20162330 2017-2018-1《程序设计与数据结构》第五周学习总结
2017-2018-1 学习总结目录: 1 2 3 5 6 7 9 10 11 12
目录
- 0. 教材学习内容总结
- 0.1 集合的介绍
- 0.2 栈集合
- 0.3 继承、多态和泛型
- 0.4 栈的ADT
- 0.5 使用栈:计算后缀表达式
- 0.6 异常
- 0.7 使用数组实现栈
- 0.8 ArrayStack类
- 0.9 将引用作为链
- 0.10 管理链表
- 0.11 没有链的元素
- 0.12 使用链实现栈
- 0.13 使用
java.util.Stack类实现栈- 0.14 包
- 分析Java Collections API中的Stack类
- 1. 教材学习中的问题和解决过程
- 1.1 ArrayStack类的expandCapacity方法
- 2. 代码调试中的问题和解决过程
- 2.1 LinkedStack类中的push方法
教材学习内容总结
集合的介绍
-
集合是 收集 并 组织 其他对象的对象。
-
分类:线性集合(排成一行)、非线性集合(层次、网络等方式组织)。
【推论】栈集合中元素的添加及删除都在一端进行,所以 栈集合属于线性集合。 -
集合中元素之间的组织方式取决于:
① 元素加入集合的次序;
② 元素之间的某些固有关系。 -
抽象数据类型:(abstract data type)简称ADT,其值和操作都没有被定义。(隐藏细节:集合)
-
数据结构:用来实现集合的基本程序结构集合。
-
Java Collections API:(application programming interface)使用不同方式实现的几类集合的一组类。(包含API)
栈集合
-
处理元素方式:LIFO(后进先出)
-
栈顶:元素入栈或出栈的一端。
在解决问题时,如果要访问非顶端元素,则不适合使用栈。
- 注意pop和peek操作的区别:pop为 删除 栈顶元素,peek为 查看 栈顶元素。
从单词上理解,pop有蹦出、离开之意,就相当于弹出了栈中元素;而peek有偷看之意,就相当于查看栈中元素。
继承、多态和泛型
-
类型兼容(多态)、类型检查(编译)。
-
泛型:(保存、操作、管理)直到实例化时才确定类型的对象。
栈的ADT
- 从伪代码中就能清楚地了解栈接口中的各个抽象方法:
public interface Stack<T>
{
// Adds the specified element to the top of the stack.
public void push (T element);
// Removes and returns the top element from the stack.
public T pop();
// Returns a reference to the top element of this stack without removing it.
public T peek();
// Returns true if this stack contains no elements and false otherwise.
public boolean isEmpty();
// Returns the number of elements in the stack.
public int size();
// Returns a string representation of the stack.
public String toString();
}
【注意】栈接口是用泛型 T 定义的,实现这个接口时,要用一个具体类型取代 T。
使用栈:计算后缀表达式
- 后缀表达式:<操作数> <操作数> <运算符>
后缀表达式不用考虑优先级和括号,比中缀表达式更易于计算。
- 栈是计算后缀表达式时使用的理想数据结构。
异常
-
潜在异常:
① 入栈时栈满;(数据结构)
② 出栈时栈空;(后缀表达式不正确)
③ 扫描完表达式完成计算时栈中的值多于1个。(后缀表达式不正确) -
处理异常的方式:
① 可以通过预先检查栈空以避免异常:
if (!theStack.isEmpty())
element = theStack.pop();
② 当异常发生时,使用 try-catch 语句处理:
try {
element = theStack.pop();
} catch (EmptyStackException exception) {
System.out.println("No elements available");
}
③ 先设置抛出异常,再自定义一个异常类:
public class EmptyCollectionException extends RuntimeException
{
/**
* Sets up this exception with an appropriate message.
* @param collection String representing the name of the collection
*/
public EmptyCollectionException (String collection)
{
super ("The " + collection + " is empty.");
}
}
使用数组实现栈
- 管理容量:需要时自动扩展。
ArrayStack类
-
数组实现的栈将栈底放在下标为 0 的位置。(顺序、连续)
-
关键代码:
不能实例化泛型数组,但是可以强制转换:stack = (T[]) (new Object[DEFAULT_CAPACITY]);
扩容时,先定义一个两倍原来容量的泛型数组,再将原来数组遍历赋值到新的数组里面去,在将新数组引用赋给原数组引用:
/**
* Creates a new array to store the contents of this stack with twice the capacity of the old one.
