中文分词研究入门
导读
本文首先简单介绍了自然语言处理和科研过程中重要的四部曲——调研、思考、编程和写作,然后对中文分词问题进行了说明,介绍了中文分词存在的难点如消歧、颗粒度问题、分词标准等。接着,本文总结了调研文献中的分词方法,包括基于词典的最大匹配法以及其相应的改进方法、基于字标注的分词方法等,同时也介绍了当前中文分词的研究进展和方向,如统计与词典相结合、基于深度学习的分词方法等。而后,本文具体介绍了如何基于词典的双向最大匹配法以及基于字标注的平均感知机进行分词的实验,对实验结果进行了分析并给出了几种改进模型的思路。最后,本文给出了相应的参考文献以及其他资料。
本文作者:llhthinker
原文地址:http://www.cnblogs.com/llhthinker/p/6323604.html
Github代码地址: https://github.com/llhthinker/MachineLearningLab/tree/master/Chinese-Word-Segmentation
转载请保留
1. 导论
1.1 自然语言处理简介
自然语言处理(NLP, Natural Language Processing)是用机器处理人类语言(有别于人工语言,如程序设计语言)的理论和技术。自然语言处理是人工智能的一个重要分支,属于计算机应用技术(有别于计算机技术)。计算机应用技术作为二级学科所属于一级学科计算机科学技术。自然语言处理又可以称作自然语言理解或计算语言学。
自然语言处理是一个贴近应用的研究方向。NLP大致可分为基础研究和应用技术研究。基础研究包括词法分析、句法分析、语义分析和篇章理解等;应用技术研究包括文本挖掘、自动问答、信息检索、信息抽取、机器翻译等。
1.2 科学研究方法
研究活动的大致流程可以遵循如下四个阶段[1]:
-
阅读 (Reading)
-
思考 (Thinking)
-
编程 (Programming)
-
写作 (Writing)
第一阶段阅读大约占整个过程的30%。收集并阅读资料是研究过程的第一步。现在的资料浩如烟海,如何收集到有价值的资料极为重要。研究的资料主要是论文,我们应该阅读重要的论文,而重要的论文往往具有以下一种或多种特征:
-
发表在高水平(顶级)会议或期刊上:对于NPL领域,国际高水平会议包括ACL、EMNLP、COLING等,国内重要的NLP期刊如中文信息学报;
-
引用数多;
-
作者为高水平(著名)学者(参考http://cn.aminer.org/ );
-
近5年尤其是近3年的论文: 由于学术发展较快,我们应该阅读最新的论文。
如何阅读一篇论文?阅读论文时应注意以下几点:
-
以作者为线索理清脉络: 阅读论文时要注意论文作者和研究机构。以作者为线索理清该作者研究工作的脉络,以此熟悉该研究方向。
-
抓住论文要害: 论文要害主要包括研究工作的目的、待解决的问题、解决问题的难点、针对问题难点的解决方法、该方法与其他方法的对比、该方法的不足等。
-
批判式阅读: 每一篇学术论文都不是完美的,阅读论文时应带着批判的心理,在阅读中不断找出论文的问题或不足之处,并积极思考如何做可以更好的解决问题。
第二阶段思考大约占整个过程的20%。"学而不思则罔",在阅读过程中以及阅读后应该积极思考。
第三阶段编程大约占整个过程的20%。第一步是收集数据,数据可以是标准的评测数据,也可以是自己采集的真实数据。第二步是编写程序,实现算法。第三步是分析结果。
第四阶段写作大约占整个过程的30%。写作是科学研究的一个重要过程。论文是研究成果的体现,将自己的研究成果很好的展示给学术界,才能体现出研究的价值。
上述四个阶段不是瀑布式而是螺旋式,是对研究的方向不断深入的过程。
1.3 中文分词问题介绍
中文信息处理是指自然语言处理的分支,是指用计算机对中文进行处理。和大部分西方语言不同,书面汉语的词语之间没有明显的空格标记,句子是以字串的形式出现。因此对中文进行处理的第一步就是进行自动分词,即将字串转变成词串。
自动分词的重要前提是以什么标准作为词的分界。词是最小的能够独立运用的语言单位。词的定义非常抽象且不可计算。给定某文本,按照不同的标准的分词结果往往不同。词的标准成为分词问题一个很大的难点,没有一种标准是被公认的。但是,换个思路思考,若在同一标准下,分词便具有了可比较性。因此,只要保证了每个语料库内部的分词标准是一致的,基于该语料库的分词技术便可一较高下[3]。
分词的难点在于消除歧义,分词歧义主要包括如下几个方面:
