转载请注明出处:http://www.cnblogs.com/willnote/p/6912798.html
前言
深度学习的基本原理是基于人工神经网络,信号从一个神经元进入,经过非线性的激活函数,传入到下一层神经元;再经过该层神经元的激活,继续往下传递,如此循环往复,直到输出层。正是由于这些非线性函数的反复叠加,才使得神经网络有足够的能力来抓取复杂的模式,在各个领域取得不俗的表现。显而易见,激活函数在深度学习中举足轻重,也是很活跃的研究领域之一。目前来讲,选择怎样的激活函数不在于它能否模拟真正的神经元,而在于能否便于优化整个深度神经网络。
本文首先着重对Sigmoid函数的特点与其存在的梯度消失问题进行说明,之后再对其他常用的一些激活函数的特点进行对比介绍。
Sigmoid函数
Sigmoid函数是深度学习领域开始时使用频率最高的激活函数。
函数形式
\[\sigma (x)=\frac{1}{1+e^{-x}}
\]

梯度消失
- 梯度消失问题
首先,我们将一个使用Sigmoid作为激活函数的网络,在初始化后的训练初期结果进行可视化如下:
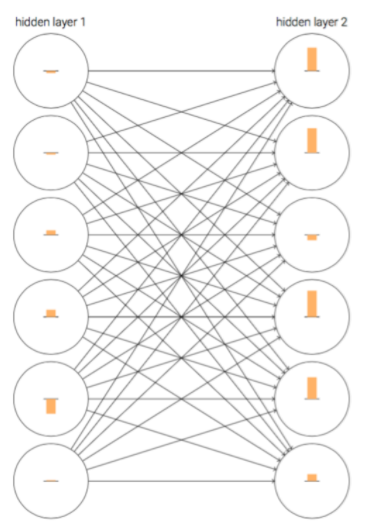
在上图中,神经元上的橙色柱条可以理解为神经元的学习速率。虽然这个网络是经过随机初始化的,但是从上图不难发现,第二层神经元上的柱条都要大于第一层对应神经元上的柱条,即第二层神经元的学习速率大于第一层神经元学习速率。那这可不可能是个巧合呢?其实不是的,Nielsen在《Neural Networks and Deep Learning》中通过实验说明了这种现象是普遍存在的。
接下来我们再来看下对于一个具有四个隐层的神经网络,各隐藏层的学习速率曲线如下:
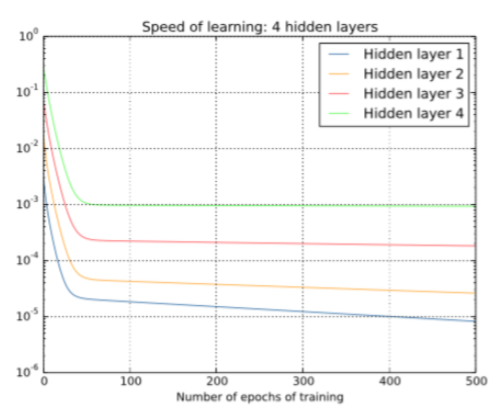
可以看出,第一层的学习速度和最后一层要差两个数量级,也就是比第四层慢了100倍。 实际上,这个问题是可以避免的,尽管替代方法并不是那么有效,同样会产生问题——在前面的层中的梯度会变得非常大!这也叫做梯度激增(exploding gradient problem),这也没有比梯度消散问题更好处理。
更加一般地说,在深度神经网络中的梯度是不稳定的,在前面的层中或会消失,或会激增,这种不稳定性才是深度神经网络中基于梯度学习的根本原因。
- 梯度消散的产生原因
为了弄清楚为何会出现梯度消散问题,来看看一个简单的深度神经网络:每一层都只有一个单一的神经元。下面就是有三层隐藏层的神经网络:

我们把梯度的整个表达式写出来:
$$\frac{\partial C }{\partial b_{1}}=\sigma^{'} (z_{1})w_{2}\sigma^{'} (z_{2})w_{3}\sigma^{'} (z_{3})w_{4}\sigma^{'} (z_{4})\frac{\partial C }{\partial a_{4}}$$
我们再来看一下Sigmoid函数导数的曲线:
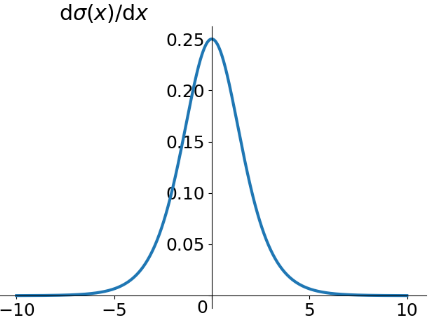
该导数在$\sigma^{'} (0)=\frac{1}{4}$时达到最高。现在,如果我们使用标准方法来初始化网络中的权重,那么会使用一个均值为0标准差为1的高斯分布。因此所有的权重通常会满足$|w_{j}|<1$。有了这些信息,我们发现会有$w_{j}\sigma^{'} (z_{j})<\frac{1}{4}$,并且在进行所有这些项的乘积时,最终结果肯定会指数级下降:项越多,乘积的下降也就越快。
下面我们从公式上比较一下第三层和第一层神经元的学习速率:

比较一下$\frac{\partial C }{\partial b_{1}}$和$\frac{\partial C }{\partial b_{3}}$可知,$\frac{\partial C }{\partial b_{1}}$要远远小于$\frac{\partial C }{\partial b_{3}}$。**因此,梯度消失的本质原因是:$w_{j}\sigma^{'} (z_{j})<\frac{1}{4}$的约束。**梯度激增问题:网络的权重设置的比较大且偏置使得$\sigma^{'} (z_{j})$项不会太小。
- 不稳定的梯度问题
根本的问题其实并非是梯度消失问题或者梯度激增问题,而是在前面的层上的梯度是来自后面的层上项的乘积。当存在过多的层次时,就出现了内在本质上的不稳定场景。唯一让所有层都接近相同的学习速度的方式是所有这些项的乘积都能得到一种平衡。如果没有某种机制或者更加本质的保证来达成平衡,那网络就很容易不稳定了。简而言之,真实的问题就是神经网络受限于不稳定梯度的问题。所以,如果我们使用标准的基于梯度的学习算法,在网络中的不同层会出现按照不同学习速度学习的情况。
zero-centered
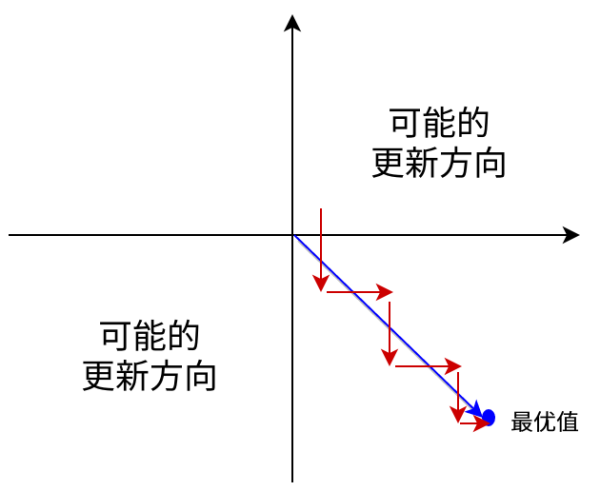
