【项目总结】自然语言处理在现实生活中运用
【项目总结】自然语言处理在现实生活中运用
作者 白宁超
2015年11月9日23:27:51
摘要:自然语言处理或者是文本挖掘以及数据挖掘,近来一直是研究的热点。很多人相想数据挖掘,或者自然语言处理,就有一种莫名的距离感。其实,走进去你会发现它的美,它在现实生活中解决难题的应用之美,跟它相结合的数学之美,还有它与统计学的自然融合。语言只是一种实现工具,真正难度的是模型的理解和对模型的构建。本文结合自然语言处理的基本方法,完成对2002--2010年17套GET真题的核心单词抽取。麻雀虽小,也算五脏俱全,包含整个数据处理过程,比较简单。中等开发的程序员都可以实现,其中包括数据清洗,停用词处理,分词,词频统计,排序等常用方法。(本文原创,分享供于学习,转载标明出处:【项目总结】自然语言处理在现实生活中运用)
相关文章
【文本处理】自然语言处理在现实生活中运用
【文本处理】多种贝叶斯模型构建及文本分类的实现
【文本处理】快速了解什么是自然语言处理
【文本处理】领域本体构建方法概述
【文本挖掘(1)】OpenNLP:驾驭文本,分词那些事
【文本挖掘(2)】【NLP】Tika 文本预处理:抽取各种格式文件内容
【文本挖掘(3)】自己动手搭建搜索工具
1 需求分析与描述:
首先谈下这款软件的来源和用途吧,本科至今没有挂科记录,很不幸第一次《英语学位英语考试<GET>》挂科了。于是,笔者开始疯狂的做题和背单词,对于GET真题很多单词不认识,抱着有道词典,逐字翻译耗时耗力。再说历来10余年试题考试单词范围是一定的,把出现频率高的单词,所谓核心单词掌握了不就事倍功半了?问题来了,不像四六级词汇或者考研词汇市场有专门卖的。当时就开始设想,如果我收集10余年真题,然后去除所有非单词结构(真题算是结构化数据,有一定规则,比较容易处理。此过程其实就是数据清洗过程)最后把所有单词集中汇总,再去除如:a/an/of/on/frist等停用词(中文文本处理也需要对停用词处理,诸如:的,地,是等)。处理好的单词进行去重和词频统计,最后再利用网络工具对英语翻译。然后根据词频排序。 基于以上思路,结合笔者前不久对数据挖掘中分类实现的经验和暑假学习的统计学知识最终上周末(10.31—11.1)花了2天时间搞定,这些自然语言处理的基础方法在分类,聚类等数据挖掘和本体领域构建中都有使用。最后我将其核心方法进行梳理,下面咱们具体展开。
2 自然语言处理结果预览:
前面提到本算法是对自然语言中常规英文试卷的处理,那么开始收集原始数据吧。
1 历年(2002—2010年)GET考试真题,文档格式不一,包括txt/pdf/word等如下图:

2 对所有格式不一的文档进行统计处理成txt文档,格式化(去除汉字/标点/空格等非英文单词)和去除停用词(去除891个停用词)处理后结果如下:【17套试卷原始单词(含重复)82158个,数据清洗处理后32011个】
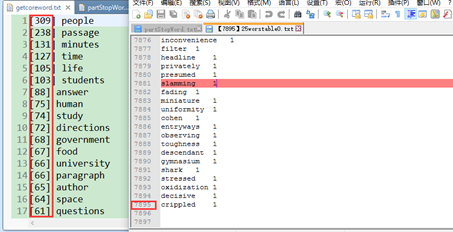
3 对清洗后的单词进行去重和词频统计:【去重后7895个单词尺寸】
4 显示这10余年考试的词汇量还是很大的,加上停用词,考查词汇量在9000左右,那么常考的应该没那么多。试想下17套试卷中,去除停用词后出现频率大于5的和小于25次【1674个单词】的数据应该是合理的,那么我就指定阈值提取。

5 最后一步,中英文翻译(目前通过google工具快速查询,然后合并)。最终效果如下:(处理的最终txt结果和自己word整理的结果)
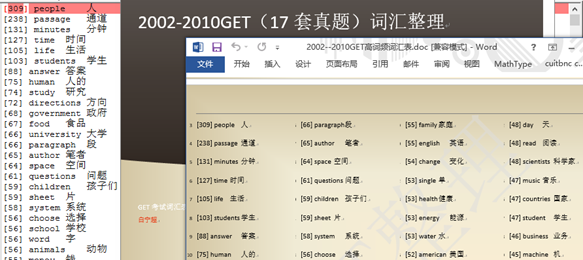
3 算法思想和解决方案:
算法思想:
1历年(2002—2010年)GET考试真题,文档格式不一。网上收集
2 对所有格式不一的文档进行统计处理成txt文档,格式化(去除汉字/标点/空格等非英文单词)和去除停用词(去除891个停用词)处理。
利用正则表达式去除非英文单词的字符,通过规则的空格分离,停用词表网上一大堆,通过将其与单词比对,不在停用词表的追加存储
3 对清洗后的单词进行去重和词频统计
通过Map统计词频,实体存储:单词-词频。(数组也可以,只是面对特别大的数据,数组存在越界问题)。排序:根据词频或者字母
4 提取核心词汇,大于5的和小于25次的数据,可以自己制定阈值。
遍历list<实体>列表时候,通过获取实体的词频属性控制选取词汇表尺寸。
5 最后一步,中英文翻译。
将批量单词通过google翻译,可以获取常用意思,对于发音,词义,词性等没有处理。这里也是可以改进地方,其实也很简单,后面详解,最后自己讲结果在word里面排版。
4 Java语言对需求实现详解:
1 文件保存路径定义
public static final String stopWordTable ="./getFile/partStopWord.txt"; //停用词词表文件地址 public static final String srcfilepath="./srcFile"; //待处理的源文件地址 public static final String stopfilepath="./getFile/temp.txt"; //待处理的源文件地址 public static final String tarfilepath="./getFile/getcoreword.txt"; //源文件和目标文件地址
2 对原始文件数据清理以及停用词处理
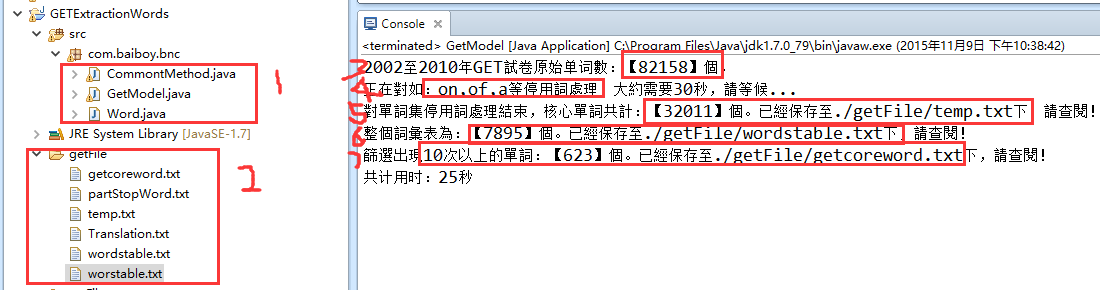
