URL解析器的解析差异性
前言:如果一次请求中存在多个url parser进行解析的时候可能就会发生解析差异性导致产生安全问题,这种问题发生在同种语言中的不同解析函数,也有可能是不同语言中的解析函数
参考文章:https://www.blackhat.com/docs/us-17/thursday/us-17-Tsai-A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages.pdf
参考文章:https://curl.se/docs/CVE-2016-8624.html
同种语言中的不同函数parse_url和readfile解析的差异性
第一种
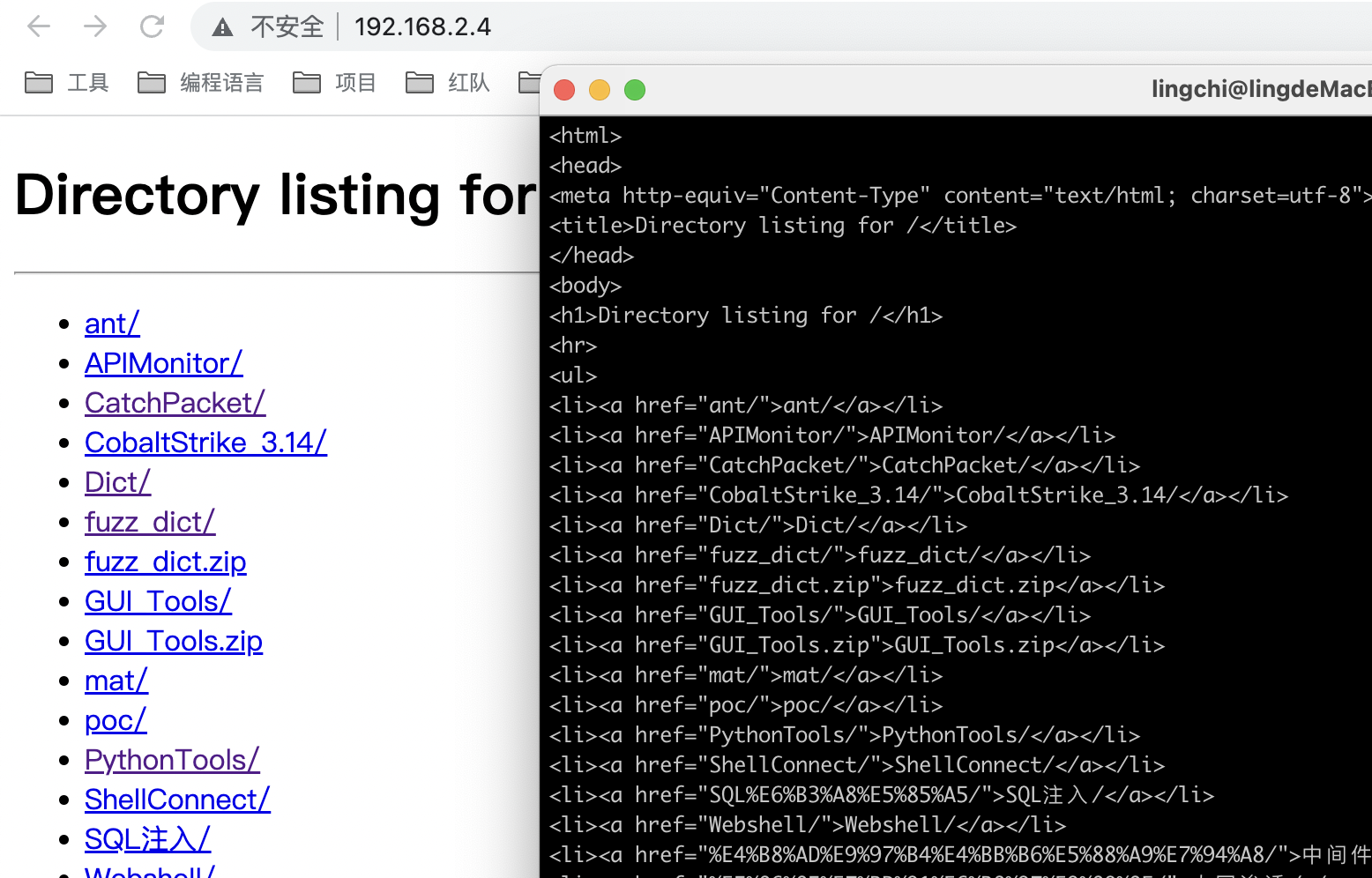
测试代码如下,最终发现访问的却是80端口,而不是1234端口,结果如下所示
<?php
$url = "http://192.168.2.4:80:1234/";
$url_components = @parse_url($url);
readfile($url);
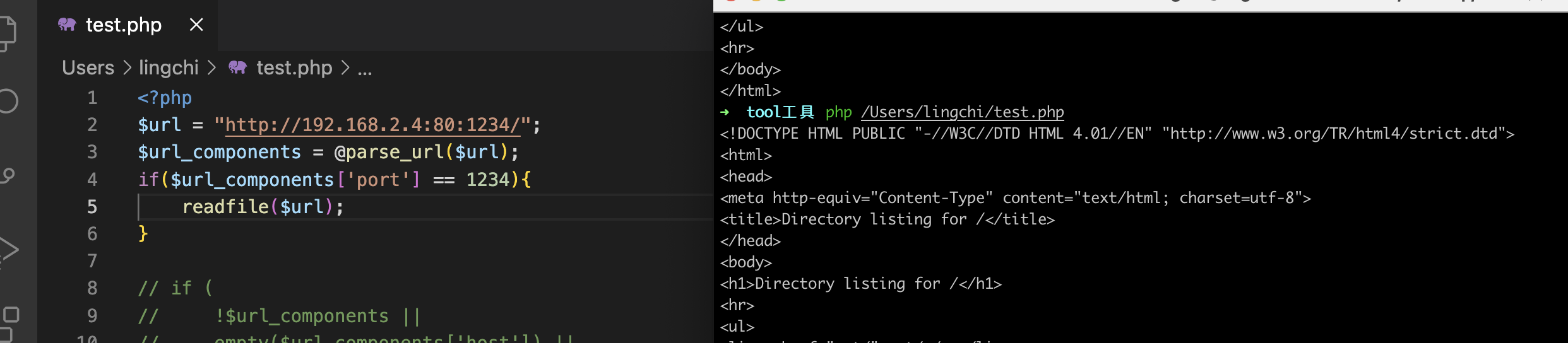
