


fesh个人实践,欢迎经验交流!Blog地址:http://www.cnblogs.com/fesh/p/3775429.html
Mahout之SparseVectorsFromSequenceFiles源码分析
一、原理
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。
词频 (TF) 指的是某一个给定的词语在文件中出现的次数。这个数字通常会被归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
逆向文件频率(IDF)是一个词语普遍重要性的度量,其主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。
-
对于在某一特定文件里的词语
![t_{i}]() 来说,它的重要性可表示为:
来说,它的重要性可表示为:以上式子中
![n_{i,j}]() 是该词在文件
是该词在文件![d_{j}]() 中的出现次数,而分母则是在文件
中的出现次数,而分母则是在文件![d_{j}]() 中所有字词的出现次数之和(分母也可以是词出现次数的最大值)。
中所有字词的出现次数之和(分母也可以是词出现次数的最大值)。逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
其中
- |D|:语料库中的文件总数
![|\{ j: t_{i} \in d_{j}\}|]() :包含词语
:包含词语![t_{i}]() 的文件数目(即
的文件数目(即![n_{i,j} \neq 0]() 的文件数目)如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用![1 + |\{j : t_{i} \in d_{j}\}|]()
然后
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
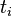 来说,它的重要性可表示为:
来说,它的重要性可表示为: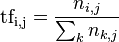
 是该词在文件
是该词在文件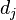 中的出现次数,而分母则是在文件
中的出现次数,而分母则是在文件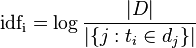
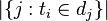 :包含词语
:包含词语 的文件数目)如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用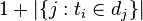

二、源码分析
目标:将一个给定的sequence文件集合转化为SparseVectors
1、对文档分词
1.1)使用最新的{@link org.apache.lucene.util.Version}创建一个Analyzer,用来下文1.2分词;
Class<? extends Analyzer> analyzerClass = StandardAnalyzer.class; if (cmdLine.hasOption(analyzerNameOpt)) { String className = cmdLine.getValue(analyzerNameOpt).toString(); analyzerClass = Class.forName(className).asSubclass(Analyzer.class); // try instantiating it, b/c there isn't any point in setting it if // you can't instantiate it AnalyzerUtils.createAnalyzer(analyzerClass); }
1.2)使用{@link StringTuple}将input documents转化为token数组(input documents必须是{@link org.apache.hadoop.io.SequenceFile}格式);
DocumentProcessor.tokenizeDocuments(inputDir, analyzerClass, tokenizedPath, conf);
输入:inputDir 输出:tokenizedPath
SequenceFileTokenizerMapper:
//将input documents按Analyzer进行分词,并将分得的词放在一个StringTuple中
TokenStream stream = analyzer.tokenStream(key.toString(), new StringReader(value.toString())); CharTermAttribute termAtt = stream.addAttribute(CharTermAttribute.class); stream.reset(); StringTuple document = new StringTuple();//StringTuple是一个能够被用于Hadoop Map/Reduce Job的String类型有序List while (stream.incrementToken()) { if (termAtt.length() > 0) { document.add(new String(termAtt.buffer(), 0, termAtt.length())); } }
2、创建TF向量(Term Frequency Vectors)---多个Map/Reduce Job
DictionaryVectorizer.createTermFrequencyVectors(tokenizedPath, outputDir, tfDirName, conf, minSupport, maxNGramSize, minLLRValue, -1.0f, false, reduceTasks, chunkSize, sequentialAccessOutput, namedVectors);
2.1)全局词统计(TF)
startWordCounting(input, dictionaryJobPath, baseConf, minSupport);
使用Map/Reduce并行地统计全局的词频,这里只考虑(maxNGramSize == 1)
输入:tokenizedPath 输出:wordCountPath
TermCountMapper:
//统计一个文本文档中的词频
OpenObjectLongHashMap<String> wordCount = new OpenObjectLongHashMap<String>(); for (String word : value.getEntries()) { if (wordCount.containsKey(word)) { wordCount.put(word, wordCount.get(word) + 1); } else { wordCount.put(word, 1); } } wordCount.forEachPair(new ObjectLongProcedure<String>() { @Override public boolean apply(String first, long second) { try { context.write(new Text(first), new LongWritable(second)); } catch (IOException e) { context.getCounter("Exception", "Output IO Exception").increment(1); } catch (InterruptedException e) { context.getCounter("Exception", "Interrupted Exception").increment(1); } return true; } });
