

分布式文件快速搜索-设计与实现(开源/并行)
2010-07-20 08:50 灵感之源 阅读(5486) 评论(16) 收藏 举报
系列文章
2.分布式文件快速搜索的设计与实现(开源/分布式计算/并行)
特点
1.分布式:支持通过互联网查找任意多计算机,支持TCP/HTTP;
2.访问安全:基于角色的访问控制(RBAC),支持定义远程访问的账户、允许访问的目录等;
3.快速:
a).充分发挥多核CPU的性能,自动进行并行计算;
b).自动使用NTFS特性快速检索文件,比普通检索速度提升10倍以上;
4.智能:自动识别同一部机器上的不同物理磁盘,自动加速;
5.高效:哈希值、全文索引快速存取,网络压缩传输;
6.可扩展性内容搜索:内容匹配、全文索引,支持接口;
前世
这个程序的灵感,可以参考这里详细的说明:分布式文件快速搜索(多计算机并行/多种算法)
原来的目的只是查找本计算机的重复文件,因为3TB的磁盘空间,放了太多电影、图片、音乐,有不少是重复。刚开始,对每个文件内容都进行哈希值计算,速度非常慢。后来改成先用文件大小碰撞,碰撞后重复的几率就极大地减少了,然后再进行文件内容哈希,速度就有了巨大的提升。再后来,支持了文件名、文件时间和属性等过滤条件,可用性也增大了。
但是我不满足现有的速度,觉得现在的CPU都是多核的,我们可以使用多线程来充分利用多核的威力。单纯的多线程处理容易,new Thread就能跑了,但我们的目的是把大量的查找任务切割,分而治之,然后同时执行,并等待所有任务都完成再继续下一步工作,这就是并行计算的目的。
.NET 3.5 SP1开始有了Parallel Extensions,4.0内置了Parallel Processing Library(PPL),当然还有一系列的相关类,如ConcurrentDictionary等(终于解决了2.0引入的Dictionary不是线程安全需要自己手工封装的问题了)。有了这些,我们就可以进行并行计算了。
在引入了多线程检索文件之后,我还不满足现有的速度。经过分析,可以判断检索的文件是否在不同的物理磁盘(不是一个磁盘的不同分区),则可以在本机动态使用并行计算。
我还不满足目前的功能:局限于现有计算机,作为不大。日常工作,我们需要对不同的计算机进行搜索,当然,都是局域网内,我们可以映射网络磁盘。但如果是互联网上的计算机,你就无能为力了。所以就有了现在的网格文件快速搜索。
必须说明的是,网格文件快速搜索不是一个完整的软件,只是闲得头痛而拿来练手的实验性程序,目前能做的只是检索、删除相同/不同计算机上的文件。
今生
所谓网格,就是分布式,跟Web2.0所谓Tag就是分类一样,互联网包装的概念层出不穷。
要实现在不同的计算机之间检索文件,并聚合结果,我们需要做的工作颇多。首先,我参考了google的MapReduce。MapReduce,实际就是2个步骤,分配工作,然后聚合结果。在对多个计算机进行检索,就是分配多个任务,每个任务检索指定的计算机,等待所有检索任务完成,再聚合结果。