-
交集歧义, 例如:
研究/ 生命/ 的/ 起源
研究生/ 命/ 的/ 起源 -
组合歧义,例如:
他 / 从 / 马 / 上 / 下来
他 / 从 / 马上 / 下来
-
未登录词,例如:
蔡英文 / 和 / 特朗普 / 通话
蔡英文 / 和 / 特朗 / 普通话
除了上述歧义,有些歧义无法在句子内部解决,需要结合篇章上下文。例如,"乒乓球拍卖完了",可以切分为"乒乓/球拍/卖/完/了",也可以切分成"乒乓球/拍卖/完/了"。这类分词歧义使得分词问题更加复杂。
词的颗粒度选择问题是分词的一个难题。研究者们往往把"结合紧密、使用稳定"视为分词单位的界定准则,然而人们对于这种准则理解的主观性差别较大,受到个人的知识结构和所处环境的很大影响[3]。选择什么样的词的颗粒度与要实现具体系统紧密相关。例如在机器翻译中,通常颗粒度大翻译效果好。比如"联想公司"作为一个整体时,很容易找到它对应的英文翻译Lenovo,如果分词时将其分开,可能翻译失败。然而,在网页搜索中,小的颗粒度比大的颗粒度好。比如"清华大学"如果作为一个词,当用户搜索"清华"时,很可能就找不到清华大学。[10]
2. 中文分词文献调研
2.1 最大匹配法
梁南元在1983年发表的论文《书面汉语的自动分词与另一个自动分词系统CDWS》提到,苏联学者1960年左右研究汉俄机器翻译时提出的 6-5-4-3-2-1 分词方法。其基本思想是先建立一个最长词条字数为6的词典, 然后取句子前6个字查词典,如查不到, 则去掉最后一个字继续查, 一直到找着一个词为止。梁南元称该方法为最大匹配法——MM方法(The Maximum Matching Method)。由MM方法自然引申,有逆向的最大匹配法。它的分词思想同MM方法,不过是从句子(或文章)末尾开始处理的,每次匹配不成词时去掉最前面的字。双向最大匹配法即为MM分词方法与逆向MM分词方法的结合。梁南元等人首次将MM方法应用于中文分词任务,实现了我国第一个自动汉语自动分词系统CDWS。[2]
2.2 复杂最大匹配法
复杂最大匹配算法, 由Chen 和Liu在《Word identification for Mandarin Chinese sentences》提出[4]。该文提出了三词语块(three word chunks)的概念。三词语块生成规则是: 在对句子中的某个词进行切分时,如果有歧义拿不定主意,就再向后展望两个汉语词,并且找出所有可能的三词语块。在所有可能的三词语块中根据如下四条规则选出最终分词结果。
规则1: 最大匹配 (Maximum matching)
其核心的假设是:最可能的分词方案是使得三词语块(three-word chunk)最长。
规则2: 最大平均词长(Largest average word length)
在句子的末尾,很可能得到的"三词语块"只有一个或两个词(其他位置补空),这时规则1就无法解决其歧义消解问题,因此引入规则2:最大平均词长,也就是从这些语块中找出平均词长最大的语块,并选取其第一词语作为正确的词语切分形式。这个规则的前提假设是:在句子中遇到多字词语的情况比单字词语更有可能。
规则3:最小词长方差(Smallest variance of word lengths)
还有一些歧义是规则1和规则2无法解决的。因此引入规则3:最小词长方差,也就是找出词长方差最小的语块,并选取其第一个词语作为正确的词语切分形式。在概率论和统计学中,一个随机变量的方差描述的是它的离散程度。因此该规则的前提假设是:句子中的词语长度经常是均匀分布的。
规则4:最大单字词语语素自由度之和(Largest sum of degree of morphemic freedom of one-character words)
有可能两个"三词语块"拥有同样的长度、平均词长及方差,因此上述三个规则都无法解决其歧义消解问题。规则4主要关注其中的单字词语。直观来看,有些汉字很少作为词语出现,而另一些汉字则常常作为词语出现,从统计角度来看,在语料库中出现频率高的汉字就很可能是一个单字词语,反之可能性就小。计算单词词语语素自由度之和的公式是对"三词语块"中的单字词语频率取对数并求和。规则4则选取其中和最大的三词语块作为最佳的词语切分形式。
最大匹配算法以及其改进方案是基于词典和规则的。其优点是实现简单,算法运行速度快,缺点是严重依赖词典,无法很好的处理分词歧义和未登录词。因此,如何设计专门的未登录词识别模块是该方法需要考虑的问题。
