
.net开发笔记(十六) 对前部分文章的一些补充和总结
补充有两个:
- 一个是系列(五)中讲到的事件编程(网址链接),该文提及到了事件编程的几种方式以及容易引起的一些异常,本文补充“多线程事件编程”这一块。
- 第二个是前三篇博客中提及到的“泵”结构在编程中的应用,我稍微做一点补充。
总结有一个:
- 如果您善于总结和类比,您会发现世界好多东西其实都是一样的。这部分主要理清楚框架时代中的框架和我们coder所写代码之间的关联。
下面是正文:
多线程事件编程
系列(五)中提及到了事件在注册和注销时,系统已经做了多线程处理,只是不太完美(以this为锁对象,this是public的,锁对象是不能对外公开的),后来通过自己定义锁对象加锁来实现的。可是该篇文章并没有提到在类内部激发事件时可能引发的异常:


1 class Subject 2 { 3 XXEventHandler _xx; 4 object _xxSync = new Object(); 5 public event XXEventHandler XX 6 { 7 add 8 { 9 lock(_xxSync) 10 { 11 _xx = (XXEventHandler)Delegate.Combine(_xx,value); 12 } 13 } 14 remove 15 { 16 lock(_xxSync) 17 { 18 _xx = (XXEventHandler)Delegate.Remove(_xx,value); 19 } 20 } 21 } 22 protected virtual void OnXX(XXEventArgs e) 23 { 24 if(_xx != null) 25 { 26 _xx(this,e); 27 } 28 } 29 public void DoSomething() 30 { 31 // … 32 OnXX(new XXEventArgs(…)); 33 } 34 }
如上代码所述,在多线程情况下,if(_xx != null)这行代码执行为true后,在执行下一行_xx(this,e);之前,_xx可能已经为null,引发异常理所当然。解决方法很简单,照葫芦画瓢,在OnXX中加锁,源代码变为:
1 protected virtual void OnXX(XXEventArgs e) 2 { 3 lock(_xxSync) 4 { 5 if(_xx != null) 6 { 7 _xx(this,e); 8 } 9 } 10 }
没错,这样确实能解决激发事件时有可能引发的异常,但如果仅仅是为了说明该方法可以解决问题的话,我是不会特大篇幅来说明它的。我们来看另外一种巧妙解决方法:
1 protected virtual void OnXX(XXEventArgs e) 2 { 3 XXEventHandler xx = _xx; 4 if(xx != null) 5 { 6 xx(this,e); 7 } 8 }
如上代码所述,在判断_xx是否为null之前,我们先用一个临时变量代替它,之后将使用_xx的地方全部替换为xx。这样,就不用担心xx会由其它线程改变为null了,因为xx对其他线程不可见。这个原理很简单,委托链是不可改变的(Delegates is immutable),也就是说,我们注册或者注销事件时,并不是在原来的委托链表基础上进行增加或者删除节点,而是每次都是重新生成了一个全新链表再赋给委托变量。其实这个诸位可以找到规律,我们在注册注销事件时,一般obj.Event+=…或者Event = Delegate.Combine(…) Event = Delegate.Remove(),可以看出,每次都是将一个全新的值赋给原来委托变量,并没有在原来链表基础上进行操作,因此,_xx和xx虽然同是指向同一链表,但是我们注销注册事件时,只是让_xx指向另外一个链表而已,原链表(xx)并没有变。
这个其实就是我们刚学习编程的时候,使用值传递调用方法时,实参将值传递给了形参,形参如果改变了(被重新赋值),实参的值是不会变的。指针(引用)也一样,形参指向了另外一个对象,实参还是指向原来的对象。
“泵”结构的另外一种方式
系列(十三)中(网址链接)讲到,在泵结构中,如果在获取数据环节直接处理数据容易降低获取数据的效率,也就是说,最好不要一获取到数据就处理它,因为处理数据大多数情况下是一个耗时过程,数据处理结束前,下一次“数据获取”不能开始,影响获取数据的效率。如下图:

图1
如图所示,处理数据在泵循环体内,数据处理结束之前,缓冲区中的数据就会大量积累。我们当时的做法是,获取数据后不马上进行分析处理,而是先将数据写入一个有序缓冲区,然后另创建“泵”去分析处理这些数据,这样一来,不会影响数据获取环节的效率。因此,诸位可以看见有三个“泵”(数据接收,数据分析,数据处理)联合工作。
事实上,太多“泵”协作工作也是会影响整个系统效率的,这就像多个人协同工作,虽然人多力量大,但是人多需要考虑同步共享资源、人跟人之间的协作能力等情况,这个好比“生产者消费者模式”,

图2
当“生产者-缓冲区-消费者”这一结构过多时,数据从接收到最终被处理,是需要一个漫长的过程,因此,我们需要寻找一个平衡点。有两种改进方式:
1)