//对文本文件预处理 public static void dataCleanFile(String srcfilepath,String stopfilepath){ String reg = "[^a-zA-Z]"; //去除噪音,获取英文单词开始的内容 String sb=CommontMethod.readStrFiles(srcfilepath, " ").toLowerCase().replaceAll(reg, " ").replaceAll(" +"," ").trim(); //接收清洗后的数据 String[] srcWordsList =sb.split(" "); //按照规则,将单词放在数组里面 System.out.println("2002至2010年GET試卷原始单词數:【"+srcWordsList.length+"】個。"); System.out.println("正在對如:on,of,a等停用詞處理,大約需要30秒,請等候..."); StringBuffer stopWordSb=new StringBuffer(); //存放去除停用词后的 for(int i=0;i<srcWordsList.length;i++){ if(IsStopWord(srcWordsList[i])==false) stopWordSb.append(srcWordsList[i].toString().trim()+"\n"); //不是停用词,则追加字符串 } String[] stopWordsList =stopWordSb.toString().split("\n"); System.out.println("對單詞集停用詞處理結束,核心單詞共計:【"+stopWordsList.length+"】個。已經保存至./getFile/temp.txt下,請查閱!"); CommontMethod.writeStrFile(stopWordSb.toString(), stopfilepath, "\n"); //将预处理后并标注的数据,指定位置保存 }
3 处理后的数据进行核心单词汇总和词频统计
//统计词频 public static void countWordNums(String stopfilepath,String tarfilepath){ //统计GET试卷核心单词以及词频 Map<String,Integer> shlMap=new HashMap<String,Integer>(); //去重計數 //整個詞彙表 StringBuffer WordsTable=new StringBuffer(); List<Word> wordsList = new ArrayList<Word>(); //統計詞頻排序 StringBuffer tarWordSb=new StringBuffer(); //存放去除停用词后的,詞頻指定的單詞; List<Word> wordList = new ArrayList<Word>(); //統計詞頻排序 int sum=0;//計算非重複單詞個數。 int setnum=10; //設定保存詞頻條件 shlMap=CommontMethod.countWords(shlMap, stopfilepath.trim(), " "); int count=0; for (Map.Entry<String, Integer> entry : shlMap.entrySet()) { if(entry.getValue()>0){ wordsList.add(new Word(entry.getKey(), entry.getValue()));//統計頻率詞彙表 count++; if(entry.getValue()>setnum){ wordList.add(new Word(entry.getKey(), entry.getValue()));//統計指定頻率詞彙表 sum++; } } } //詞彙表大小 StringBuffer EglChindSb=new StringBuffer(); //存放中英对照词表; String[] freWords= CommontMethod.wordsFre(wordsList,WordsTable).split("\n"); //根據詞頻結果排序,並進行保存 String[] Tranlation=CommontMethod.readStrFile("./getFile/Translation.txt", "\n").split("\n");//中文翻译 for(int i=0;i<Tranlation.length&&i<freWords.length;i++){ EglChindSb.append(freWords[i]+"\t"+Tranlation[i]+"\n"); } CommontMethod.writeStrFile(EglChindSb.toString(),"./getFile/worstable.txt","\n"); System.out.println("整個詞彙表為:【"+count+"】個。已經保存至./getFile/wordstable.txt下,請查閱!"); //根據詞頻結果排序,並進行保存 String fWords= CommontMethod.wordsFre(wordList,tarWordSb); CommontMethod.writeStrFile(fWords.toString(), tarfilepath,"\n"); System.out.println("篩選出現"+setnum+"次以上的單詞:【"+sum+"】個。已經保存至./getFile/getcoreword.txt下,請查閱!"); //根据字母有序打印 //CommontMethod.init(shlMap); }
4 运行结果分析
1 程序处理核心代码,其中第一个类存放公共方法(小面小结有),第二个类主函数,如上代码。第三个方法实体类统计词频,这样设计,应对大数据,数据小数组即可。
2 处理后得到的结果,核心单词,数据清洗结果,停用词,翻译,最终结果等。
3 原始试卷共计82158个单词
4 数据清洗和停用词处理后剩下32011个单词
5 去重后总共7895个单词的考察范围
6 提取10次以上核心单词623个,即便5次以上不过1500个单词
7 性能方面运行25秒是稳定的,这个主要是对7895个单词排序问题耗时比较多
5 自然语言常用方法小结(JAVA实现,C#类似):
1 实体的基本使用


