
#研发解决方案介绍#Recsys-Evaluate(推荐评测)
郑昀 基于刘金鑫文档 最后更新于2014/12/1
关键词:recsys、推荐评测、Evaluation of Recommender System、piwik、flume、kafka、storm、redis、mysql
本文档适用人员:研发
推荐系统可不仅仅是围着推荐算法打转
先明确一下,我们属于工业领域。很多在学术论文里行之有效的新特奇算法,在工业界是行不通的。当年我们做语义聚合时,分词、聚类、相似性计算、实体词识别、情感分析等领域最终还都采用了工业界十几年前乃至于几十年前就流行的成熟算法。如果算法不能决定命运,那什么是关键呢?
算法+规则库+人工干预(整理语料、标识、调参数等),大都是脏活儿累活儿。
或者叫,特征+算法+人工干预,用特征缩小数据范围或降维。
我在2009年曾经写道:
在语义的世界里,可以近似地说:万事万物都是特征提取。 你只要找到特征,事情就好办。…………你期望毕其功于一役吗?自然语言处理的真实应用里是很难有什么场景找到一个通吃特征的。都是一层一层特征叠加的。一层特征去掉一部分垃圾数据。如此反复,终成正果。注意方法论。
梁斌在2012年微博说道:
统计粗且糙,乃大锤。规则细而精,乃小锤。先大场后细棋。
规则库怎么来的?得建设一些方便观测的外围系统,才能发现特征、建立规则、调整参数、观察效果。所以与此类似,做了推荐服务后,就需要推荐效果评测了。
推荐评测应用场景
电商推荐场景下有非常明确的指标:
- 推荐位展示次数、商品投放次数;
- 推荐位展示点击率、商品投放点击率;
- 最重要的是下单转化率和成单转化率(或叫支付转化率)这两个硬指标。
那么推荐评测系统应具备的功能有:
- 实时(至少是近乎实时)统计几个展示性指标
- 区分网站端和移动客户端的推荐展示效果
- 进一步区分不同客户端,如 iOS 和 Android
- 图
- 数据概览
- 图
- 按推荐位类型或推荐算法归纳各种指标
- 看了又看
- 浏览过该商品的用户购买了
- 您可能对以下商品感兴趣(猜你喜欢)
- 商品周边商品(注:只能是本地生活服务类商品)
- 签到弹窗推荐
- 商品附近门店
- 门店周边美食
- 附近吃喝玩乐
- 图
- ……
- 常见的评测推荐效果的两种实验方法
- 离线试验:
- 做法:从日志系统中取得用户的行为数据,然后将数据集分成训练数据和测试数据,比如80%的训练数据和20%的测试数据(还可以交叉验证),然后在训练数据集上训练用户的兴趣模型,在测试集上进行测试
- 优点:它不需要实际用户的交互
- 缺点:离线实验只能评测一个很狭窄的数据集切面,主要是关于算法预测或者评估的准确性
- 目的:提前过滤掉性能较差的算法
- AB测试:
- 做法:通过一定的规则把用户随机分成几组,并对不同组的用户采用不同的推荐算法,这样的话能够比较公平地获得不同算法在实际在线时的一些性能指标
- 图
- 推荐服务接口测试界面
- 暴露出来,让我们手工就可以提交,看看效果
推荐评测技术选型
说到实时日志聚合和处理,还得是 flume+kafka+storm,所以技术选型是:
Piwik+Flume+Kafka+Storm+Redis+MySQL
推荐评测数据流转流程
- 数据上报:——Piwik
- 主站本身部署了 开源流量统计系统 Piwik,所以在网页的各种推荐位上按规则埋点即可
- 实例:“浏览过该商品的用户还购买了”推荐栏第一位商品的a元素增加了wwe属性:wwe="t:goods,w:rec,id:ae45c145d1045c9d51c270c066018685,rec:101_01_103"
- 浏览器完全加载完成后, Piwik JavaScript 会向服务器端发送埋点数据
- Piwik 服务器端收到后,写磁盘日志文件
- 数据采集:——Flume
- Piwik 集群的每一台服务器上都部署了 Flume Agent
- agent 会向 推荐数据收集 Flume 集群 推送日志,譬如配置为每增加一行日志就推送,或每5分钟推送一次
- 手机客户端的埋点日志则存放在无线服务器端的 MySQL 中,所以我们用脚本每分钟读取一次数据,放到 flume 的监控目录下
- 数据接入:——Kafka
- 由于数据采集速度和数据处理速度不一定匹配,因此添加一个消息中间件 Linkedin Kafka 作为缓冲
- 数据流转方式为 Flume Source-->Flume Channel-->Flume Sink,那么我们写一个 Kafka Sink 作为消息生产者,将 sink 从 channel 里接收到的日志数据发送给消息消费者
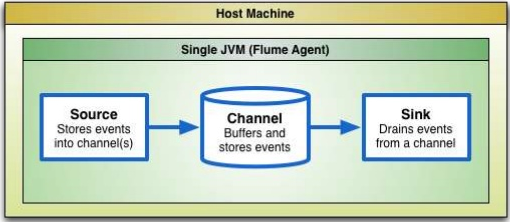 图
图- 流式计算:——Storm
- Storm 负责对采集到的数据进行实时计算
- Storm Spout 负责从外部系统不间断地读取数据,并组装成 tuple 发射出去,tuple 被发射后在 Topology 中传播
- 所以我们要写一个 Kafka Spout 作为消息消费者拉日志数据
- 再写些 Storm Bolt 处理数据
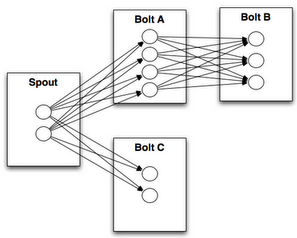 ,一个Topology的结构示意图
,一个Topology的结构示意图- 数据输出:——Redis
- Storm Bolt 实时分析数据之后,将统计结果写入 Redis
- 数据统计:——MySQL
- 评测系统实时数据直接从 Redis 中读取,并查询主站数据库追踪成单情况,同步到 MySQL 中,作为报表展示数据源
简而言之,数据按如下方式流转:
- piwik javascript
- piwik servers
- flume agent
- 自定义 kafka sink
- 自定义 kafka spout
- 自定义 storm bolt
- redis
- 评测系统计算
- mysql
- 评测系统报表展示
Flume+Kafka+Storm常见问题
虽然我们的实时流量统计和推荐评测系统均采用了 flume+kafka+storm 方案,但要注意这个方案也有一些小坑。下面摘录一些第三方的结论:
- 如果配置为每新增一条日志就采集,那么 flume 到 kafka 的实时数据可能会由于单条过快,造成 storm spout 消费 kafka 消息速率跟不上。延时可以是数据发射到 stream 中后进行 hbase 的计算操作引起的(注:hbase 的性能确实堪忧,不适合这种实时数据处理,尤其是加了较多索引之后);