TermCountCombiner:( 同 TermCountReducer)
TermCountReducer:
//汇总所有的words和单词的weights,并将同一word的权重sum
long sum = 0; for (LongWritable value : values) { sum += value.get(); } if (sum >= minSupport) {//TermCountCombiner没有这个过滤) context.write(key, new LongWritable(sum)); }
2.2)创建词典
List<Path> dictionaryChunks; dictionaryChunks = createDictionaryChunks(dictionaryJobPath, output, baseConf, chunkSizeInMegabytes, maxTermDimension);
读取2.1词频Job的feature frequency List,并给它们指定id
输入:wordCountPath 输出:dictionaryJobPath
/** * Read the feature frequency List which is built at the end of the Word Count Job and assign ids to them. * This will use constant memory and will run at the speed of your disk read */ private static List<Path> createDictionaryChunks(Path wordCountPath, Path dictionaryPathBase, Configuration baseConf, int chunkSizeInMegabytes, int[] maxTermDimension) throws IOException { List<Path> chunkPaths = Lists.newArrayList(); Configuration conf = new Configuration(baseConf); FileSystem fs = FileSystem.get(wordCountPath.toUri(), conf); long chunkSizeLimit = chunkSizeInMegabytes * 1024L * 1024L;//默认64M int chunkIndex = 0; Path chunkPath = new Path(dictionaryPathBase, DICTIONARY_FILE + chunkIndex); chunkPaths.add(chunkPath); SequenceFile.Writer dictWriter = new SequenceFile.Writer(fs, conf, chunkPath, Text.class, IntWritable.class); try { long currentChunkSize = 0; Path filesPattern = new Path(wordCountPath, OUTPUT_FILES_PATTERN); int i = 0; for (Pair<Writable,Writable> record : new SequenceFileDirIterable<Writable,Writable>(filesPattern, PathType.GLOB, null, null, true, conf)) { if (currentChunkSize > chunkSizeLimit) {//生成新的词典文件 Closeables.close(dictWriter, false); chunkIndex++; chunkPath = new Path(dictionaryPathBase, DICTIONARY_FILE + chunkIndex); chunkPaths.add(chunkPath); dictWriter = new SequenceFile.Writer(fs, conf, chunkPath, Text.class, IntWritable.class); currentChunkSize = 0; } Writable key = record.getFirst(); int fieldSize = DICTIONARY_BYTE_OVERHEAD + key.toString().length() * 2 + Integer.SIZE / 8; currentChunkSize += fieldSize; dictWriter.append(key, new IntWritable(i++));//指定id } maxTermDimension[0] = i;//记录最大word数目 } finally { Closeables.close(dictWriter, false); } return chunkPaths; }
2.3)构造PartialVectors(TF)
int partialVectorIndex = 0; Collection<Path> partialVectorPaths = Lists.newArrayList(); for (Path dictionaryChunk : dictionaryChunks) { Path partialVectorOutputPath = new Path(output, VECTOR_OUTPUT_FOLDER + partialVectorIndex++); partialVectorPaths.add(partialVectorOutputPath); makePartialVectors(input, baseConf, maxNGramSize, dictionaryChunk, partialVectorOutputPath, maxTermDimension[0], sequentialAccess, namedVectors, numReducers); }
将input documents使用a chunk of features创建a partial vector
(这是由于词典文件被分成了多个文件,每个文件只能构造总的vector的一部分,其中每一部分叫一个partial vector)
输入:tokenizedPath 输出:partialVectorPaths
Mapper:(Mapper)
TFPartialVectorReducer:
//读取词典文件