上面这种情况什么时候可以进行利用呢?如果端口限制的情况话,比如下面的代码,那么就可以使用如上差异性的方式进行逃逸利用,结果如下图所示,发现还是可以正常访问80端口
<?php
$url = "http://192.168.2.4:80:1234/";
$url_components = @parse_url($url);
if($url_components['port'] == 1234){
readfile($url);
}
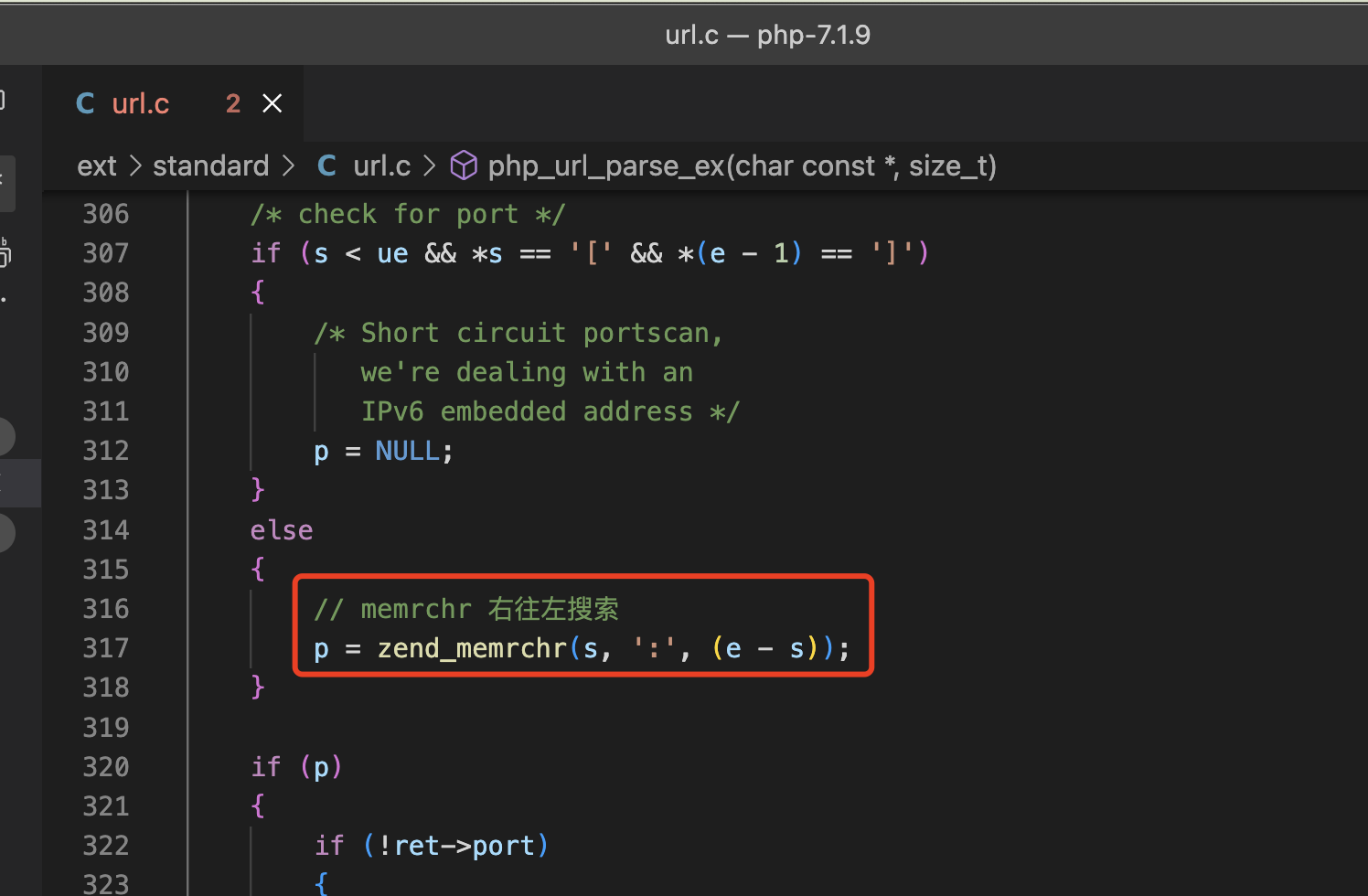
