机器学习(Andrew Ng)作业代码(Exercise 5~6)
Programming Exercise 5: Regularized Linear Regression and Bias v.s. Variance
linearRegCostFunction
与Ex4类似,没什么好说的
function [J, grad] = linearRegCostFunction(X, y, theta, lambda)
%LINEARREGCOSTFUNCTION Compute cost and gradient for regularized linear
%regression with multiple variables
% [J, grad] = LINEARREGCOSTFUNCTION(X, y, theta, lambda) computes the
% cost of using theta as the parameter for linear regression to fit the
% data points in X and y. Returns the cost in J and the gradient in grad
% Initialize some useful values
m = length(y); % number of training examples
% You need to return the following variables correctly
J = 0;
grad = zeros(size(theta));
% ====================== YOUR CODE HERE ======================
% Instructions: Compute the cost and gradient of regularized linear
% regression for a particular choice of theta.
%
% You should set J to the cost and grad to the gradient.
%
theta2=theta;
theta2(1)=0;
J=((X*theta-y)'*(X*theta-y))/(2*m)+lambda*(theta2'*theta2)/(2*m);
grad=(X'*(X*theta-y))/m+(lambda/m)*theta2;
% =========================================================================
grad = grad(:);
end
learningCurve
绘制出不同训练样本数目下,训练集误差和验证集误差
注意在计算训练样本数目为size的训练集误差时,只需要计算前size个训练集的样本的误差即可。
function [error_train, error_val] = ...
learningCurve(X, y, Xval, yval, lambda)
%LEARNINGCURVE Generates the train and cross validation set errors needed
%to plot a learning curve
% [error_train, error_val] = ...
% LEARNINGCURVE(X, y, Xval, yval, lambda) returns the train and
% cross validation set errors for a learning curve. In particular,
% it returns two vectors of the same length - error_train and
% error_val. Then, error_train(i) contains the training error for
% i examples (and similarly for error_val(i)).
%
% In this function, you will compute the train and test errors for
% dataset sizes from 1 up to m. In practice, when working with larger
% datasets, you might want to do this in larger intervals.
%
% Number of training examples
m = size(X, 1);
% You need to return these values correctly
error_train = zeros(m, 1);
error_val = zeros(m, 1);
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to return training errors in
% error_train and the cross validation errors in error_val.
% i.e., error_train(i) and
% error_val(i) should give you the errors
% obtained after training on i examples.
%
% Note: You should evaluate the training error on the first i training
% examples (i.e., X(1:i, :) and y(1:i)).
%
% For the cross-validation error, you should instead evaluate on
% the _entire_ cross validation set (Xval and yval).
%
% Note: If you are using your cost function (linearRegCostFunction)
% to compute the training and cross validation error, you should
% call the function with the lambda argument set to 0.
% Do note that you will still need to use lambda when running
% the training to obtain the theta parameters.
%
% Hint: You can loop over the examples with the following:
%
% for i = 1:m
% % Compute train/cross validation errors using training examples
% % X(1:i, :) and y(1:i), storing the result in
% % error_train(i) and error_val(i)
% ....
%
% end
%
% ---------------------- Sample Solution ----------------------
% -------------------------------------------------------------
for sample_size=1:m
[theta] = trainLinearReg([ones(sample_size, 1),X(1:sample_size,:)], y(1:sample_size), lambda);
[error_train(sample_size),~]=linearRegCostFunction([ones(sample_size,1),X(1:sample_size,:)],y(1:sample_size),theta,0);
[error_val(sample_size),~]=linearRegCostFunction([ones(size(Xval,1),1),Xval],yval,theta,0);
end
% =========================================================================
end
polyFeatures
将样本一维的特征x映射到p维的特征\((x,x^2,\cdots,x^p)\),从而将线性回归问题转化为多项式回归问题,用高阶的多项式函数拟合数据。
function [X_poly] = polyFeatures(X, p)
%POLYFEATURES Maps X (1D vector) into the p-th power
% [X_poly] = POLYFEATURES(X, p) takes a data matrix X (size m x 1) and
% maps each example into its polynomial features where
% X_poly(i, :) = [X(i) X(i).^2 X(i).^3 ... X(i).^p];
%
% You need to return the following variables correctly.
