

[译] 企业级 OpenStack 的六大需求(第 1 部分):API 高可用、管理和安全
全文包括三部分:
引言
OpenStack 是构造企业级私有云的非常理想的基础。它立志成为新一代云操作系统的内核。但是,目前它还不是一个完整的云操作系统。在它将来可能成为云操作系统之前,我们还是把它看做云操作系统的内核比较好。
目前,OpenStack 在一些关键领域还存在挑战,要应对这些挑战,OpenStack 需要通过健壮的企业级产品来交付。业界提供的这些产品,能提供支持、快速安装、日常管理工具和其它一些必要的东西。如果没有提供这些产品的厂商,OpenStack 将永远不会广泛地被采用。OpenStack 不是 MySQL。它类似 Linux 内核,正如Linux 内核一样,你需要一个完整的操作系统才能运行它。那企业级 OpenStack 到底需要什么呢?有以下六个关键的因素:
- 99.999% 的 API 可用性以及可扩展的控制平面
- 健壮的管理和安全模型
- 开放的架构
- 混合云兼容性
- 可扩展的弹性架构
- 全面的支持和服务

如果你们公司需要一个企业级OpenStack 方案,请继续阅读下去,看看一个真正的企业级私有云能够和应该提供什么。接下来两周,我会写包括多个部分的一系列博客 “企业级 OpenStack 的6大需求”。首先让我们看看企业中 OpenStack 所处的位置开始吧。
企业数据中心中的OpenStack
敏捷是云的一个新的关键词,而 DevOps 被看作实现敏捷的必由之路。正如 Linux 向 Web 应用提供了新的平台一样,OpenStack 向在企业内部及时交付开发人员的产出提供了一个理想的平台。如果 OpenStack 仅仅是“便宜的 VMware”,那么它对企业来说就没多大的价值了。相反,OpenStack 提供了一个非常好的有关如何来打造类似于主要公有云比如亚马逊(AWS)和 Google Cloud Platform(GCP)的弹性私有云的样板。就像 Hadoop 将 Google的 MapReduce (加上它的参考架构)推向大众一样,OpenStack 将 AWS/GCP 式样的的基础架构即服务(IaaS)推向了每个用户。它就是能实现企业内部 DevOps 的终极平台。
关于 DevOps 的任何讨论,往往很快就会限于语义学争论的泥潭。然而,我们都认可的是,介于应用开发者和IT基础架构运维人员之间的障碍必须被移除。一次又一次,我从几个客户那里都听到一个大致相同的故事:“我们带着我们新应用的长长的需求清单去找我们的基础设施运维团队。 他们告诉我,部署这个应用需要18个月的时间和 $10M 的费用。于是我们就去了亚马逊的网站。我们无法让他们针对我们的应用做什么定制,因此我们不得不改变我们的应用模型,但是我们马上就将它发布出去了”。这是因为,亚马逊的内在价值和成本其实没多少关系,而是更多的与能立即响应需求的、弹性的、以开发者为中心的交付模型有关。
OpenStack 能在企业内部提供类似的平台。私有云可以基于公有云模型来构造,使得开发者同时拥有集中式 IT 控制和支配。本质上,它是两者融合的最佳平台,这也是OpenStack驱动的私有云的真正价值。
为什么敏捷如此重要呢?
我觉得这是显而易见的,敏捷是驱动云计算的原动力。商务需求的快速演进,已经驱动AWS获得了不可思议的增长:

这些增长全部是新的网络应用,或者微软说的下一代应用。这些新的应用的绝大部分是在聚焦于全新的商业价值,典型地包括移动、社交、网站应用和大数据等。实际上,这种类型的应用的增长是如此快速,以至于 IDC 和 Gartner 都已经开始跟踪它们了:
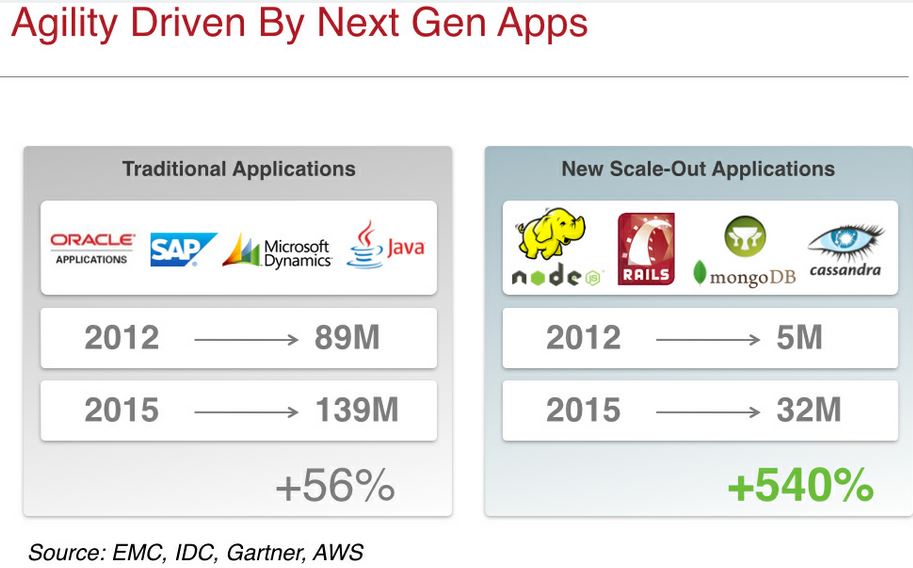
按照这个增长速度,新一代的应用在2018年就会和传统应用在数量上持平了:

需求1 - 99.999%可用的控制平面:有高可靠性要求的应用需要高可靠的云API
继续我们围绕企业级 OpenStack 进行讨论,我们来讨论一下 API 可用性是多么的关键,以及交付下一代应用是如何需要扩展云控制平面的。
云 API 的可用性
向全新的云和 DevOps 模型转型的一个关键能力是提供云原生应用在弹性云中的容错能力。这些应用知道,任何服务器、磁盘、网络设备随时都可能出错。它们及时检测这些错误,并且做出实时响应。这正是亚马逊和 GCP 如何工作的,以及为什么他们可以以更低的成本但是更高的灵活性来运行这些服务。要使一个应用能实时地适应不同组件的出错,云 API 需要有更高的可用性。
你的云控制面板的吞吐量
API 的可用性不是唯一的衡量标准。你的云控制平面的吞吐量(throughoutput)同样关键。可以将控制平面想象成云的指挥中枢。这是中央智能和编排层的核心。你的 API 是控制平面的一部分,对于 OpenStack 来说,包括所有的核心项目,以及日常的云管理系统(通常是 OpenStack 企业级套件的一部分),以及所有必要的辅助服务,比如数据库、OpenStack 各厂商插件等等。你的云的控制平面必须能够随着云的增长而增长。这意味着,总体上,你将会获得更多的API操作的吞吐量(对象上传/下载、镜像上传/下载、元数据更新等待)。
而这正是一个云操作系统需要提供的。
99.99% 的 API 可用性和控制平面的扩展性
本质上讲,在 99.5% SLA的基础架构上,如果要运行 99.99-99.999% SLA 的应用的话,应用所需要使用的云 API 也需要有99.99-99.999%的 SLA。其实你知道,交付5个9可用性的API 可不容易,因为它只允许每年有5.26分钟的非计划停止运行时间。传统的高可用方法,比如主/备或者多主选举系统,往往需要几分钟的时间来做故障切换,这期间你的 API 端点(endpoint)是不可用的。
一个企业级的云操作系统能提供分钟内的甚至秒级的故障切换,来保证 99.999%甚至 99.9999% (6个9意味着每年只有 31.5 秒的停止服务时间)的可用性。设计上,在相对较低的成本上,使用经典的负载均衡技术,你的云控制平面和 API 以 N 个主的方式运行,是可以达到这种可用性的。这里的 N 就是随着云的增长而需要的数目: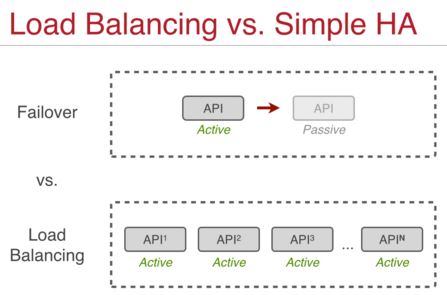
这让我想到了等式的另一头:你需要你的云控制平面随着你的云的增长而增长。你不希望在云增长时重构你的系统,你也不希望使用老的方法来扩展你的 API 端点。当你的系统使用主/备或者多主选举的高可用方案时,其实每个时刻只有一个API端点可用。这意味着那个正在提供服务的服务器将是系统的瓶颈,而这是今天可扩展云的世界里所不能接受的。
相反,使用负载均衡模式,你可以运行多主的活动 API 端点,扩展你的控制平面,同时达到高可用。这是最佳的方式,可以使得你的云原生应用具有实时的容错能力。
现在我们来谈谈日常的云管理和云安全。
需求2 - 健壮的管理:管理和保证云安全是需要成本的(Managing and Securing Your Cloud is Not Free)
也许你已经了解到这一点,可是在企业内部打造一个健壮的、可管理的、安全的基础设施是非常困难的。那种认为私有云可以在下午构建好,晚上就可以投入生产的观点是不对的,是和数据中心实际情况不合乎的。因此,如果你想要你的云在将来能平稳地运转,同时你又想要它交付得非常快速,那么你选择一个已经被设计为能够快速部署、日常管理和安全的 OpenStack 版本将对你有帮助。让我们接着更深入些地探讨这个问题。
健壮的管理
安装只是管理 OpenStack 的开端。一个真正的云操作系统将提供一个从设计上就能保证基础设施团队能成功交付服务的以运维为核心的云管理工具套件。这些管理工具将提供:
- 可重用的架构模型,通常使用参考网络架构将小集群(pod)或者组(block)连接在在一起
- 初始云安装和部署
- 典型的日常云运维工具,包括日志、系统测量值和相关度分析
- 供云运维人员使用的用来做整合和自动化的 CLI 和 API
