)函数式编程--->函数--->def
2函数.
函数的定义:将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用器函数名即可
格式:
#函数
def func1(): #用def来定义该函数名为func1
"""testing1"""
print("in the func1")
return 0
func1() #调用函数
3.过程跟函数的区别在于:函数有返回值return,而过程无
#函数
def func1():
"""testing1"""
print("in the func1")
return 0
#过程
def func2():
"""testing2"""
print("in the func2")
func1()
func2()
不过其实从某种程度上讲,其实,二者并无多大的区别,因为过程在无return的情况下,python解释器会隐形的给它一个放回值None
#函数
def fund1():
"""testing1"""
print("in the func1")
return 0
#过程
def func2():
"""testing"""
print("in the func2")
x = func1()
y = func2()
print("from func1 return is %s"%x)
print("from func2 return is %s"%y)
执行的结果的到:

在这编程中,x和y接受的是func1()和func2()的放回值;按理说,x的结果是0,而在进行到y时会出现报错现象,但结果是None?!
因而,在python中,过程其实也被当做函数,两者并无严格的界限
4..把一段段的逻辑或者是过程定义到def中 ---> 面向过程
函数式的编程--->不是说没有return就是函数式编程
5.
6.为什么要使用函数?
1.可让代码重复利用
2.保持一致性;当程序中,多段代码都调用一个相同函数,一旦这些代码都想同时改时,只需改函数
import time
def logger():
time_format = "%Y-%m-%d %X" #定义一个时间,x代表小时分钟秒
time_current = time.strftime(time_format) #以time_format的形式来显示时间的格式
with open("a.txt","a+") as f: #打开一个文件,然后以追加读的方式,获取这文件的格式符
f.write("%s end action\n"%time_current)
def test1():
print("in the test1")
logger()
def test2():
print("in the test2")
logger()
def test3():
print("in the test3")
logger()
test1()
test2()
test3()
3.可拓展性
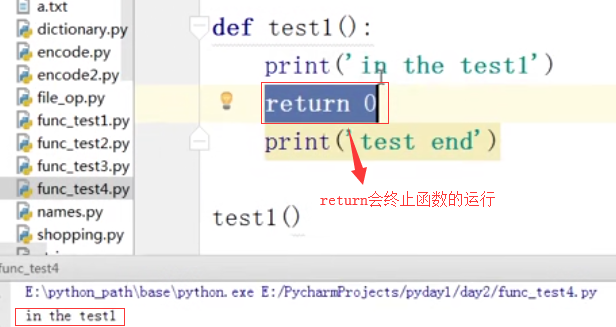
7.return为什么要有返回值
验证函数执行的结果,以及函数后面的程序需要根据这个函数的执行结果来进行不同的操作
def test1():
print("in the test1")
def test2():
print("in the test2")
return 0
def test3():
print("in the test3")
return test2
x = test1()
y = test2()
z = test3()
当返回值的个数 =0,放回None
=1,返回object
>1,返回tuple
def test1():
pass
def test2():
return 0
def test3():
return 0,"hello",["a","b","c"],{"name":"Francis"}
x = test1()
y = test2()
z = test3()
print(x)
print(y)
print(z)
8.

x,y叫形参;1,2叫实参
9.
def test(x,y,z):
print(x)
print(y)
print(z)
test(y=2,x=1,z=4) #关键字参数-->与形参顺序无关
test(1,2,3) #位置参数-->与形参一一对应
#test(x=2,3,4) #这会报错,因为关键字参数是不能写在位置参数前面的
test(3,z=2,y=6)
x = 1;1是定义的一个内存对象,x是定义的一个指向内存对象的一个引用
10.
def test(x,y=1): #y=1,y就是默认参数
print(x)
print(y)
test(2)
'''按理说,实参与形参是一一对应的,但当有默认参数是,即可以为y指定值,也可不指定,不指定即用默认'''
test(2,9)
11.
#*args:接受N个位置参数,转换成元组形式,当参数个数不确定时,用*
def test(*args):
print(args)
test(1,2,3,4,5,5)
test(*[1,2,3,4,5,5]) #args = tuple([1,2,3,4,5,5])
#**kwargs:接受N个关键字参数,转换成字典的方式
def test2(**kwargs):
print(kwargs)
print(kwargs["name"])
print(kwargs["age"])
print(kwargs["sex"])
test2(name="alex",age=8,sex="F")
test2(**{"name":"alex","age":8,"sex":"F"})
12.函数内的变量:局部变量
函数外的变量:全局变量
函数默认局部变量时没法改变全局变量的,除非用global
但是警告:程序变量理应是要在def外区定义的,而不应在def中通过global去定义它
school = "old_boy"
name = "alex"
def change_name(name):
global school
school = "Mage Linux"
print("before change",name,school)
name = "Alex li"#这个函数就是这个变量的作用域
age = 23
print("after change",name)
change_name(name)
print("school:",school)
print(name)
#print("age:",age)
除了字符串,数字是不能通过函数去改程序的变量(除非用global),复杂点的列表,字典是可以的
13.
函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元。
函数式编程中的函数这个术语不是指计算机中的函数(实际上是Subroutine),而是指数学中的函数,即自变量的映射。也就是说一个函数的值仅决定于函数参数的值,不依赖其他状态。比如sqrt(x)函数计算x的平方根,只要x不变,不论什么时候调用,调用几次,值都是不变的。
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
14.
递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
def calc(n):
print(n)
if int(n/2) > 0:
return calc(int(n/2))
print("->",n)
calc(10)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号