//MAHOUT-1247 Path dictionaryFile = HadoopUtil.getSingleCachedFile(conf); // key is word value is id for (Pair<Writable, IntWritable> record : new SequenceFileIterable<Writable, IntWritable>(dictionaryFile, true, conf)) { dictionary.put(record.getFirst().toString(), record.getSecond().get()); }
//转化a document为a sparse vector
StringTuple value = it.next(); Vector vector = new RandomAccessSparseVector(dimension, value.length()); // guess at initial size for (String term : value.getEntries()) { if (!term.isEmpty() && dictionary.containsKey(term)) { // unigram int termId = dictionary.get(term); vector.setQuick(termId, vector.getQuick(termId) + 1); } }
2.4)合并PartialVectors(TF)
Configuration conf = new Configuration(baseConf); Path outputDir = new Path(output, tfVectorsFolderName); PartialVectorMerger.mergePartialVectors(partialVectorPaths, outputDir, conf, normPower, logNormalize, maxTermDimension[0], sequentialAccess, namedVectors, numReducers);
合并所有的partial {@link org.apache.mahout.math.RandomAccessSparseVector}s为完整的{@link org.apache.mahout.math.RandomAccessSparseVector}
输入:partialVectorPaths 输出:tfVectorsFolder
Mapper:(Mapper)
PartialVectorMergeReducer:
//合并partial向量为完整的TF向量
Vector vector = new RandomAccessSparseVector(dimension, 10); for (VectorWritable value : values) { vector.assign(value.get(), Functions.PLUS);//将包含不同word的向量合并为一个 }
3、创建IDF向量(document frequency Vectors)---多个Map/Reduce Job
Pair<Long[], List<Path>> docFrequenciesFeatures = null; // Should document frequency features be processed if (shouldPrune || processIdf) { log.info("Calculating IDF"); docFrequenciesFeatures = TFIDFConverter.calculateDF(new Path(outputDir, tfDirName), outputDir, conf, chunkSize); }
3.1)统计DF词频
Path wordCountPath = new Path(output, WORDCOUNT_OUTPUT_FOLDER);
startDFCounting(input, wordCountPath, baseConf);
输入:tfDir 输出:featureCountPath
TermDocumentCountMapper:
//为一个文档中的每个word计数1、文档数1
Vector vector = value.get(); for (Vector.Element e : vector.nonZeroes()) { out.set(e.index()); context.write(out, ONE); } context.write(TOTAL_COUNT, ONE);
Combiner:(TermDocumentCountReducer)
TermDocumentCountReducer:
//将每个word的文档频率和文档总数sum
long sum = 0; for (LongWritable value : values) { sum += value.get(); }
3.2)df词频分块
return createDictionaryChunks(wordCountPath, output, baseConf, chunkSizeInMegabytes);
将df词频分块存放到多个文件,记录word总数、文档总数
输入:featureCountPath 输出:dictionaryPathBase
/** * Read the document frequency List which is built at the end of the DF Count Job. This will use constant * memory and will run at the speed of your disk read */ private static Pair<Long[], List<Path>> createDictionaryChunks(Path featureCountPath, Path dictionaryPathBase, Configuration baseConf, int chunkSizeInMegabytes) throws IOException { List<Path> chunkPaths = Lists.newArrayList(); Configuration conf = new Configuration(baseConf); FileSystem fs = FileSystem.get(featureCountPath.toUri(), conf); long chunkSizeLimit = chunkSizeInMegabytes * 1024L * 1024L; int chunkIndex = 0; Path chunkPath = new Path(dictionaryPathBase, FREQUENCY_FILE + chunkIndex); chunkPaths.add(chunkPath); SequenceFile.Writer freqWriter = new SequenceFile.Writer(fs, conf, chunkPath, IntWritable.class, LongWritable.class); try { long currentChunkSize = 0; long featureCount = 0; long vectorCount = Long.MAX_VALUE; Path filesPattern = new