通过php的源代码可以看到ext/standard/url.c 中的 php_url_parse_ex方法中对于处理完整的url参数的时候,端口的获取是右往左搜索,所以优先选择最右边的冒号符号
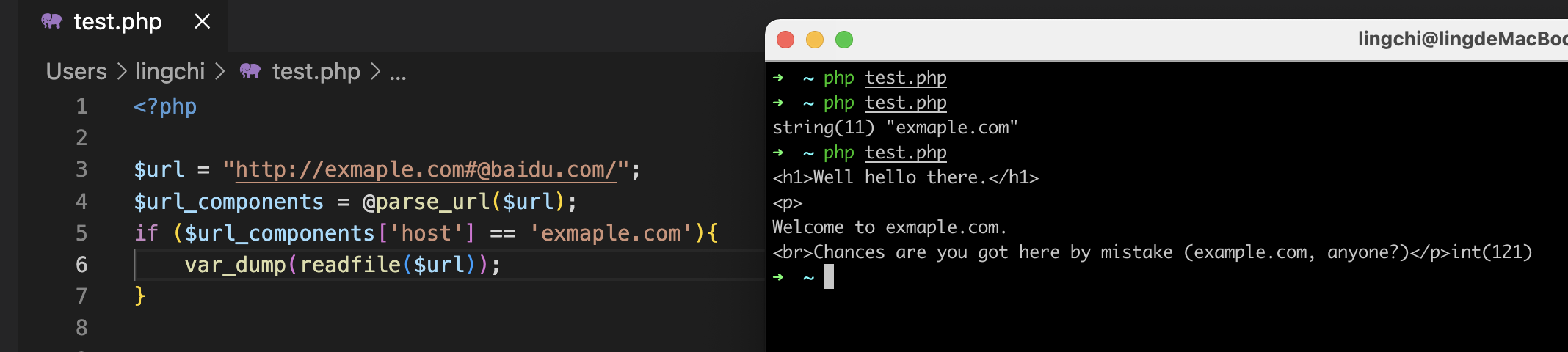
第二种
<?php
$url = "http://exmaple.com#@baidu.com/";
$url_components = @parse_url($url);
if ($url_components['host'] == 'exmaple.com'){
var_dump(readfile($url));