Sigmoid函数的输出值恒大于0,这会导致模型训练的收敛速度变慢。举例来讲,对\(\sigma (\sum w_{i}x{i}+b)\),如果所有\(x_{i}\)均为正数或负数,那么其对\(w_{i}\)的导数总是正数或负数,这会导致如下图红色箭头所示的阶梯式更新,这显然并非一个好的优化路径。深度学习往往需要大量时间来处理大量数据,模型的收敛速度是尤为重要的。所以,总体上来讲,训练深度学习网络尽量使用zero-centered数据 (可以经过数据预处理实现) 和zero-centered输出。
运算时耗
相对于前两项,这其实并不是一个大问题,我们目前是具备相应计算能力的,但面对深度学习中庞大的计算量,最好是能省则省。之后我们会看到,在ReLU函数中,需要做的仅仅是一个thresholding,相对于幂运算来讲会快很多。
tanh函数
tanh函数即双曲正切函数(hyperbolic tangent)。
函数形式
\[tanh x=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}
\]

评价
- 优点
解决了zero-centered的输出问题。
- 缺点
梯度消失的问题和幂运算的问题仍然存在。
ReLU函数
ReLU函数(Rectified Linear Units)其实就是一个取最大值函数,注意这并不是全区间可导的,但是我们可以取次梯度(subgradient)。
函数形式
\[ReLU=max(0, x)
\]
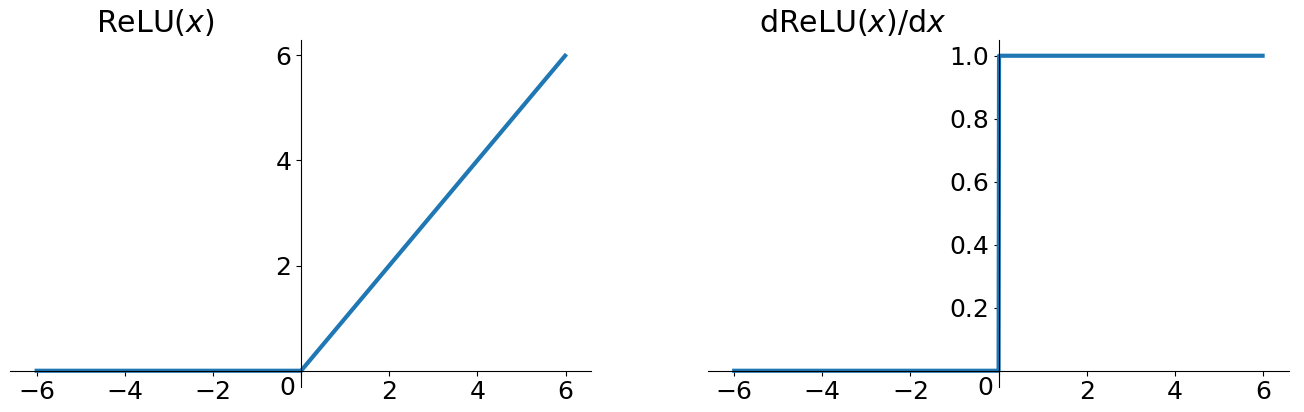
评价
- 优点
- 解决了梯度消失的问题 (在正区间)
- 计算速度非常快,只需要判断输入是否大于0
- 收敛速度远快于sigmoid和tanh
- 缺点
- 输出不是zero-centered
- Dead ReLU Problem
Dead ReLU Problem指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生: (1) 非常不幸的参数初始化,这种情况比较少见 (2) 学习速率太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将学习速率设置太大或使用adagrad等自动调节学习速率的算法。
尽管存在这两个问题,ReLU目前仍是最常用的激活函数,在搭建神经网络的时候推荐优先尝试!