*/
private void expandCapacity() {
T[] larger = (T[]) (new Object[stack.length * 2]);
for (int index = 0; index < stack.length; index++)
larger[index] = stack[index];
stack = larger;
}
- 需要实现的方法:
//删除并返回栈顶元素
public T pop() {
T result = null; //置空临时变量的引用
if (!isEmpty()) { //确保栈不空
count--;
result = stack[count];
stack[count] = null;
} else
try {
isEmpty();
} catch (EmptyStackException exception) {
System.out.println("No elements available");
}
return result;
}
//返回栈顶元素的引用
public T peek() {
if (isEmpty()) {
try {
isEmpty();
} catch (EmptyStackException exception) {
System.out.println("No elements available");
}
}
return stack[count - 1];
}
public boolean isEmpty() {
return (count == 0);
}
public int size() {
return count;
}
- 注意 push 和 pop 操作的初始条件,push一个元素的前提是 栈不满,pop一个元素的前提是 栈不空。
将引用作为链
-
链式结构:使用对象引用变量建立联系。(自指示)
-
链表(对象之间指向关系)
结点(存储对象) -
注意:必须使用一个 单独的 引用变量指向表中第一个结点。结点的 next 引用为 null 时表示结束。
-
数组有固定大小,链表没有容量限制。
管理链表
-
访问元素:必须访问第一个元素。
-
插入结点:首先,新节点的 next 指向 current 指向的下一个结点,然后结束当前结点的 next 引用重置指向新节点。(头插法、尾插法、表中插入)

-
删除结点:第1个结点(将表头引用指向当前第2个结点)、中间节点(前一个的 next 指向当前结点的 next 引用所指向的结点)。

-
哨兵结点:不用考虑如何处理第1个结点。
没有链的元素
- 双向链表:维护第1个结点和最后一个结点。
使用链实现栈
- 注意初始时构造方法中将表头变量设置为 null,元素个数设置为 0。
//--------------------------------------------------------------------
// Creates an empty stack using the default capacity.
//--------------------------------------------------------------------
public LinkedStack() {
count = 0;
top = null;
}
- 需要实现的方法:
//删除并返回栈顶元素
public void push(T element) {
LinearNode<T> eNode = new LinearNode<>(element); //新元素入栈对应新的对象
eNode.setNext(top); //新结点next引用指向栈顶
top = eNode;
count++;
}
//返回当前栈顶所保存元素的引用
public T peek() throws EmptyStackException {
return top.getElement();
}
public boolean isEmpty() {
return count == 0;
}
public int size() {
return count;
}
- push、pop等操作的每个步骤都含有一次比较或者赋值,所以其复杂度都是O(1)。
使用 java.util.Stack 类实现栈
java.util.Stack类(扩展)派生于Vector类,但是有些功能违背了栈的假设。
包
-
包的组织:一般按代码功能组织为包(集合,异常)。
-
使用
package XXX声明引入的包。
分析Java Collections API中的Stack类
- 首先在API中Stack类的类声明语句
public class Stack<E> extends Vector<E>体现了其特性,而Vector又扩展了AbstractList类:
public class Vector<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
-
而该类又继承了其他方法,从而使得Stack类实现了List、Collection等接口:
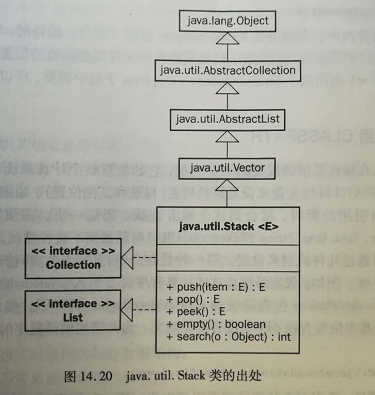
中文版API介绍Stack类说:
它通过五个操作对类 Vector 进行了扩展 ,允许将向量视为堆栈。它提供了通常的 push 和 pop 操作,以及取堆栈顶点的 peek 方法、测试堆栈是否为空的 empty 方法、在堆栈中查找项并确定到堆栈顶距离的 search 方法。
-
由于这个类依赖于 vector(向量),所以它既展示出 vector 的特性也展示出栈的特性。