X_poly = zeros(numel(X), p);
% ====================== YOUR CODE HERE ======================
% Instructions: Given a vector X, return a matrix X_poly where the p-th
% column of X contains the values of X to the p-th power.
%
%
for pw=1:p
X_poly(:,pw)=X.^pw;
end
% =========================================================================
end
validationCurve
绘制在不同\(\lambda\)取值下,线性回归模型在训练集和验证集上的误差。这里输入样本被映射到八阶特征\((x,x^2,\cdots,x^8)\)
function [lambda_vec, error_train, error_val] = ...
validationCurve(X, y, Xval, yval)
%VALIDATIONCURVE Generate the train and validation errors needed to
%plot a validation curve that we can use to select lambda
% [lambda_vec, error_train, error_val] = ...
% VALIDATIONCURVE(X, y, Xval, yval) returns the train
% and validation errors (in error_train, error_val)
% for different values of lambda. You are given the training set (X,
% y) and validation set (Xval, yval).
%
% Selected values of lambda (you should not change this)
lambda_vec = [0 0.001 0.003 0.01 0.03 0.1 0.3 1 3 10]';
% You need to return these variables correctly.
error_train = zeros(length(lambda_vec), 1);
error_val = zeros(length(lambda_vec), 1);
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to return training errors in
% error_train and the validation errors in error_val. The
% vector lambda_vec contains the different lambda parameters
% to use for each calculation of the errors, i.e,
% error_train(i), and error_val(i) should give
% you the errors obtained after training with
% lambda = lambda_vec(i)
%
% Note: You can loop over lambda_vec with the following:
%
% for i = 1:length(lambda_vec)
% lambda = lambda_vec(i);
% % Compute train / val errors when training linear
% % regression with regularization parameter lambda
% % You should store the result in error_train(i)
% % and error_val(i)
% ....
%
% end
%
%
m=size(X,1);
mval=size(Xval,1);
for i=1:size(lambda_vec)
lambda=lambda_vec(i);
[theta] = trainLinearReg([ones(m, 1),X], y, lambda);
[error_train(i),~]=linearRegCostFunction([ones(m,1),X],y,theta,0);
[error_val(i),~]=linearRegCostFunction([ones(mval,1),Xval],yval,theta,0);
end
% =========================================================================
end
最终测试结果
Fig 1.不同训练样本数目下,线性回归模型(使用原始输入数据的特征)在训练集和测试集上的误差。
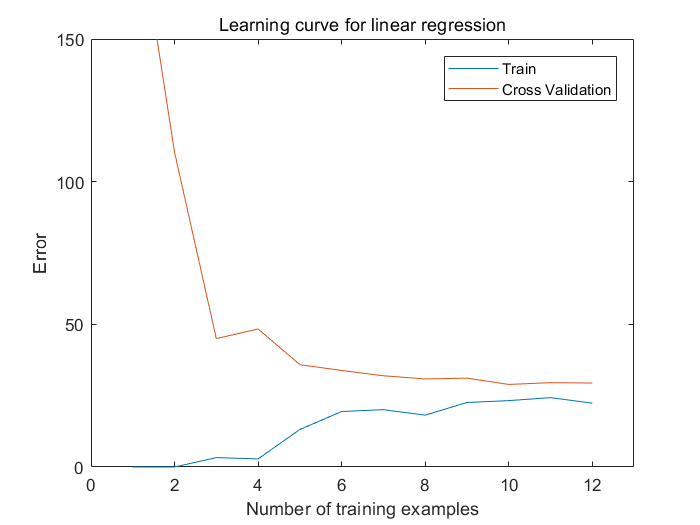
Fig 2.\(\lambda=1\)和100时,线性回归模型(特征映射到八阶)拟合出的曲线,以及在训练集和测试集上的误差。

Fig 3.线性回归模型(特征映射到八阶)在不同\(\lambda\)取值下在训练集和测试集上的误差。

Programming Exercise 6: Support Vector Machines
实现带高斯核的SVM
gaussianKernel
实现一个函数,给出两个向量\(x_1,x_2\),高斯核参数\(\sigma\),返回高斯核的相似度量(similarity metric):
function sim = gaussianKernel(x1, x2, sigma)
%RBFKERNEL returns a radial basis function kernel between x1 and x2
% sim = gaussianKernel(x1, x2) returns a gaussian kernel between x1 and x2
% and returns the value in sim
% Ensure that x1 and x2 are column vectors
x1 = x1(:); x2 = x2(:);
% You need to return the following variables correctly.