}
第三种
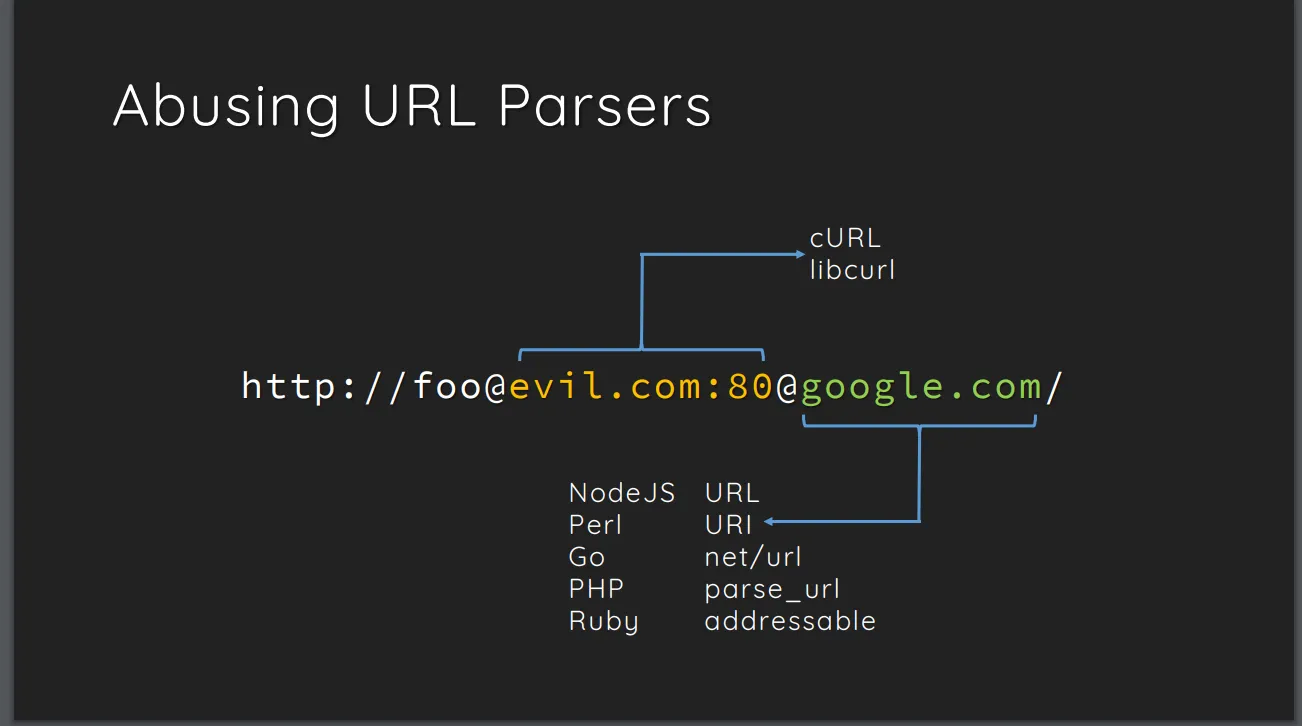
通过php的源代码可以看到ext/standard/url.c 中的 php_url_parse_ex方法中对于@符号的处理,是右往左搜索,所以优先选择最右边的@符号
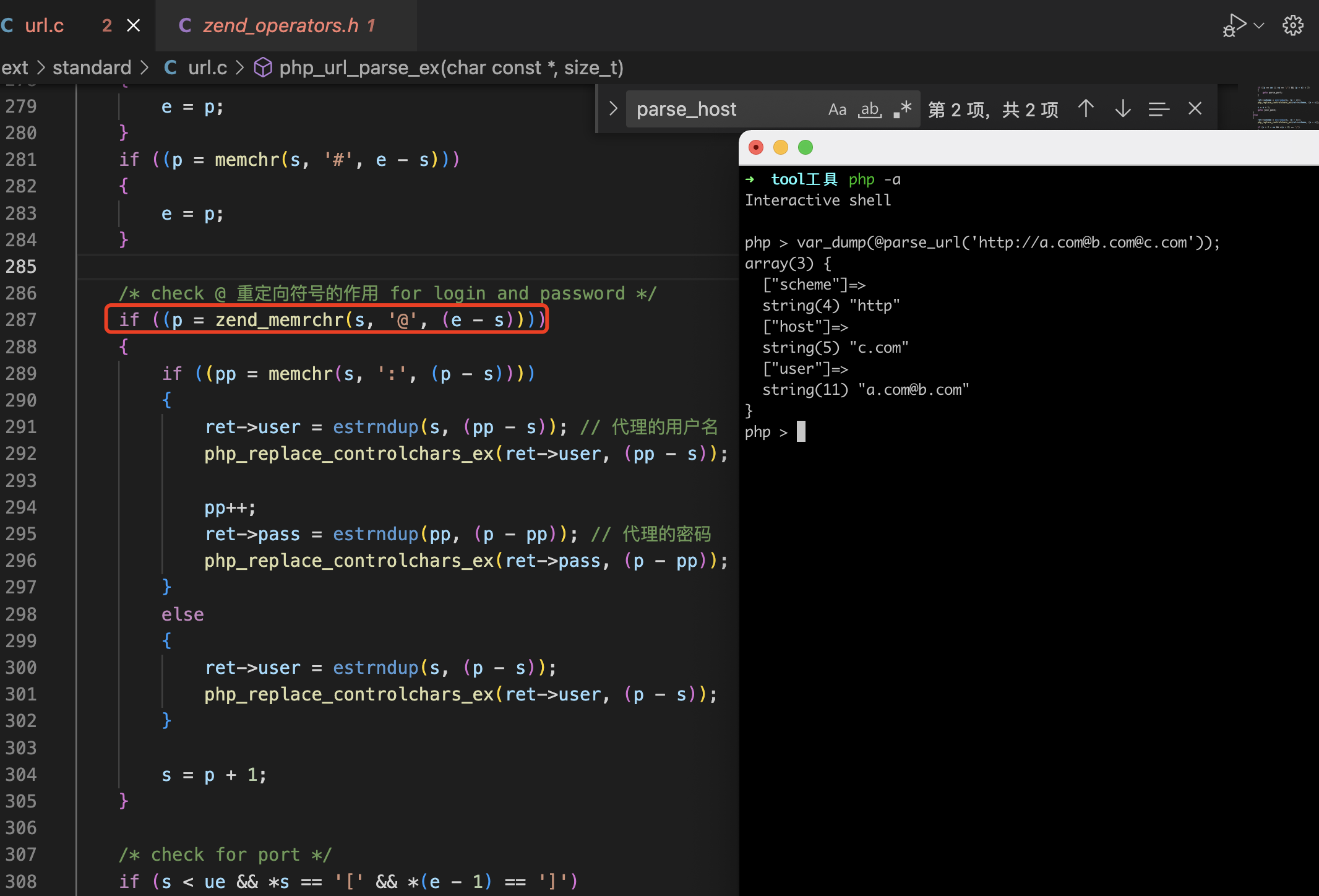
nodejs的url-parse模块和python的urllib3模块解析差异性导致的绕过问题
知识星球中的y4tacker师傅在ctf中分享的@黑魔法知识点