图3
如上图,接收数据后,直接开启异步分析和处理过程。
2)
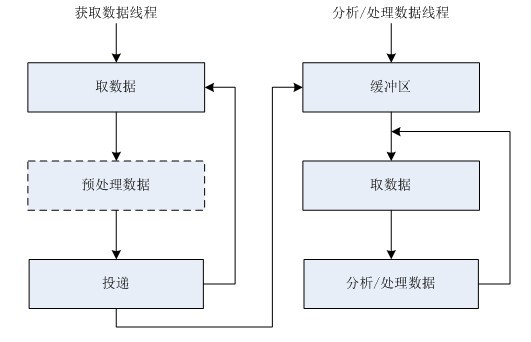
图4
如上图,数据接收后,将其写入缓冲区,然后另外再开启线程分析和处理数据,这个就把“数据分析”和“数据处理”合并在一块了。这两个严格来说耦合度比原来那个要高。
注:在通讯编程中,图3适合UDP通信,因为UDP每次接受到的数据都是一个完整的数据包,数据接收后直接开始分析处理,图4适合TCP通信,因为TCP传输数据是以“流”格式传输的,并且每次接收到的数据不一定是完整的,我们必须先将接收到的数据按顺序写入一个有序的缓冲区中,然后再从缓冲区中提取完整的数据进行分析处理。
框架与客户端代码之间的关系
总结这个的主要原因是上次在网上看见有一个人问,使用基类引用指向一个派生类实例时,为什么不能通过该引用访问派生类中使用new关键字覆盖基类的方法,而只能访问到基类中的方法。我看了他给出的实例代码,发现其实根本就没必要使用基类引用去指向派生类实例,纯属滥用。是的,好多时候我们不知道为什么要那么使用,只因为我们看见别人那样用过,代码:
1 class People 2 { 3 string _name; 4 string _sex; 5 // … 6 public void Info() 7 { 8 ShowInfo(); 9 } 10 protected virtual void ShowInfo() 11 { 12 Console.WriteLine(“基本信息 姓名:”+_name+” 性别:”+_sex); 13 } 14 } 15 class Student:People 16 { 17 //… 18 protected override void ShowInfo() 19 { 20 base.ShowInfo(); 21 Console.WriteLine(“附加信息 职业:学生”); 22 } 23 } 24 25 class Teacher:People 26 { 27 //… 28 protected override void ShowInfo() 29 { 30 base.ShowInfo(); 31 Console.WriteLine(“附加信息 职业:教师”); 32 } 33 }
以上三个类型,现在假设我要输出某一类型对象的信息,该怎么写?
public void Func(People p)
{
p.Info();
}
这是大多数人的写法,理由很简单,它既可以输出Student的信息也可以输出Teacher的信息,确实是这样的,但是当你确定要输出信息的对象类型时(而且很多时候属于这种情况),是没必要这样写的,比如你确定要输出信息的对象类型为Student,那么你完全可以这样:
public void Func(Student s)
{
s.Info();
}
我真不明白为什么你明明非常确定要使用哪个类型,却偏偏要用基类引用代替派生类引用,就是因为大家常说的“依赖于抽象而非具体”吗?这个话没错,但要看场合,当你不确定要使用哪个类型时,你可以用一个抽象引用(基类引用),当你已经非常确定了使用哪个类型时,你就没必要再去使用一个抽象引用了,直接使用具体引用(派生类引用)。抽象引用能完成的东西,具体引用都能做到,反过来却不成立,如果Student类中有一个public DoHomework(),你能用People类型的引用去访问它吗?你根本不能。
因此,可以很大胆地说,“依赖于抽象而非具体”是一个迫不得已的结论,如果编程世界里没有那么多的不确定,完全不需要这个结论,谁会去使用一个不确定性的东西呢?可是,事实上编程世界里有太多的不确定,表现最为明显的就是框架中,之所以框架中有那么多的不确定性,那是因为通常情况下,框架具有“通用性”(没有通用性的也就不叫框架了),也就是说,框架可以使用在多个场合下,而框架编写者则完全不知道每个具体场合是什么样的,有哪些功能,每个功能怎么实现的,既然不知道具体情况,那么框架编写者只有使用一系列抽象引用临时代替了。
现在既然不确定性无可避免,那么,怎么才能让框架本身与客户端代码(框架使用者编写的代码)能够很好的“协同工作”呢?此时,我们打开我们发达的大脑,开始拼命想象,喷血联想,协同工作?好像通信中经常听到的词语,两个远程主机如果想要协同工作,双方必须遵守同一个通信协议,如下图:

图5
那么,我们完全可以把“框架”当做服务端,框架使用者编写的代码就为客户端了,他们之间协同工作也应该遵守相同的协议,如下图:
图6
具体编码中,这个协议就表现为接口(Interface)或基类(相对而言)这样的东西,框架中使用这些东西访问客户端代码,客户端代码也必须实现这些接口或者派生自这些基类。
像框架这种依赖于抽象的做法在解决通用性的同时,还能最大限度降低耦合度,框架编写者完全不用关心使用者的具体实现,使用者只要遵守协议,怎么实现不归框架管。 当然也有缺陷,就是框架只能通过事先规定的协议去访问客户端代码,客户端代码中如果有协议之外的东西,框架是访问不到的。这就要求框架编写者在编写框架的时候考虑充分,将所有有可能涉及到的东西都归纳到协议之中。
本篇需结合前面三篇博客(与“泵”有关的)一起阅读。希望对各位有帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号