sim = 0;
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to return the similarity between x1
% and x2 computed using a Gaussian kernel with bandwidth
% sigma
%
%
sim=exp(-(x1-x2)'*(x1-x2)/(2*sigma*sigma));
% =============================================================
end
dataset3Params
给出训练集\((X,y)\),交叉验证集\((Xval,yval)\),在[0.01,0.03,0.1,0.3,1,3,10,30]中选取最合适的SVM参数\(\sigma,C\),使得用训练集训练好的SVM在交叉验证集中的错误率最低
function [C, sigma] = dataset3Params(X, y, Xval, yval)
%EX6PARAMS returns your choice of C and sigma for Part 3 of the exercise
%where you select the optimal (C, sigma) learning parameters to use for SVM
%with RBF kernel
% [C, sigma] = EX6PARAMS(X, y, Xval, yval) returns your choice of C and
% sigma. You should complete this function to return the optimal C and
% sigma based on a cross-validation set.
%
% You need to return the following variables correctly.
C = 1;
sigma = 0.3;
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to return the optimal C and sigma
% learning parameters found using the cross validation set.
% You can use svmPredict to predict the labels on the cross
% validation set. For example,
% predictions = svmPredict(model, Xval);
% will return the predictions on the cross validation set.
%
% Note: You can compute the prediction error using
% mean(double(predictions ~= yval))
%
Clist=[0.01,0.03,0.1,0.3,1,3,10,30];
sigmalist=[0.01,0.03,0.1,0.3,1,3,10,30];
minerror=1e18;
for i=1:length(Clist)
for j=1:length(sigmalist)
Cnow=Clist(i);
sigmanow=sigmalist(j);
% Train the SVM
model= svmTrain(X, y, Cnow, @(x1, x2) gaussianKernel(x1, x2, sigmanow));
p=svmPredict(model,Xval); %The predictions of SVM model
error=mean(double(p~=yval));
if(error<minerror)