urllib3.util.parse_url 处理request.get传入的url数据,并且允许重定向@符号的运行

如果此时存在多业务语言处理的情况下就有可能出现问题,比如此时是nodejs的url-parse和python的parse_url同时处理的时候就有问题
在nodejs中对于http://192.168.1.20:7777\@i.ibb.co/1.png 解析的情况如下所示,可以看到最终解析的是重定向到了i.ibb.co地址
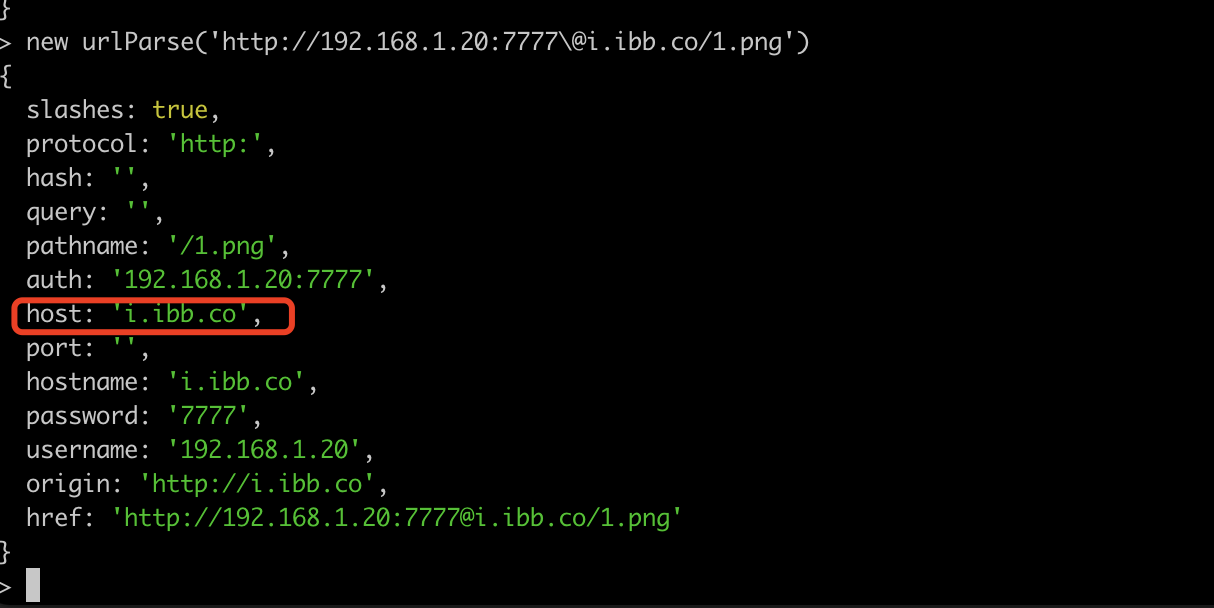