相比起书中实现的栈,在Stack类中加入了一种特殊方法:search(返回对象在栈中的位置,即第一次出现时与栈顶之间的距离)public synchronized int search(Object o) { int i = lastIndexOf(o); if (i >= 0) { return size() - i; } return -1; }- 这个方法将对象o作为一个栈中的元素,先获取其位置,即最后一次出现(离栈顶最近)时的索引值,最小值为 1,如果此对象不存在或者检测对象为空值,则会返回 -1,举个例子:
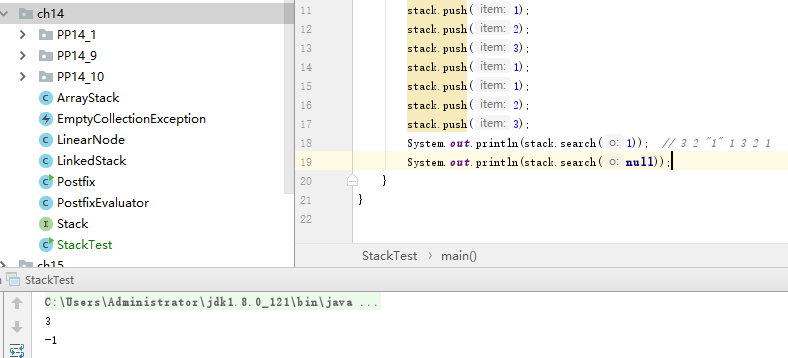
结果体现得很明显了。
- 这个方法将对象o作为一个栈中的元素,先获取其位置,即最后一次出现(离栈顶最近)时的索引值,最小值为 1,如果此对象不存在或者检测对象为空值,则会返回 -1,举个例子:
-
相比起书中实现的栈,除了额外提供了search方法之外,我还发现search、peek 和 pop 方法在声明时,public后出现了新的关键字
synchronized,它的功能是保证在同一时刻最多只有一个线程执行该段代码,就是说当两个并发线程访问同一个方法时,一个时间内只能有一个线程得到执行。另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块。对于synchronized 方法,更详细的解释是:synchronized 方法控制对类成员变量的访问,每个类实例都对应一把锁,每个 synchronized 方法都必须获得调用该方法的类实例的锁方能执行,否则所属线程阻塞,方法一旦执行,就独占该锁,直到从该方法返回时才将锁释放,此后被阻塞的线程方能获得该锁,重新进入可执行状态。这种机制确保了同一时刻对于每一个类实例,其所有声明为 synchronized 的成员函数中至多只有一个处于可执行状态。(因为至多只有一个能够获得该类实例对应的锁)
这样一来就可以避免类成员变量访问冲突,但如果为一些时间复杂度高的方法增加对象锁,就会明显降低其效率。
-
除此之外,由于Stack类是继承类,所以一些方法中的属性是从Vector类继承而来,比如说:pop方法
public synchronized E pop() { E obj; int len = size(); obj = peek(); removeElementAt(len - 1); return obj; }- 其中的
removeElementAt(int index)方法就是继承而来:
public synchronized void removeElementAt(int index) { modCount++; if (index >= elementCount) { //索引参数越界 throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount); } else if (index < 0) { //索引参数越界 throw new ArrayIndexOutOfBoundsException(index); } int j = elementCount - index - 1; if (j > 0) { System.arraycopy(elementData, index + 1, elementData, index, j); //元素后移 } elementCount--; //元素个数减1 elementData[elementCount] = null; //置空 }- 再看看peek方法:
public synchronized E peek() { int i = size(); if (i == 0) throw new EmptyStackException(); return elementAt(i - 1); }- 这里又调用了Vector中的
elementAt(int index)方法:
public synchronized E elementAt(int index) { if (index >= elementCount) { throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount); } return elementData(index); }- 和
removeElementAt(int index)方法一样,elementAt(int index)方法也首先判断参数是否合法,之后就直接调用elementData(int index)返回具体的对象值:
E elementData(int index) { return (E) elementData[index]; //保存Stack中的每个元素 } - 其中的
-
总的来说,Stack源码是通过数组实现的,再加上Vector中的扩容和其他方法属性,除此之外还使用了关键字
synchronized确保了线程安全,这应该就是其设计中的巧妙之处吧。
教材学习中的问题和解决过程
-
【问题】:ArrayStack类的expandCapacity方法中的
stack = larger代码不太明白它的意思,larger是新定义的泛型数组,其空间是原来 stack 数组的两倍,直接使用遍历后的新数组就可以了,为什么又将新容量的数组赋值给原来的 stack 数组? -
解决方案 :(询问后总结)
完整扩容方法如下:
private void expandCapacity() {
T[] larger = (T[]) (new Object[stack.length * 2]);
for (int index = 0; index < stack.length; index++)
larger[index] = stack[index];
stack = larger;
}