2.3 基于字标注的分词法
2002年,Xue等人在《Combining Classifiers for Chinese Word Segmentation》一文中首次提出对每个字进行标注,通过监督机器学习算法训练出分类器从而进行分词[5]。一年后,Xue在最大熵(ME, Maximum Entropy)模型上实现的基于字标注的分词系统参加了Bakeoff-2003的评测获得很好的成绩引起关注。而后,Xue在《Chinese word segmentation as character tagging》一文中较为详细的阐述了基于字标注的分词法[6]。
基于字标注的分词法基本思想是根据字所在词的位置,对每个字打上LL、RR、MM和LR四种标签中的一个。四种标签的具体含义如下:
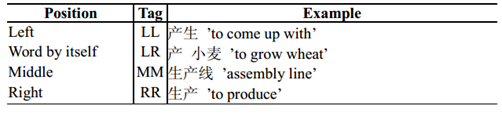
类似于词性标注中的POS(part-of-speech) tags,我们称上述字标签为POC(position-of-character) tags。这样,我们将分词问题转变成对汉字进行序列标注的问题。例如:

POC tags反映了的一个事实是,分词歧义问题是由于一个汉字可以处于一个词的不同位置,而汉字的位置取决于字的上下文。
字标注本质上是训练出一个字的分类器。模型框架如图1所示。
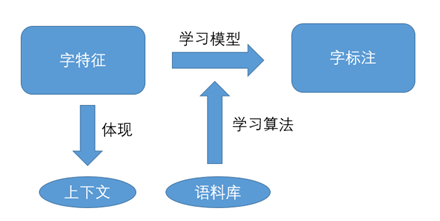
图1 字标注训练模型框架
设计字特征的关键是包含足够的上下文关系。黄昌宁等人在《中文分词十年回顾》中提到,在[3]中所有语料库99%以上的词都是5字或5字以下的词。因此,使用宽度为5个字的上下文窗口足以覆盖真实文本中绝大多数的构词情形。进一步,该文提到了一个确定有效词位标注集的定量标准——平均加权词长。其定义为:
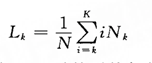
是i≥k时的平均加权词长,是语料中词长为k的词次数,K是语料中出现过的最大词长,N是语料库的总词次数。如果k=1,那么代表整个语料的平均词长。
经统计,Bakeoff-2003和Bakeoff-2005所有语料库的平均加权词长在1.51~1.71之间。因此,5字长的上下文窗口恰好大致表达了前后各一个词的上下文。
Xue在[6]文给出了如下的特征模板。

学习算法是指监督机器学习算法,常用的有最大熵算法、条件随机场(CRF, Conditional Random Fields)、支持向量机(SVM, Support Vector Machine)、平均感知机(AP, Averaged Perceptron)等。
基于字标注的分词方法是基于统计的。其主要的优势在于能够平衡地看待词表词和未登录词的识别问题。其缺点是学习算法的复杂度往往较高,计算代价较大,好在现在的计算机的计算能力相较于以前有很大提升;同时,该方法依赖训练语料库,领域自适应较差。基于字标注的分词方法是目前的主流分词方法。
2.4中文分词研究进展
2.4.1 统计与字典相结合
张梅山等人在《统计与字典相结合的领域自适应中文分词》提出通过在统计中文分词模型中融入词典相关特征的方法,使得统计中文分词模型和词典有机结合起来。一方面可以进一步提高中文分词的准确率,另一方面大大改善了中文分词的领域自适应性。[7]
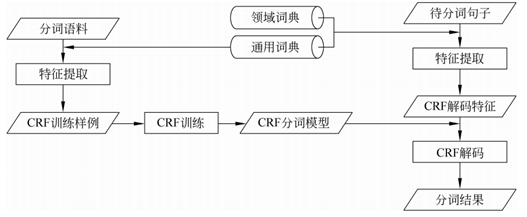
图2 领域自适应性分词系统框架图
2.4.2基于深度学习的分词方法
近几年,深度学习方法为分词技术带来了新的思路,直接以最基本的向量化原子特征作为输入,经过多层非线性变换,输出层就可以很好的预测当前字的标记或下一个动作。在深度学习的框架下,仍然可以采用基于子序列标注的方式,或基于转移的方式,以及半马尔科夫条件随机场。[11]深度学习主要有两点优势:
-
深度学习可以通过优化最终目标,有效学习原子特征和上下文的表示;
-
基于深层网络如 CNN、 RNN、 LSTM等,深度学习可以更有效的刻画长距离句子信息。
《Neural Architectures for Named Entity Recognition》一文中提出了一种深度学习框架,如图3,利用该框架可以进行中文分词。具体地,首先对语料的字进行嵌入,得到字嵌入后,将字嵌入特征输入给双向LSTM,输出层输出深度学习所学习到的特征,并输入给CRF层,得到最终模型。[9]
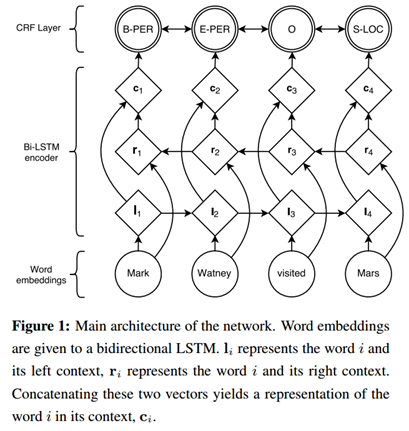