Leaky ReLU函数
为了解决ReLU函数的Dead ReLU Problem而提出的激活函数。
函数形式
\[f(x)=max(0.01x, x)
\]
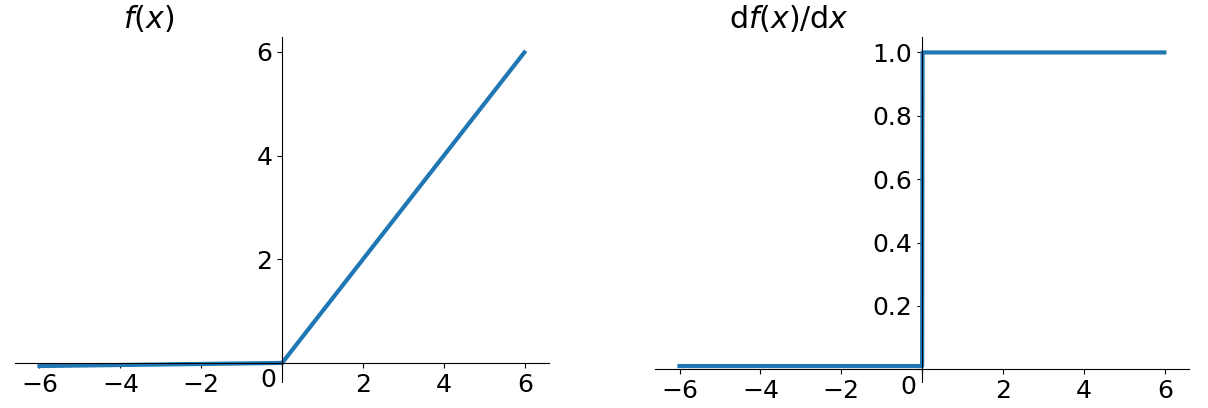
评价
为了解决Dead ReLU Problem,Leaky ReLU提出了将ReLU的前半段设为\(0.01x\)而非0。另外一种直观的想法是基于参数的方法,即Parametric ReLU:
\[f(x)=max(\alpha x, x)
\]
其中\(\alpha\)可由back propagation学出来。理论上来讲,Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是在实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。
ELU函数
ELU(Exponential Linear Units)函数也是为了解决ReLU存在的问题而提出的激活函数。
函数形式
\[\left\{\begin{matrix}x,\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ if\ x>0
\\ \alpha(e^{x}-1),\ \ \ \ \ \ otherwise
\end{matrix}\right.
\]
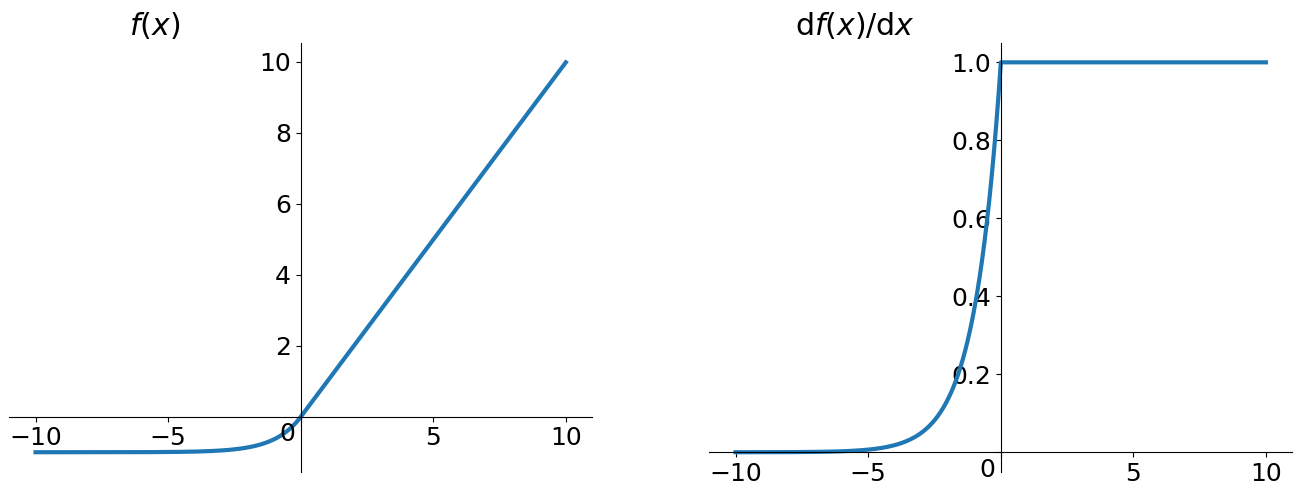
评价
ELU也是为解决ReLU存在的问题而提出,显然,ELU有ReLU的基本所有优点,以及:
- 不会有Dead ReLU问题
- 输出的均值接近0,zero-centered
它的一个小问题在于计算量稍大。类似于Leaky ReLU,理论上虽然好于ReLU,但在实际使用中目前并没有好的证据ELU总是优于ReLU。
参考
- 深度学习中消失的梯度
- 聊一聊深度学习的activation function



 浙公网安备 33010602011771号
浙公网安备 33010602011771号