而在python中最终的请求地址还是原来的http://192.168.1.20:7777
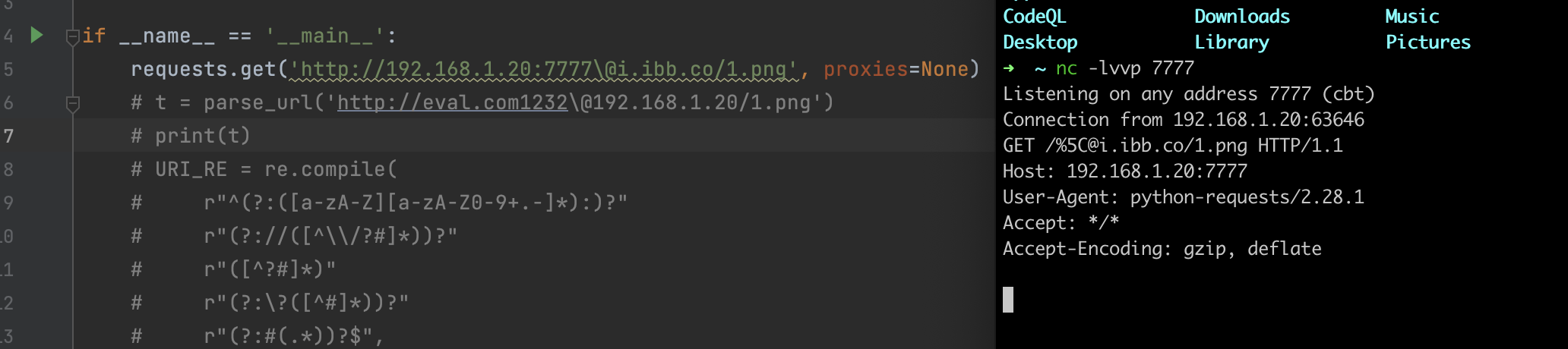
这里可以跟到urllib3.util.url.parse_url进行观察,对于url的解析是该地方进行触发的
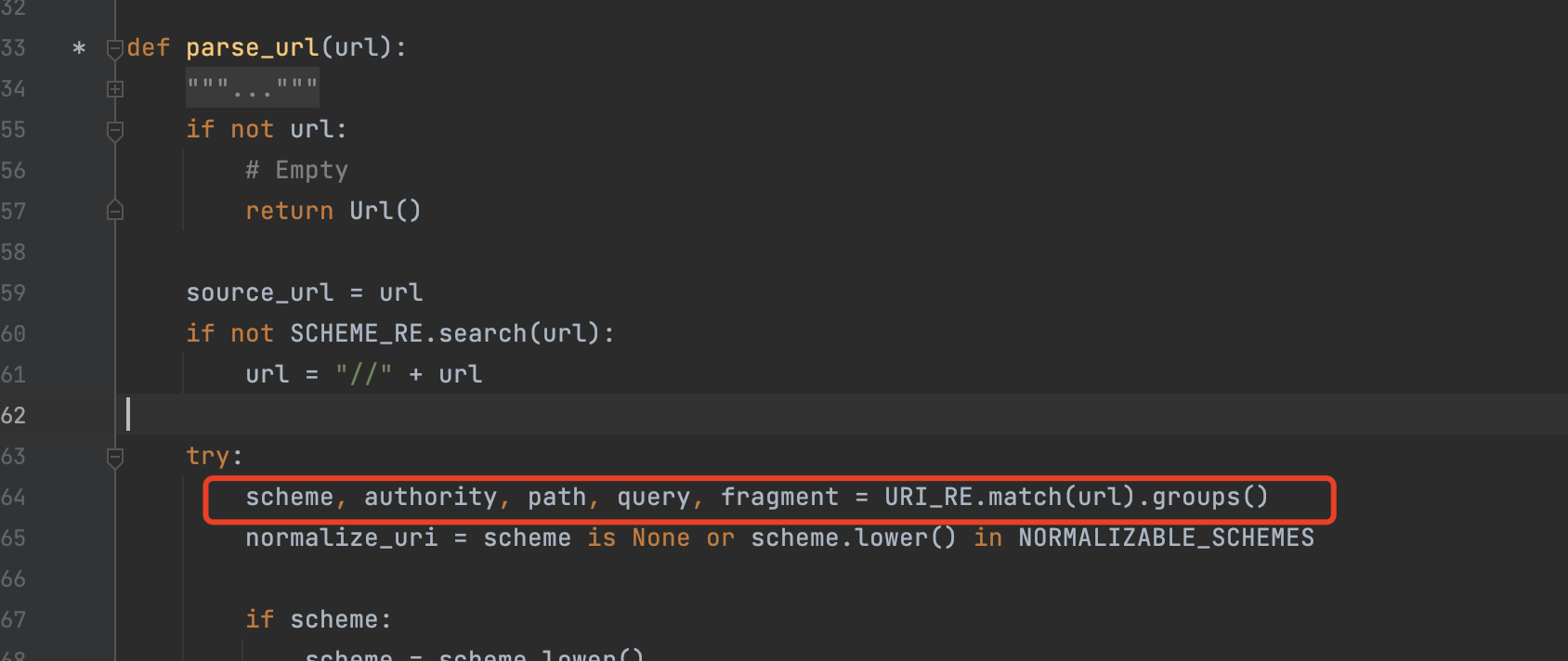
URI_RE = re.compile(
r"^(?:([a-zA-Z][a-zA-Z0-9+.-]*):)?"
r"(?://([^\\/?#]*))?"
r"([^?#]*)"
r"(?:\?([^#]*))?"