图3 一个深度学习框架
3. 中文分词方法实践
3.1 基本思路
我们首先利用正则表达式提取URL、英文一类特殊词,对文本数据进行预处理。而后分别实现双向最大匹配法和基于字标注的平均感知机分词两个分词模块并一起集成到分词系统。在使用平均感知机进行分词训练时尝试增加训练数据集,如使用Bakeoff-2005的PKU训练数据集和双向最大匹配法的分词结果进行增量训练。
3.2 双向最大匹配法
双向最大匹配法即对句子分别用正向最大匹配和逆向最大匹配进行分词,然后根据一定的规则选择某一分词结果。我们在实现是所制定的规则为:
-
如果正反向分词结果词数不同,则取分词数量较少的那个;
-
如果分词结果词数相同:
-
分词结果相同,可返回任意一个;
-
分词结果不同,返回其中单字较少的那个。
-
3.3 基于字标注的平均感知机分词方法
3.3.1 特征设计
我们选择5个字为上下文窗口大小,即:
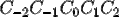
该上下文窗口包含如下7个特征:

由于感知机的基本形式是二分类的,而字标注为四分类(多分类)。为了基于感知机实现多分类,将每个字的某一特征权重设计为长度为4的向量,向量的每个分量对于某一分类的权值,如图4所示。

图4 字的特征设计
3.3.2 算法设计
对于预测算法而言,如果是简单的序列标注问题,那么取得分最高的标签即可,但是在中文分词问题中,当前字的标签与前一个字的标签密切相关,例如若前一个字标签为S(单字成词),则当前字的标签只可能为S或B(词首),为了利用上述信息,我们引入状态转移和Viterbi算法。预测算法的伪代码如图5所示。

图5 预测算法伪代码
在使用随机梯度下降法的训练过程中,我们采取平均化参数方法防止某一训练数据对结果影响较大。训练算法的伪代码如图6所示。

图6 训练算法伪代码
3.3.3 增量训练
在增量训练中,首先使用初始训练语料训练一个初始模型,然后结合初始模型以及增量语料进行增量训练得到一个增量模型。增量训练可以提高分词系统的领域适应性,进一步提高切分中文分词准确率, 同时避免了对初始语料的需求以及使用全部语料训练模型所需要的时间。[8]模型增量训练流程图如图7所示:
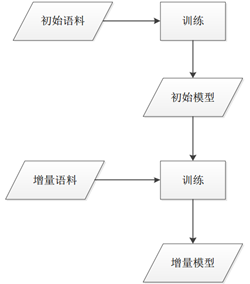
图7 模型增量训练流程图
3.4 实验结果及分析
表1给出了不同模型下测试数据1(130KB)的评测结果。该测试数据为新闻文本。从表1中可以看出,双向最大匹配的分词结果还算不错,并且算法效率高。平均感知机模型在使用Bakeoff2005的PKU训练集进行增量训练后效果提升显著,同时需要花费额外的训练时间。最后我们希望结合统计与词典的优点,尝试使用最大双向匹配分词结果集进行增量训练,分词结果有少量提升但并不明显。
表2给出了不同模型下测试数据2(31KB)的评测结果。该测试数据为微博文本。从表2中可以看出,测试数据2的分词结果比测试数据1的分词结果差。并且,值得注意的是,基于平均感知机使用原始训练集训练出的模型分词效果不太理想,而在增量训练后效果提升非常显著。这是微博文本相较于新闻文本更加不规范,新词(如网络词)更多等原因造成的。可以推测,若使用分词标准一致的微博训练集进行增量训练,将进一步提高测试数据2的分词结果。
表1 不同模型下测试数据1的评测结果
|
模型 |
训练时间 |
测试时间 |
Precision |
Recall |
F-Measure |
|
双向最大匹配 |
—— |
0.03s |
0.943 |
0.945 |
0.944 |
|
平均感知机 |
58.7s |
0.02s |
0.932 |
0.896 |
0.914 |
|
平均感知机+增量训练(Bakeoff2005 PKU训练集,6434KB) |
58.7s +568.1s |
0.02s |
0.944 |
0.941 |
0.943 |
|
平均感知机+增量训练(Bakeoff2005 PKU训练集6434KB+最大双向匹配分词结果集) |
58.7s +568.1s +37.4s |
0.02s |
0.952 |
0.941 |
0.947 |
表2 不同模型下测试数据2的评测结果
|
模型 |
训练时间 |
测试时间 |
Precision |
Recall |
F-Measure |
|
双向最大匹配 |
—— |
0.01s |
0.887 |
0.901 |
