
掌握numpy(一)
目录##
掌握numpy(一)
掌握numpy(二)
掌握numpy(三)
掌握numpy(四)
NumPy是一款用于科学计算的python包,强大之处在于矩阵的运算以及包含丰富的线性代数运算的支持。本文将对numpy一些常用的用法进行讲解,一来是对自己的知识进行梳理,二来作为一份备忘录供以后查阅,如果有幸被你读到,通过阅读本文希望对你有帮助。由于本人能力有限,如果有错误请指出~
创建数组##
首先我们要先引入numpy,常用的引入方法为
import numpy as np
np.zeros###
该方法能够创建一个全为0的数组
>>np.zeros(5)
array([ 0., 0., 0., 0., 0.])
上面是创建一个1维的数组,创建一个多维的数组也很简单,eg下面是创建一个二维的数组
>>a = np.zeros((3,4))
>>a
array([[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]])
在上面的例子里面,每一个维度被成为轴(axis)
当定义了一个array的时候,我们可以查看其形状
>>a.shape
(3L, 4L)
还有查看该数组种元素的个数
>>a.size
12
在numpy种,数组类型有着其封装好的数据类型ndarray:
>>type(a)
numpy.ndarray
N维度数组###
当然,我们还可以定义更高维度的数组,eg:下面我们定义一个3D 数组
>>np.zeros((2,3,4))
array([[[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]],
[[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]]])
np.ones###
与前面讲的zeros类似,这是创建一个全为1的数组
>>np.ones((3,4))
array([[ 1., 1., 1., 1.],
[ 1., 1., 1., 1.],
[ 1., 1., 1., 1.]])
np.full###
创建一个数组,并由给定的数值进行初始化
>>np.full((3,4),np.pi)
array([[ 3.14159265, 3.14159265, 3.14159265, 3.14159265],
[ 3.14159265, 3.14159265, 3.14159265, 3.14159265],
[ 3.14159265, 3.14159265, 3.14159265, 3.14159265]])
np.empty###
这个又是什么意思呢?创建一个未初始化的数组,里面的值全部随机
>>np.empty((2,2))
array([[ 2.96206109e-316, 2.42711804e-316],
[ 1.85335328e-316, 1.85335328e-316]])
np.array###
如何将python原生的list对象转化为numpy的array呢
>>np.array([1,2,3,4])
array([1, 2, 3, 4])
np.arange###
numpy还提供了类似python的range方法
>>np.arange(1,5)
array([1, 2, 3, 4])
当然我们还可以设置迭代的步长
>>np.arange(1,5,0.5)
array([ 1. , 1.5, 2. , 2.5, 3. , 3.5, 4. , 4.5])
np.linspace###
该方法的作用是将一组值,以相同的间隔,迭代给定的次数
>>np.linspace(1,10,4)
array([ 1., 4., 7., 10.])
np.rand 和np.randn###
numpy提供了一系列的随机方法来随机初始化数组,下面是使用uniform distribution来随机初始化数组(取值范围[0,1])
>>np.random.rand(3,4)
array([[ 0.1017882 , 0.96519783, 0.899528 , 0.62844884],
[ 0.63758273, 0.71036901, 0.76895382, 0.41230372],
[ 0.31258595, 0.90595397, 0.44213312, 0.33604536]])
还可以使用normal distribution方法来初始化数组,均值为0、方差为1
>>np.random.randn(3,4)
array([[ 0.05971094, 1.57336808, -0.56372917, 1.58623654],
[-0.82797012, 0.19435163, 1.64495295, 0.07486049],
[-0.97815692, 1.4891987 , 0.65185811, -0.53984805]])
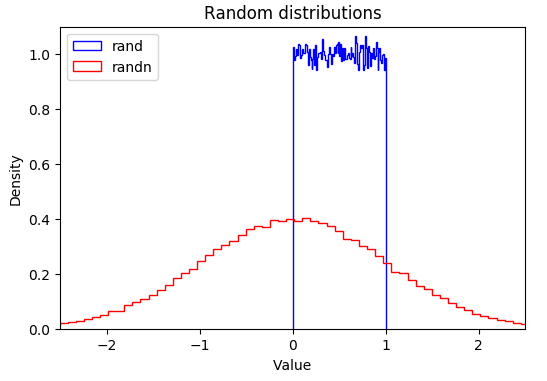
为了更加直观的表示上面的函数,将使用matplotlib将其绘制出来
import matplotlib.pyplot as plt
plt.hist(np.random.rand(100000), normed=True, bins=100, histtype="step", color="blue", label="rand")
plt.hist(np.random.randn(100000), normed=True, bins=100, histtype="step", color="red", label="randn")
plt.axis([-2.5, 2.5, 0, 1.1])
plt.legend(loc = "upper left")
plt.title("Random distributions")
plt.xlabel("Value")
plt.ylabel("Density")
plt.show()
np.fromfunction###
有些时候,单一的数组初始化方式不能满足我们的业务需求,这个时候我们就需要定制初始化规则,强大的numpy当然也会考虑到这一问题
def my_function(x,y,z):
return x * y + z
a = np.fromfunction(my_function, (2,3,4))
>>a
array([[[ 0., 1., 2., 3.],
[ 0., 1., 2., 3.],
[ 0., 1., 2., 3.]],
[[ 0., 1., 2., 3.],
[ 1., 2., 3., 4.],
[ 2., 3., 4., 5.]]])
上面得到的数组是怎么一个计算过程呢?首先numpy将数组种的坐标点带入自定义的函数种,例如右下角的5坐标点为(1,2,3)将其坐标代入自定义函数
数组中的数值##
dtype###
上一节将了使用numpy创建数组类型为ndarray,那么数组中的数据也有着自己的数据类型.
>>c = np.arange(1, 5)
c.dtype #int32
data buffer###
数组以一维度byte buffer存放在内存中,可以通过data属性来进行查看
先定义一个数组
>>f = np.array([[1,2],[1000, 2000]], dtype=np.int32)
f.data
<read-write buffer for 0x000000000BB03F30, size 16, offset 0 at 0x000000000C4DCEA0>
python2和3的查看方式不一样
if (hasattr(f.data, "tobytes")):
data_bytes = f.data.tobytes() # python 3
else:
data_bytes = memoryview(f.data).tobytes() # python 2
>>data_bytes
'\x01\x00\x00\x00\x02\x00\x00\x00\xe8\x03\x00\x00\xd0\x07\x00\x00'


 浙公网安备 33010602011771号
浙公网安备 33010602011771号