r"(?:#(.*))?$",
re.UNICODE | re.DOTALL,
)
对应匹配的正则如上,其中匹配host的是r"(?://([^\\/?#]*))?"片段,如果想要让其停止匹配,只需要满足\/?# 这四个符号即可
上述在node的UrlParse中\@还是以@来进行处理,而urllib3则不进行处理,因为提前匹配到\导致没有匹配到@,所以python就没有重定向,两者差异性导致存在解析问题
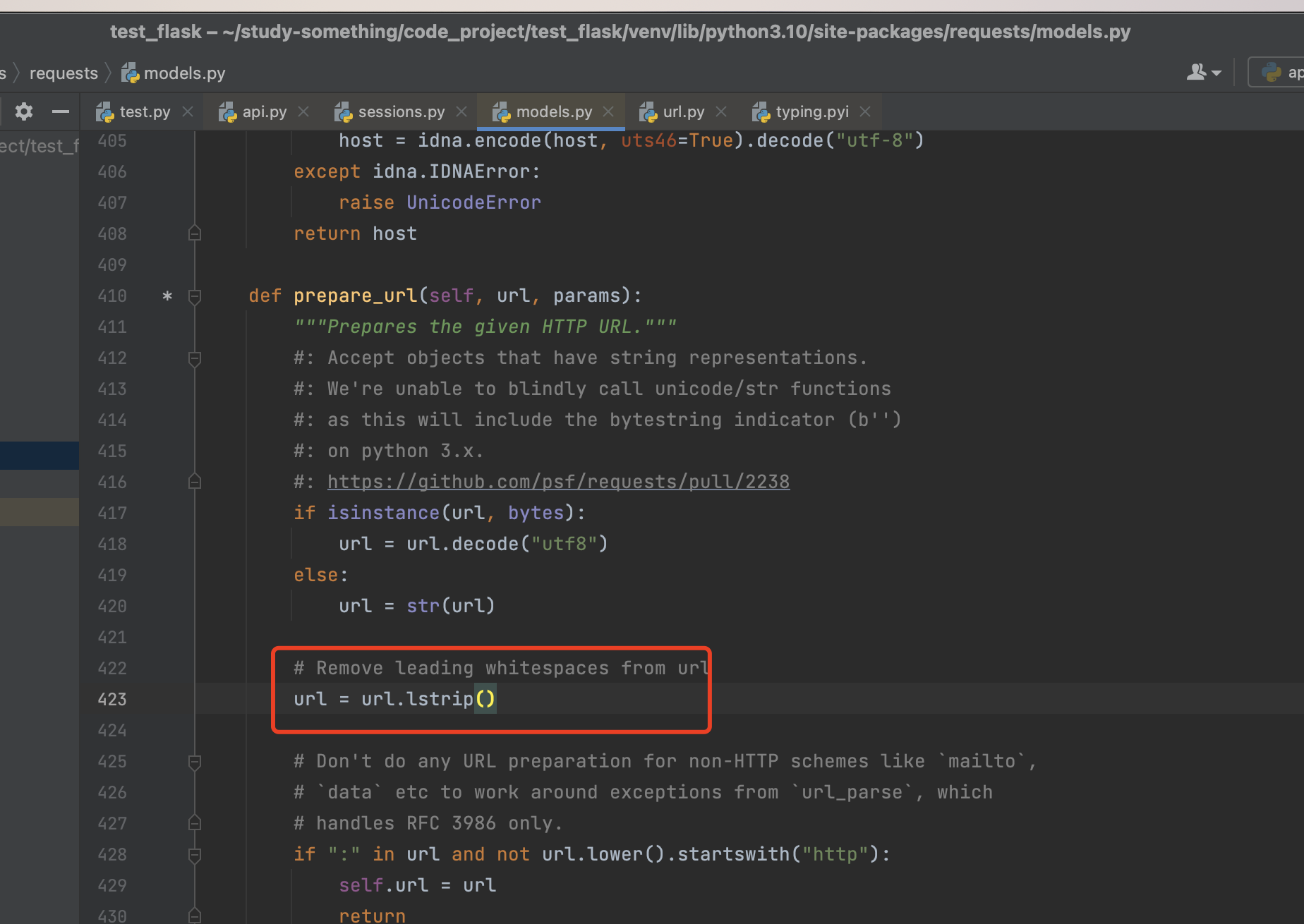
自动去左空格的特性
这种情况可能在于request.get可控,但是不允许直接http开头的场景会有用,简单记录下
request.get在发起请求的时候,其中会通过urllib3模块会对传入的url数据首先进行去除左空格,然后再发起请求

 浙公网安备 33010602011771号
浙公网安备 33010602011771号