编码介绍
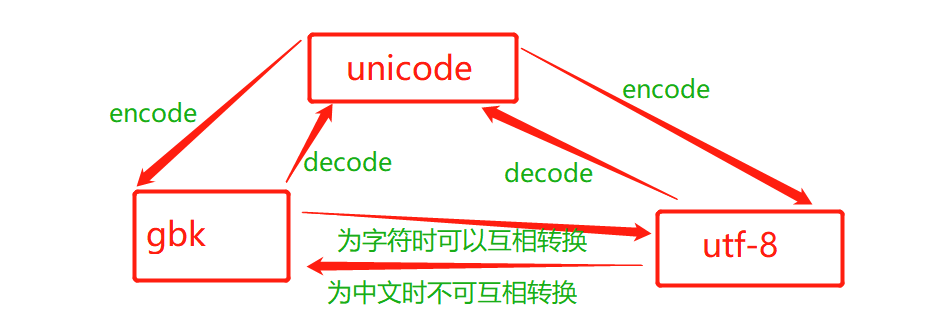
1 ==比较的是数据 is比较的是内存地址比较 2编码:不同编码之间的二进制是不能互相识别的,文件传输和存储不能用unicode,内存占用太大 ascii:数字,字母,特殊字符 字节:8位代表一个字符 字符:是内容的最小组成单位 abc:a代表一个字符 中国:中代表一个字符 unicode:万国码 四个字节代表一个字符 utf-8 最少用8位标识一个字符 a:8个字节 中:24个字节 数据类型;int bool str list dict tuple bytes str:编码默认为unicode bytes:编码非unicode,在内存编码看不懂 str文件存储传输必需先转换为bytes 编码方式必需和解码方式一致 str转换bytes用encode编码 bytes转换str转换用decode解码 s1 = "中国" b1 = s1.encode("utf-8") print(b1) # b'\xe4\xb8\xad\xe5\x9b\xbd' b2 = b1.decode("utf-8") print(b2) # 中国

 浙公网安备 33010602011771号
浙公网安备 33010602011771号