Elasticsearch聚合 之 Histogram 直方图聚合
Elasticsearch支持最直方图聚合,它在数字字段自动创建桶,并会扫描全部文档,把文档放入相应的桶中。这个数字字段既可以是文档中的某个字段,也可以通过脚本创建得出的。
桶的筛选规则
举个例子,有一个price字段,这个字段描述了商品的价格,现在想每隔5就创建一个桶,统计每隔区间都有多少个文档(商品)。
如果有一个商品的价格为32,那么它会被放入30的桶中,计算的公式如下:
rem = value % interval
if (rem < 0) {
rem += interval
}
bucket_key = value - rem
通过上面的方法,就可以确定文档属于哪一个桶。
不过也有一些问题存在,由于上面的方法是针对于整型数据的,因此如果字段是浮点数,那么需要先转换成整型,再调用上面的方法计算。问题来了,正数还好,如果该值是负数,就会出现计算出错。比如,一个字段的值为-4.5,在进行转换整型时,转换成了-4。那么按照上面的计算,它就会放入-4的桶中,但是其实-4.5应该放入-6的桶中。
min_doc_count过滤
聚合的dsl如下:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50
}
}
}
}
得到的数据为:
{
"aggregations": {
"prices" : {
"buckets": [
{
"key": 0,
"doc_count": 2
},
{
"key": 50,
"doc_count": 4
},
{
"key": 100,
"doc_count": 0
},
{
"key": 150,
"doc_count": 3
}
]
}
}
}
上面的数据中,100-150是没有文档的,但是却显示为0.如果不想要显示count为0的桶,可以通过min_doc_count来设置。
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"min_doc_count" : 1
}
}
}
}
这样返回的数据,就不会出现为0的了。
{
"aggregations": {
"prices" : {
"buckets": [
{
"key": 0,
"doc_count": 2
},
{
"key": 50,
"doc_count": 4
},
{
"key": 150,
"doc_count": 3
}
]
}
}
}
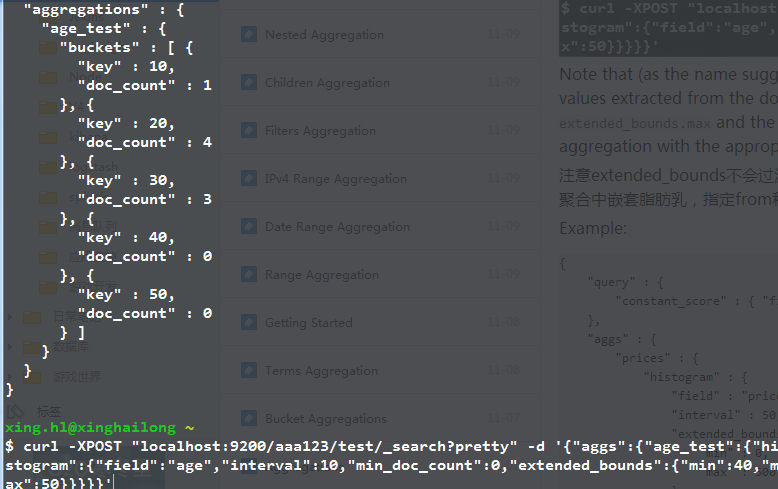
extend_bounds,指定最小值和最大值边界
默认情况下,ES中的histogram聚合起始都是自动的,比如price字段,如果没有商品的价钱在0-5之间,0这个桶就不会显示。如果最便宜的商品是11,那么第一个桶就是10.
可以通过设置extend_bounds强制规定最小值和最大值,但是要求必须min_doc_count不能大于0,不然即便是规定了边界,也不会返回。

另外需要注意的是,如果规定的extend_bounds.min要大于文档中的最小值,那么就会按照文档中的最小值来(extend_bounds.max也是如此)。
比如下面的这个例子,规定的extend_bounds.min和max分别是40和50,但是文档中含有比40还要小的数据,因此桶的定义仍然是按照文档中的数据来。
order排序
排序大同小异,可以按照_key的名字排序:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"order" : { "_key" : "desc" }
}
}
}
}
也可以按照文档的数目:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"order" : { "_count" : "asc" }
}
}
}
}
或者指定排序的聚合:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"order" : { "price_stats.min" : "asc" }
},
"aggs" : {
"price_stats" : { "stats" : {} }
}
}
}
}
keyed设置返回的方式
正常返回的数据如上面所示,是按照数组的方式返回。如果要按照名字返回,可以设置keyed为true
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"keyed" : true
}
}
}
}
那么返回的数据就为:
{
"aggregations": {
"prices": {
"buckets": {
"0": {
"key": 0,
"doc_count": 2
},
"50": {
"key": 50,
"doc_count": 4
},
"150": {
"key": 150,
"doc_count": 3
}
}
}
}
}
缺省的值
缺省值通过MissingValue设置:
{
"aggs" : {
"quantity" : {
"histogram" : {
"field" : "quantity",
"interval": 10,
"missing": 0
}
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号