Path(featureCountPath, OUTPUT_FILES_PATTERN); for (Pair<IntWritable,LongWritable> record : new SequenceFileDirIterable<IntWritable,LongWritable>(filesPattern, PathType.GLOB, null, null, true, conf)) { if (currentChunkSize > chunkSizeLimit) { Closeables.close(freqWriter, false); chunkIndex++; chunkPath = new Path(dictionaryPathBase, FREQUENCY_FILE + chunkIndex); chunkPaths.add(chunkPath); freqWriter = new SequenceFile.Writer(fs, conf, chunkPath, IntWritable.class, LongWritable.class); currentChunkSize = 0; } int fieldSize = SEQUENCEFILE_BYTE_OVERHEAD + Integer.SIZE / 8 + Long.SIZE / 8; currentChunkSize += fieldSize; IntWritable key = record.getFirst(); LongWritable value = record.getSecond(); if (key.get() >= 0) { freqWriter.append(key, value); } else if (key.get() == -1) {//文档数目 vectorCount = value.get(); } featureCount = Math.max(key.get(), featureCount); } featureCount++; Long[] counts = {featureCount, vectorCount};//word数目、文档数目 return new Pair<Long[], List<Path>>(counts, chunkPaths); } finally { Closeables.close(freqWriter, false); } }
4、创建TFIDF(Term Frequency-Inverse Document Frequency (Tf-Idf) Vectors)
TFIDFConverter.processTfIdf(
new Path(outputDir, DictionaryVectorizer.DOCUMENT_VECTOR_OUTPUT_FOLDER),
outputDir, conf, docFrequenciesFeatures, minDf, maxDF, norm, logNormalize,
sequentialAccessOutput, namedVectors, reduceTasks);
4.1)生成PartialVectors(TFIDF)
int partialVectorIndex = 0; List<Path> partialVectorPaths = Lists.newArrayList(); List<Path> dictionaryChunks = datasetFeatures.getSecond(); for (Path dictionaryChunk : dictionaryChunks) { Path partialVectorOutputPath = new Path(output, VECTOR_OUTPUT_FOLDER + partialVectorIndex++); partialVectorPaths.add(partialVectorOutputPath); makePartialVectors(input, baseConf, datasetFeatures.getFirst()[0], datasetFeatures.getFirst()[1], minDf, maxDF, dictionaryChunk, partialVectorOutputPath, sequentialAccessOutput, namedVector); }
使用a chunk of features创建a partial tfidf vector
输入:tfVectorsFolder 输出:partialVectorOutputPath
DistributedCache.setCacheFiles(new URI[] {dictionaryFilePath.toUri()}, conf);//缓存df分块文件
Mapper:(Mapper)
TFIDFPartialVectorReducer:
//计算每个文档中每个word的TFIDF值
Vector value = it.next().get(); Vector vector = new RandomAccessSparseVector((int) featureCount, value.getNumNondefaultElements()); for (Vector.Element e : value.nonZeroes()) { if (!dictionary.containsKey(e.index())) { continue; } long df = dictionary.get(e.index()); if (maxDf > -1 && (100.0 * df) / vectorCount > maxDf) { continue; } if (df < minDf) { df = minDf; } vector.setQuick(e.index(), tfidf.calculate((int) e.get(), (int) df, (int) featureCount, (int) vectorCount)); }
4.2)合并partial向量(TFIDF)
Configuration conf = new Configuration(baseConf); Path outputDir = new Path(output, DOCUMENT_VECTOR_OUTPUT_FOLDER); PartialVectorMerger.mergePartialVectors(partialVectorPaths, outputDir, baseConf, normPower, logNormalize, datasetFeatures.getFirst()[0].intValue(), sequentialAccessOutput, namedVector, numReducers);
合并所有的partial向量为一个完整的文档向量
输入:partialVectorOutputPath 输出:outputDir
Mapper:Mapper
PartialVectorMergeReducer:
//汇总TFIDF向量
Vector vector = new RandomAccessSparseVector(dimension, 10); for (VectorWritable value : values) { vector.assign(value.get(), Functions.PLUS); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号