接着,我们需要对任务进行分配。分配的原则是远程按机器分组,本地按磁盘分组。在分配好任务之后,我们需要在每个计算机运行一个监听程序接受其它机器的请求。监听使用的是异步TCP,使用事件来通知程序进行业务处理。在监听程序运行后,客户端判断要检索的文件夹位于远程计算机,使用异步TCP连接,连接成功后,发送要检索的文件夹以及身份信息,在通过身份认证之后,便可以进行文件检索。当检索完成后,返回结果给请求端,请求端在所有计算机的检索都完成后,对结果进行组合。
如果远程计算机HTTP无法连接(如监听程序没有启动),会自动尝试TCP链接,如果仍然失败会自动容错并忽略。
现在,网格文件快速搜索正式成为了文件搜索,而不是以前的重复文件查找了。
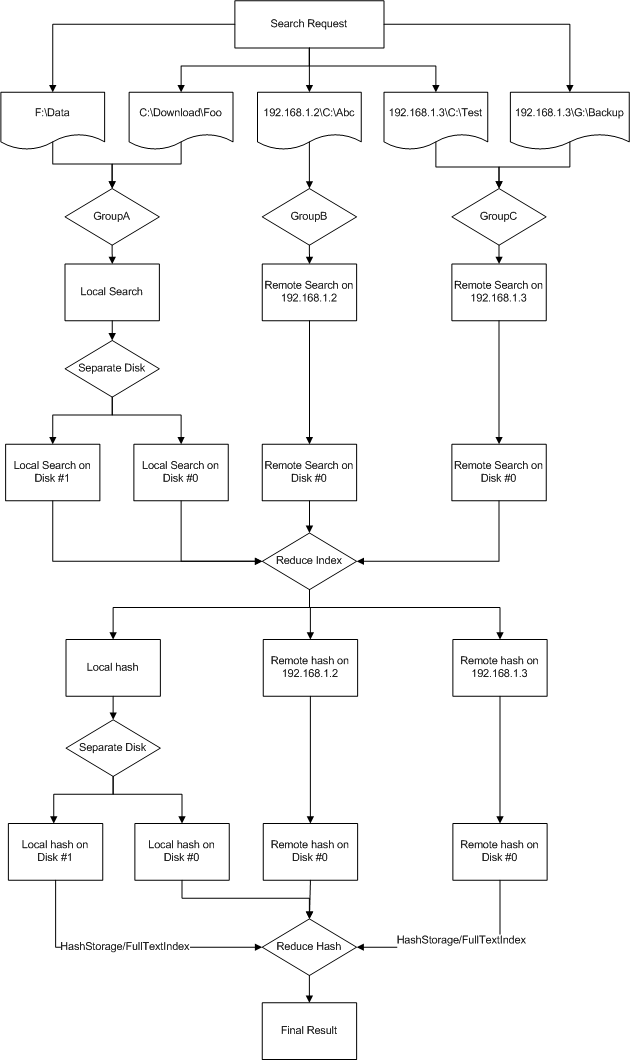
搜索流程
上述的步骤只是大概的过程,实际搜索流程要更复杂。整个搜索过程分2大步:第一步是根据文件的大小/名称/时间/属性等进行过滤,然后对存在相同的文件再进行文件内容哈希值判断。
对于互联网上的机器搜索,第一步必须返回所有搜索内容,而不是仅仅返回重复的内容,因为我们现在检索不是本地计算机,是多个互联网计算机,譬如计算机A存在文件1.jpg,计算机B也存在同样的1.jpg,但你必须把计算机A和B的结果聚合了才知道2个jpg文件相同,所以检索各个计算机的文件,第一次回返回所有文件信息,在结果返回聚合后,得出大小/名称/时间/属性相同的结果,再对这些文件进行文件内容哈希值处理。文件内容哈希值的处理过程跟文件属性检索类似,但是哈希值是以磁盘文件形式缓存了,每次获取文件内容哈希值之前,先判断文件的基本属性(文件名、大小、修改时间)是否与哈希数据库一致,如果匹配,使用数据库中的值,否则计算新的哈希值。
对于文件内容匹配,分3种情况:
1.完全匹配:使用哈希值判断,哈希值会在本地缓存;
2.内容包含:运行时判断;
3.全文索引:对可以抽取内容的文件进行动态索引,本地缓存;
全文索引支持接口扩展,目前内置了对微软的IFilter接口的实现,即将添加对lucene.net和hubbledotnet的支持。
具体流程看下图:
将来
你可以充分发挥想象力,把它应用到不同的领域。如果你应用了,记得告诉我,我会很高兴它能被别人使用。
TODO
使用
参看分布式文件快速搜索(多计算机并行/多种算法) 和下面的代码。
代码下载
点击这里下载:Filio.zip
实际使用,不需要V1*-V5*这些类,现在只是用来对比测试速度的,如果不测试,可以删除这些类。
项目地址
本项目已经在http://filio.codeplex.com/ 开源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号