minerror=error;
C=Cnow,sigma=sigmanow;
end
end
end
% =========================================================================
end
最终测试结果
Fig 1.c=1,c=100时使用不带核函数(线性核)的SVM划分同一组数据的决策边界,可见c=100时虽然没有数据被错误分类,但是决策边界与正、负样本的距离太近,发生了过拟合
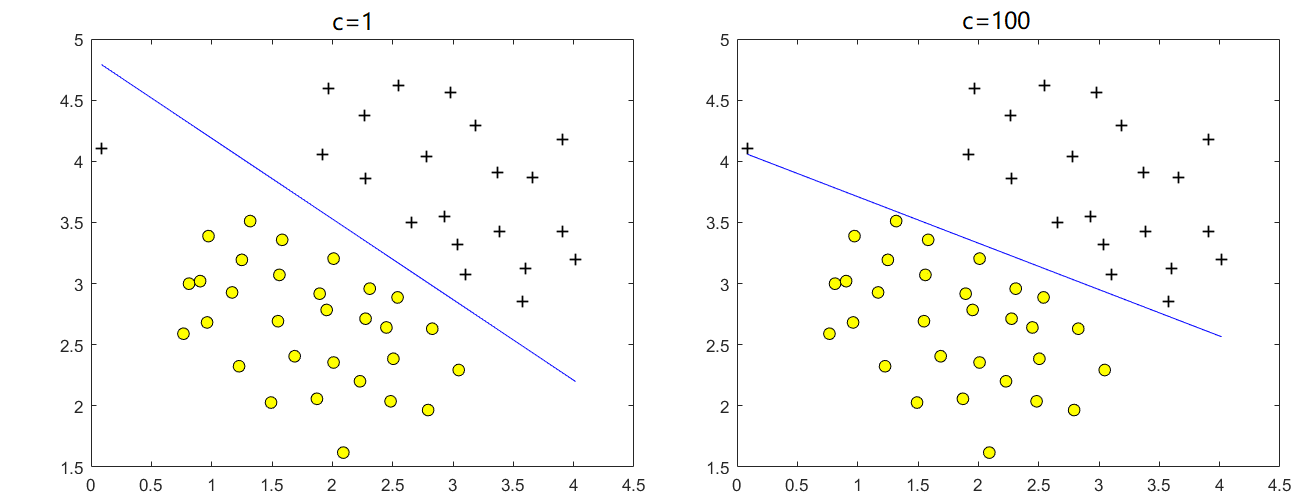
Fig 2.c=1时用高斯核的SVM划分第二组数据的决策边界
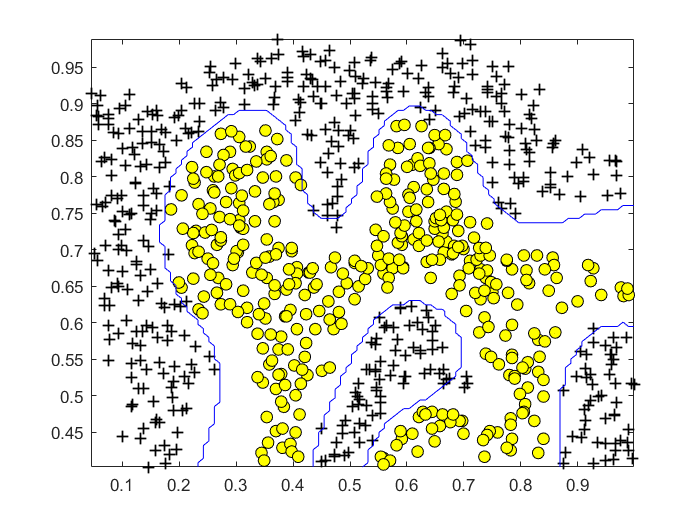
Fig 3.用自动选取的参数\(c,\sigma\),高斯核的SVM划分第三组数据的决策边界

用SVM实现垃圾邮件过滤器
processEmail
给出一封邮件的内容,将其预处理,提取出其中在词表里的所有词
作业代码已经实现了提取邮件内容中每个关键词str的部分,对于每个str,只需用strcmp与词表里的所有词一一比对即可。
function word_indices = processEmail(email_contents)
%PROCESSEMAIL preprocesses a the body of an email and
%returns a list of word_indices
% word_indices = PROCESSEMAIL(email_contents) preprocesses
% the body of an email and returns a list of indices of the
% words contained in the email.
%
% Load Vocabulary
vocabList = getVocabList();
% Init return value
word_indices = [];
% ========================== Preprocess Email ===========================
% Find the Headers ( \n\n and remove )
% Uncomment the following lines if you are working with raw emails with the
% full headers
% hdrstart = strfind(email_contents, ([char(10) char(10)]));
% email_contents = email_contents(hdrstart(1):end);
% Lower case
email_contents = lower(email_contents);
% Strip all HTML
% Looks for any expression that starts with < and ends with > and replace
% and does not have any < or > in the tag it with a space
email_contents = regexprep(email_contents, '<[^<>]+>', ' ');
% Handle Numbers
% Look for one or more characters between 0-9
email_contents = regexprep(email_contents, '[0-9]+', 'number');
% Handle URLS
% Look for strings starting with http:// or https://
email_contents = regexprep(email_contents, ...