- 可参考的一个数据:storm 单条流水线的处理能力大约为 20000 tupe/s (每个tuple大小为1000字节);
- tuple 过多,会由于 kafka 的 message 需要 new String() 进行获取,会报 gc 的异常;
- tuple 在 stream 中的大量堆积,造成超时自动回调 fail() 的函数;
- 可以进行多 tuple 结构的优化,把多个 log 打包成一个 tuple
- 就一般情况而言,单条发射能扛得住
Kafka Sink 消息生产者代码片段
|
KafkaSink.java
|
|
import kafka.javaapi.producer.Producer;
……
public class KafkaSink extends AbstractSink implements Configurable {
……
private Producer<String, byte[]> producer;
……
@Override
public Status process() throws EventDeliveryException {
Channel channel = getChannel();
Transaction tx = channel.getTransaction();
try {
tx.begin();
Event e = channel.take();
if (e == null) {
tx.rollback();
return Status.BACKOFF;
}
producer.send(new KeyedMessage<String, byte[]>(topic, e.getBody()));
tx.commit();
return Status.READY;
} catch (Exception e) {
|
Kafka Spout 消息消费者代码片段
spout 有多个,我们挑 kafka spout 看下。
|
KafkaSpout.java
|
|
public abstract class KafkaSpout implements IRichSpout {
……
@Override
public void activate() {
……
for (final KafkaStream<byte[], byte[]> stream : streamList) {
executor.submit(new Runnable() {
@Override
public void run() {
ConsumerIterator<byte[], byte[]> iterator = stream.iterator();
while (iterator.hasNext()) {
if (spoutPending.get() <= 0) {
sleep(1000);
continue;
}
MessageAndMetadata<byte[], byte[]> next = iterator.next();
byte[] message = next.message();
List<Object> tuple = null;
try {
tuple = generateTuple(message);
} catch (Exception e) {
e.printStackTrace();
}
if (tuple == null || tuple.size() != outputFieldsLength) {
continue;
}
collector.emit(tuple);
spoutPending.decrementAndGet();
}
}
|
Storm Bolt 代码片段
有多个自定义 bolt,挑一个看下。
|
EvaluateBolt.java
|
|
public class EvaluateBolt extends BaseBasicBolt {
……
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
……
if (LogWebsiteSpout.PAGE_EVENT_BROWSE.equals(event)) {
if (LogWebsiteSpout.PAGE_TYPE_GOODS.equals(pageType)) {
incrBaseStatistics(baseKeyMap, BROWSE_ALL, 1);
} else if (LogWebsiteSpout.PAGE_TYPE_PAY1.equals(pageType)) {
incrBaseStatistics(baseKeyMap, ORDER_ALL, 1);
}
String recDisplay = input.getStringByField(LogWebsiteSpout.FIELD_REC_DISPLAY);
recDisplayStatistics(recDisplay, time, pageType, baseKeyMap);
} else if (LogWebsiteSpout.PAGE_EVENT_CLICK.equals(event)) {
String recType = input.getStringByField(LogWebsiteSpout.FIELD_REC_TYPE);
|
- 投放点击率:推荐浏览量/推荐商品投放量
- 展现点击率:推荐浏览量/推荐位展现次数
- 推荐展示率::推荐位展示次数/总浏览量
- 推荐浏览量:经由推荐产生的浏览量
- 推荐商品投放量:推荐位投放的推荐商品数量(如:用户浏览A商品,那在浏览或购买推荐位产生的推荐商品为5个,则推荐商品投放量+5)
- 推荐位展现次数:如果推荐位有推荐商品并展示,计数+1
-over-
窝窝的解决方案介绍列表:
#研发解决方案#基于StatsD+Graphite的智能监控解决方案
#研发解决方案介绍#Recsys-Evaluate(推荐评测)
欢迎订阅我的微信订阅号『老兵笔记』,请扫描二维码关注:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号