/** * */ package com.baiboy.bnc; /** * @author 白宁超 * */ public class Word { private String words; private int frequence; public Word(String words, int frequence) { this.words = words; this.frequence = frequence; } public String getWords() { return words; } public void setWords(String words) { this.words = words; } public int getFrequence() { return frequence; } public void setFrequence(int frequence) { this.frequence = frequence; } public String print(){ return "["+this.frequence+"] "+this.words; } }
2 批量读取目录下的文件
/** * 对单个文件的读取,并将整个以字符串形式返回 * @param srcfilepath 读取文件的地址 * @param separ 逐行读取的分隔符号,如:" ", "\t", ","等 * @return sb 字符串 */ public static String readStrFiles(String fileDirPath,String separ){ StringBuffer sb=new StringBuffer(); BufferedReader srcFileBr=null; File dir=new File(fileDirPath); if(dir.exists()&&dir.isDirectory()){ File[] files=dir.listFiles(); //获取所有文件 try{ for(File file:files){//遍历训练集文件 srcFileBr = new BufferedReader(new InputStreamReader(new FileInputStream(new File(file.toString())),"UTF-8"));//读取原文件 String line = null; while((line=srcFileBr.readLine())!=null){ if(line.length()>0) sb.append(line.trim()+separ); } } srcFileBr.close(); } catch(Exception ex){ System.out.println(ex.getMessage()); } } else System.out.println("你选择的不是目录文件"); return sb.toString().trim(); }
3 读取单个文件
/** * 对单个文件的读取,并将整个以字符串形式返回 * @param srcfilepath 读取文件的地址 * @param separ 逐行读取的分隔符号,如:" ", "\t", ","等 * @return sb 字符串 */ public static String readStrFile(String srcfilepath,String separ){ StringBuffer sb=new StringBuffer(); try{ BufferedReader srcFileBr = new BufferedReader(new InputStreamReader(new FileInputStream(new File(srcfilepath)),"UTF-8"));//读取原文件 String line = null; while((line=srcFileBr.readLine())!=null){ if(line.length()>0) sb.append(line.trim()+separ); } srcFileBr.close(); } catch(Exception ex){ System.out.println(ex.getMessage()); } return sb.toString().trim(); }
4 文件预处理,并以字符串结果返回
/** * 对文件的读取,并将整个以字符串形式返回 * @param shlMap 传入的map集合 * @param tarfilepath 读取文件的地址 * @param separ 逐行读取的分隔符号,如:" ", "\t", ","等 * @return sb 字符串 */ public static Map<String,Integer> countWords(Map<String,Integer> tarMap,String tarfilepath,String separ){ StringBuffer sb=new StringBuffer(); try{ //读取原文件 BufferedReader srcFileBr = new BufferedReader(new InputStreamReader(new FileInputStream(new File(tarfilepath)),"UTF-8")); //对读入的文本进行预处理 String paragraph = null; while((paragraph=srcFileBr.readLine())!=null&¶graph.length()>0){ String[] words = paragraph.split(separ); //遍历所有单词 for(String word:words){ if(tarMap.containsKey(word)) tarMap.put(word, tarMap.get(word)+1); else tarMap.put(word, 1); } } srcFileBr.close(); } catch(Exception ex){ System.out.println(ex.getMessage()); } return tarMap; }
5 指定保存文件