0.894 |
|
平均感知机 |
58.7s |
0.01s |
0.797 |
0.726 |
0.759 |
|
平均感知机+增量训练(Bakeoff2005 PKU训练集,6434KB) |
58.7s +568.1s |
0.01s |
0.886 |
0.900 |
0.893 |
|
平均感知机+增量训练(Bakeoff2005 PKU训练集6434KB+最大双向匹配分词结果集) |
58.7s +568.1s +20.9s |
0.01s |
0.892 |
0.900 |
0.896 |
3.5 模型改进思路
基于字标注的平均感知机分词模型的分词结果已经达到不错的精度,但是在模型性能和模型分词精度上仍有提升的空间。
为了提高模型性能,有如下几种思路[8]:
-
感知机并行训练算法:从表1中可以看出,当训练数据规模较大时,感知机的训练过程是非常耗时的。并行训练能大幅度的提高训练效率。算法的基本思想是当训练数据规模较大时,将训练数据划分为S个不相交的子集,然后在这S个不相交子集上并行训练多个子模型,对多个子模型进行融合得到最终的模型。
-
模型压缩:在实际应用中,即使训练语料规模不是特别大,根据模版提取的特征数量仍然会到达百万级甚至是千万级之多,消耗大量内存。实际上,模型中存在很大一部分特征的权重很小,对于计算状态序列的分数影响微乎其微,因此可以通过统计特征的权重对模型进行压缩,将对计算分数结果影响特别小的特征从模型中删除。这样在不显著影响性能的前提下既可以减小模型文件的大小还可以降低对内存的需求。
-
多线程并行测试:利用多核处理器,在进行分词测试时,只需要共享同一个模型,实现对文件中的多个句子的多线程并行解码。
为了提高模型的分词精度,有如下几种思路:
-
增量训练:进一步增加分词标准一致的领域训练集进行训练。
-
统计与词典相结合:实验结果表明,直接使用双向最大匹配算法的分词结果集进行并不能较好的利用词典信息从而提高分词正确率。为了更好的利用词典信息,可以将词典信息进行特征表示,融入到统计模型中。[8]
[1] 刘挺, 怎样做研究, 新浪博客http://blog.sina.com.cn/s/articlelist_1287570921_1_1.html,2007
[2] 梁南元, 书面汉语的自动分词与另一个自动分词系统CDWS, 中国汉字信息处理系统学术会议, 桂林, 1983
[3] 黄昌宁,赵海. 中文分词十年回顾. 中文信息学报. 2007
[4] Chen, K. J. and Liu S.H. Word identification for Mandarin Chinese sentences. Proceedings of the 14th International Conference on Computational Linguistics. 1992.
[5] Nianwen Xue and Susan P. Converse. Combining Classifiers for Chinese Word Segmentation, First SIGHAN Workshop attached with the 19th COLING, Taipei, 2002
[6] Nianwen Xue. Chinese word segmentation as character tagging. Computational Linguistics and Chinese Language Processing. 2003
[7] 张梅山. 邓知龙. 统计与字典相结合的领域自适应中文分词. 中文信息学报. 2012
[8] 邓知龙,基于感知器算法的高效中文分词与词性标注系统设计与实现,哈尔滨工业大学,2013
[9] Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. Neural architectures for named entity recognition. arXiv preprint arXiv:1603.01360. 2016
[10] 吴军. 数学之美(第二版).人民邮电出版社. 2014
[11] 李正华等,中文信息处理发展报告(2016). 中国中文信息学会. 2016
5. 其他资料
另附常见分词系统评测结果如下(图片来源见水印):


 浙公网安备 33010602011771号
浙公网安备 33010602011771号