- 用于可视化和分析的云运维图形界面
很多厂商想解决私有云系统管理挑战的尝试都只停留在安装上了。安装只是一个长长过程的开端,如果你的云的日常管理很麻烦,那么无论它的安装是多么容易,它都将不怎么重要。我们都知道,运行一个生产系统通常是不容易的。实际上,在许多方面,私有云都比传统的基础设施更复杂。为了简化这种复杂性,从规模上,象 Google 和亚马逊这些云先锋都已经采用使用基于多个小集群(pod)、集群(cluster)或者块(block)的方式去设计、部署和管理他们的云。Google 使用多集群;Facebook 使用多个三重组;但是其实它们本质上是相同的:以类似乐高积木的可重复的方式来构造云和数据中心。企业级 OpenStack 驱动的云操作系统将需要类似的方式来组织云。
云安装好并运行起来以后,云运维人员需要大量的工具来做运维,包括事件日志和系统监测等等。确实,在一个弹性云中,过去往往非常关键的事件已经不是高优先级了(比如服务器或者交换机故障)。然后,你的云不能是个黑盒子。你需要它是如何天复一天地运行的有关数据和信息,这样你就可以在需要的时候解决特定的问题,更重要的是,使用相关性分析工具来监测反复发生的问题。单个的一个服务器故障不是什么大问题,但是,在大量设备上出现的任何常见问题,都是需要快速定位和解决的。
那你的云如何运作的呢?不仅你自己需要知道,你的各种工具也需要知道。整合到已有的系统对云来说非常关键。任何完善的解决方案都会提供 API 和 CLI 供你做整合和自动化。只是用于 OpenStack 管理需要的 CLI 和 API 是不够的。如果管理你的物理服务器集群和单元?如何做到不仅从OpenStack,还要从 Linux 和其它非OpenStack 应用中按需获取系统检测数据和日志数据?你需要一个单一的统一的接口来做云运维和管理。显然,如果你有这种 API,还需要提供 GUI 来便于查看系统内的各种样式和网络检测数据。
安全模型
云的安全模型非常重要。要完整地讨论这个主题,远远不是这个文章所能涵盖的,但是有一个事情需要清楚:企业需要云有一个可以理解的安全模型,特别是对控制平面而言。就像我前面所阐述的那样,你的云控制平面的API可用性和吞吐量对下一代应用的容错性非常关键,同样的,你的云控制平面的安全性不能简单地想当然。
你可以很容易地转型到去中心化模型,但是,去中心化和扩展性不是一回事。你完全可以混用中心化和扩展技术,正如 Google 所采用的方式。将你的云控制平面放在一个地方会让你:
- 只需要去一个地方去定位错误
- 永远不用靠猜来确定你的控制平面的位置
- 应用安全策略/域到你的云控制平面
- 保持你的控制平面数据和数据平面数据完全分离
其中,最后一点可能是最重要的。你不会将你的 OpenStack 数据库和虚机放在同一个存储系统上。假如有人突破 Hypervisor 进入虚机会怎么样呢?或者,相反,如果有人突破 API 进入了控制平面又会怎么样?
企业内的最优做法是,将不同的组件分到不同的安全域(通常使用多个VLAN),然后对不同的安全域配置不同的安全策略。分区域会延缓黑客的入侵,让你有时间探测到它们,然后做出响应。在你的私有云安全模型中使用类似的模型,对于确保你的云安全非常关键。
云管理和安全
就像我前面说的那样,你的云历程从安装开始。然后,你需要一系列的工具和安全模型,来使你能非常自信地日常管理你的云。一个OpenStack驱动的企业级云操作系统需要尽可能多地提供这些能力。
部分1总结
OpenStack 是为下一代应用搭建下一代私有云的强大的基础。只是,目前它还不是一个完整的云操作系统,你需要有合作伙伴来提供完整的方案。这系列的日志会阐述企业级OpenStack私有云的6大需求,而今天我谈到了高可用的,可扩展的控制平面,以及健壮的安全管理工具。
下一文章中,我会谈到围绕开放的架构和减少厂商锁定。然后,会阐述扩展性和性能,以及如何选择提供全面服务和支持的合作伙伴。
原文:The 6 Requirements of Enterprise-grade OpenStack,Posted on Apr 28, 2014 by

 浙公网安备 33010602011771号
浙公网安备 33010602011771号