'(http|https)://[^\s]*', 'httpaddr');
% Handle Email Addresses
% Look for strings with @ in the middle
email_contents = regexprep(email_contents, '[^\s]+@[^\s]+', 'emailaddr');
% Handle $ sign
email_contents = regexprep(email_contents, '[$]+', 'dollar');
% ========================== Tokenize Email ===========================
% Output the email to screen as well
fprintf('\n==== Processed Email ====\n\n');
% Process file
l = 0;
while ~isempty(email_contents)
% Tokenize and also get rid of any punctuation
[str, email_contents] = ...
strtok(email_contents, ...
[' @$/#.-:&*+=[]?!(){},''">_<;%' char(10) char(13)]);
% Remove any non alphanumeric characters
str = regexprep(str, '[^a-zA-Z0-9]', '');
% Stem the word
% (the porterStemmer sometimes has issues, so we use a try catch block)
try str = porterStemmer(strtrim(str));
catch str = ''; continue;
end;
% Skip the word if it is too short
if length(str) < 1
continue;
end
% Look up the word in the dictionary and add to word_indices if
% found
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to add the index of str to
% word_indices if it is in the vocabulary. At this point
% of the code, you have a stemmed word from the email in
% the variable str. You should look up str in the
% vocabulary list (vocabList). If a match exists, you
% should add the index of the word to the word_indices
% vector. Concretely, if str = 'action', then you should
% look up the vocabulary list to find where in vocabList
% 'action' appears. For example, if vocabList{18} =
% 'action', then, you should add 18 to the word_indices
% vector (e.g., word_indices = [word_indices ; 18]; ).
%
% Note: vocabList{idx} returns a the word with index idx in the
% vocabulary list.
%
% Note: You can use strcmp(str1, str2) to compare two strings (str1 and
% str2). It will return 1 only if the two strings are equivalent.
%
for i=1:length(vocabList)
if(strcmp(str,vocabList(i)))
word_indices=[word_indices;i];
break;
end
end
% =============================================================
% Print to screen, ensuring that the output lines are not too long
if (l + length(str) + 1) > 78
fprintf('\n');
l = 0;
end
fprintf('%s ', str);
l = l + length(str) + 1;
end
% Print footer
fprintf('\n\n=========================\n');
end
emailFeatures
将processEmail对邮件原始内容提取出的词表关键词,转换为一个向量\(x\),\(x(i)=1\)表示词表里第i个词在邮件中出现了,为0表示词表里第i个词没有出现
很容易实现,具体看代码
function x = emailFeatures(word_indices)
%EMAILFEATURES takes in a word_indices vector and produces a feature vector
%from the word indices
% x = EMAILFEATURES(word_indices) takes in a word_indices vector and
% produces a feature vector from the word indices.
% Total number of words in the dictionary
n = 1899;
% You need to return the following variables correctly.
x = zeros(n, 1);
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to return a feature vector for the
% given email (word_indices). To help make it easier to
% process the emails, we have have already pre-processed each
% email and converted each word in the email into an index in
% a fixed dictionary (of 1899 words). The variable
% word_indices contains the list of indices of the words
% which occur in one email.
%
% Concretely, if an email has the text:
%
% The quick brown fox jumped over the lazy dog.
%
% Then, the word_indices vector for this text might look
% like:
%
% 60 100 33 44 10 53 60 58 5
%
% where, we have mapped each word onto a number, for example:
%
% the -- 60
% quick -- 100
% ...
%
% (note: the above numbers are just an example and are not the
% actual mappings).
%
% Your task is take one such word_indices vector and construct
% a binary feature vector that indicates whether a particular
% word occurs in the email. That is, x(i) = 1 when word i
% is present in the email. Concretely, if the word 'the' (say,
% index 60) appears in the email, then x(60) = 1. The feature
% vector should look like:
%
% x = [ 0 0 0 0 1 0 0 0 ... 0 0 0 0 1 ... 0 0 0 1 0 ..];
%
%
for i=1:length(word_indices)
x(word_indices(i))=1;
end
% =========================================================================
end
最终测试结果