在创建新大小的泛型数组larger后,再将stack中的元素遍历进去,但是最后又要将larger赋给容量更小的stack。原来我以为stack是原来的引用,所以将larger数组赋给stack时就认为是将容量大数组的赋值给了一个容量小的数组,不能够实现。询问了张旭升之后,发现我对原stack引用理解有误,在给stack数组赋larger数组的时候,相当于更新了原数组,stack数组在被更新时就已经改变了默认的容量,从而实现扩容效果。
代码调试中的问题和解决过程
-
【问题】:在设计LinkedStack类中的push方法时,Junit测试出现红条,添加的元素并没有在删除时显示。

-
解决方案 :(尝试)
我最初设计方法时,仔细看了书中的文字步骤:
其中前两步比较重要:第一步是创建一个新结点,其中包含一个指向要放置到栈中对象的引用。接着设置新结点的 next 引用指向当前栈顶(如果栈为空,则它为null)
看完这两段话,原来我想要使用条件语句判断栈顶元素,但是仔细一想,如果栈顶元素为空,在给新结点赋值或者被新结点的引用指向时并不会因非空赋值语句造成影响,于是我的代码如下:
public void push(T element) {
LinearNode<T> eNode = new LinearNode<>();
eNode.setNext(top); //新结点指向栈顶
top = eNode;
count++;
}
但是在进行Junit测试时并没有成功,pop或者peek方法返回的值一直为空,在仔细看了第一条赋值语句后,发现我定义的结点中并没有传入push元素,所以就一直保持了栈默认为空的状态,所以只需要将传入的element加入即可:LinearNode<T> eNode = new LinearNode<>(element);
最初出现这个错误是因为忽略了泛型结点默认的初始值。
代码托管
- 统计的代码包含了第四周的实验一,所以是第四周和第五周一共的代码量:
(statistics.sh脚本的运行结果截图)

上周考试错题总结
-
上周国庆放假无考试,所以总结第三周的错题:
-
【错题1】A __________________ search looks through the search pool one element at a time.
A .binary
B .clever
C .insertion
D .selection
E .linear -
错误原因:我觉得二分查找每次也是搜索比较一个中间元素,错选A。
加深理解:线性查找会逐一在查找池中查找(迭代)一个元素;二分查找每次也在查找池中查找一个元素,但是并不是逐一,每次会筛选掉一半。
【注意】look through 在这里并不是浏览之意,而是 “逐一检查” 的意思。 -
【错题2】A linear search always requires more comparisons than a binary search.
A .true
B .false -
错误原因:考虑情况不全面,错选A。
加深理解:如果正在搜索的元素是列表中的第一个元素,那么线性查找比二分查找需要的比较次数更少。
结对及互评
本周结对学习情况
-
莫礼钟本周比第三周的状态好一点,虽然实验只完成了第一个和第五个,设计的方法比较简单,但是都是自己做的。在学习十四章的过程中,他已经基本掌握了如何使用数组实现栈,其中一些比较重要的方法(push、pop)我已经看着他写了一遍,希望多熟练已掌握的内容,并且再恢复一些学习状态。
-
- 结对学习内容
- 线性表
- 用数组实现栈(push、pop方法的实现)
- 结对学习内容
其他(感悟、思考等,可选)
本周算是比较忙的一周了,国庆之后的第一周并不轻松,除了运动会的一些杂事之外,本周的学习任务真心有点多。本周在课堂上我们又复习了查找与排序的内容,我的掌握情况还算过关,对于栈、队列这部分内容我选择了“先听课再看书”的方式。到现在为止,栈的基本内容掌握了,队列的掌握情况还差很多,云班课的测试成绩也不算高。本周我的状态有些下降,主要因为睡眠时间不足导致,下周我会将精力集中回来,并且平衡好完成团队任务和个人任务的时间。
-
【附1】教材及考试题中涉及到的英语:
Chinese English Chinese English 线性集合 linear collection 默认值 default 非线性集合 nonlinear collection 自指示 self-referential 封装 encapsulate 动态 dynamic 类型兼容 type compatibility 堆 heap 中缀 infix 哨兵结点 sentinel node 前缀 prefix 虚位结点 dummy node 矢量 vector 常量 constant(s) 操作数 operand(s) 指定的 designated 优化 optimize 空闲存储区 free store -
【附2】本周小组博客
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 234/234 | 1/28 | 14/14 | 了解算法效率、大O符号等理论内容 |
| 第二周 | 255/489 | 1/29 | 12/26 | 了解敏捷的团队、泛型的使用 |
| 第三周 | 436/925 | 2/31 | 10/36 | 了解一些查找和排序的算法 |
| 第四周 | 977/1902 | 3/34 | 10/46 | 掌握实现线性结构 |
| 第五周 | 800/2702 | 2/36 | 12/58 | 掌握实现栈集合 |
-
计划学习时间:14小时
-
实际学习时间:12小时
-
有效学习时间:5小时
-
改进情况:学习内容有所增加,本周我的效率极低,下周必须恢复到之前的状态,学习时务必心无旁骛。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号