/** * 将字符串写到指定文件中 * @param str 待写入的字符串 * @param tarfilepath 目标文件路径 * @param separ 逐行读取的分隔符号,如:" ", "\t", ","等 */ public static void writeStrFile(String str,String tarfilepath,String separ){ try{ OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream(new File(tarfilepath)), "UTF-8");// 构建OutputStreamWriter对象,参数可以指定编码,默认为操作系统默认编码,windows上是gbk writer.append(str+separ);// 刷新缓存冲,写入到文件,如果下面已经没有写入的内容了,直接close也会写入 writer.close();//关闭写入流,同时会把缓冲区内容写入文件,所以上面的注释掉 } catch(Exception ex){ System.out.println(ex.getMessage()); } }
6 词频排序(中英文通用)
/** * 根據單詞詞頻排序 * @param wordList 存放單詞和詞頻 * @param tarWordSb 存放排序后的結果 * @return */ public static String wordsFre(List<Word> wordList,StringBuffer tarWordSb){ Collections.sort(wordList, new Comparator<Word>() { @Override public int compare(Word word1, Word word2) { if(word1.getFrequence()>word2.getFrequence()) return -1; else if(word1.getFrequence()<word2.getFrequence()) return 1; else return 0; } }); for (Word word : wordList) { tarWordSb.append(word.print()).append("\n"); } return tarWordSb.toString(); }
7 根据字符有序排列
/** * 根据字符有序排列 * @param shlMap */ public static void init(Map<String,Integer> shlMap){ List<Map.Entry<String, Integer>> mHashMapEntryList=new ArrayList<Map.Entry<String,Integer>>(shlMap.entrySet()); System.out.println("-----> 排序前的顺序"); for (int i = 0; i < mHashMapEntryList.size(); i++) { System.out.println(mHashMapEntryList.get(i)); } Collections.sort(mHashMapEntryList, new Comparator<Map.Entry<String,Integer>>() { @Override public int compare(Map.Entry<String,Integer> firstMapEntry, Map.Entry<String,Integer> secondMapEntry) { return firstMapEntry.getKey().compareTo(secondMapEntry.getKey()); } }); System.out.println("-----> 排序后的顺序"); for (int i = 0; i < mHashMapEntryList.size(); i++) { System.out.println(mHashMapEntryList.get(i)); } }
8 停用词处理如何判断?
// 停用词处理器 public static boolean IsStopWord(String word) { String sb2=CommontMethod.readStrFile(stopWordTable, "\n"); String[] stopWordsList =sb2.split("\n"); for(int i=0;i<stopWordsList.length;i++){ if(word.equalsIgnoreCase(stopWordsList[i])) return true; } return false; }
6 扩展改进与移植展望:
本项目由于实际需求,对其做了初步完善。基本自然语言处理方法和流程都包含了,诸如词频统计,停用词处理,单词统计,还有文件的基本操作,再结合数学模型或者统计模型可以做复杂的自然语言或者文本处理。比如朴素贝叶斯分类,首先弄明白贝叶斯分类模型,其实就是对贝叶斯公式的理解和推导。之后结合本项目词频统计文件操作,数据清洗,中文分词,停用词处理就做出来了。再如,本体构建,也是需要对数据清洗,词频统计,结果发射概率和转移概率,文本标注等实现,后面我会陆续发布相关文章。
至于本算法改进,可以对翻译部分改进,一种基于词库的检索,包括词性,词义,词标等匹配。另外一种是对英文词组的分词处理,利用英文分词解决。移植方面,可以利用C#语言在窗体上开发,最后打包应用软件。实际上我本科至于对窗体一直很热衷。也可以做成领域下核心词汇分析提取。诸如历年考研真题,高考真题,中考真题,软件开发某一方向词汇,建筑学词汇等多重应用。做成多个APP,移植到移动软件方面。
作者:白宁超,工学硕士,现工作于四川省计算机研究院,研究方向是自然语言处理和机器学习。曾参与国家自然基金项目和四川省科技支撑计划等多个省级项目。著有《自然语言处理理论与实战》一书。 自然语言处理与机器学习技术交流群号:436303759 。
出处:http://www.cnblogs.com/baiboy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号