【程序员眼中的统计学(7)】正态分布的运用:正态之美
正态分布的运用:正态之美
作者 白宁超
2015年10月15日18:30:07
摘要:程序员眼中的统计学系列是作者和团队共同学习笔记的整理。首先提到统计学,很多人认为是经济学或者数学的专利,与计算机并没有交集。诚然在传统学科中,其在以上学科发挥作用很大。然而随着科学技术的发展和机器智能的普及,统计学在机器智能中的作用越来越重要。本系列统计学的学习基于《深入浅出统计学》一书(偏向代码实现,需要读者有一定基础,可以参见后面PPT学习)。正如(吴军)先生在《数学之美》一书中阐述的,基于统计和数学模型对机器智能发挥重大的作用。诸如:语音识别、词性分析、机器翻译等世界级的难题也是从统计中找到开启成功之门钥匙的。尤其是在自然语言处理方面更显得重要,因此,对统计和数学建模的学习是尤为重要的。最后感谢团队所有人的参与。( 本文原创,转载注明出处:正态分布的运用:正态之美 )
目录
【程序员眼中的统计学(1)】 信息图形化:第一印象
【程序员眼中的统计学(2)】集中趋势度量:分散性、变异性、强大的距
【程序员眼中的统计学(3)】概率计算:把握机会
【程序员眼中的统计学(4)】离散概率分布的运用:善用期望
【程序员眼中的统计学(5)】排列组合:排序、排位、排
【程序员眼中的统计学(6)】几何分布、二项分布及泊松分布:坚持离散
【程序员眼中的统计学(7)】正态分布的运用:正态之美
【程序员眼中的统计学(8)】统计抽样的运用:抽取样本
【程序员眼中的统计学(9)】总体和样本的估计:进行预测
【程序员眼中的统计学(10)】假设检验的运用:研究证据
【程序员眼中的统计学(11)】卡方分布的应用
【程序员眼中的统计学(12)】相关与回归:我的线条如何?
1正态分布描述
正态分布是最重要的一种概率分布。正态分布概念是由德国的数学家和天文学家Moivre(棣莫弗)于1733年受次提出的,但由于德国数学家Gauss(高斯)率先将其应用于天文学家研究,故正态分布又叫高斯分布。正态分布起源于误差分析,早期的天文学家通过长期对一些天体的观测收集到了大量数据,并利用这些数据天体运动的物理模型,其中第谷与开 普勒在建模中提出了一条原则—“模型选择的最终标准是其与观测数据的符合程度”,这个“符合程度”实质上蕴涵了误差概率理论的问题,伽例略是第一个在其著作中提出随机误差这一概念的人。因其曲线呈钟形,因此人们又经常称之为钟形曲线。我们通常所说的标准正态分布是μ = 0,σ = 1的正态分布。
1.1正态分布的定义
正态分布(Normal distribution)又名高斯分布(Gaussian distribution),是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。正态分布之所以被称为正态,是因为它的形态看起来合乎理想。在现实生活中,遇到测量之类的大量连续数据时,你"正常情况下"会期望看到这种形态。
1.2正态分布符号定义
若随机变量X服从一个数学期望为μ、方差为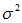 的高斯分布,记为N(μ,
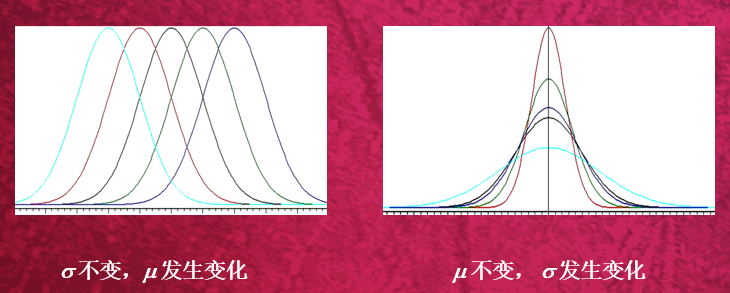
的高斯分布,记为N(μ,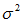 )。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。因其曲线呈钟形,因此人们又经常称之为钟形曲线。正态分布有两个参数,即均数(μ)和标准差(σ)。 μ是位置参数,当σ固定不变时, μ越大,曲线沿横轴,越向右移动;反之, μ越小,则曲线沿横轴,越向左移动。是形状参数,当μ固定不变时,σ越大,曲线越平阔;σ越小,曲线越尖峭。通常用
)。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。因其曲线呈钟形,因此人们又经常称之为钟形曲线。正态分布有两个参数,即均数(μ)和标准差(σ)。 μ是位置参数,当σ固定不变时, μ越大,曲线沿横轴,越向右移动;反之, μ越小,则曲线沿横轴,越向左移动。是形状参数,当μ固定不变时,σ越大,曲线越平阔;σ越小,曲线越尖峭。通常用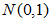 表示标准正态分布。
表示标准正态分布。
1.3正态分布公式
正态分布函数密度曲线可以表示为: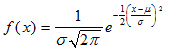 称x服从正态分布,记为X~N(m,s2),其中μ为均值,s为标准差,X∈(-∞,+ ∞ )。标准正态分布另正态分布的μ为0,s为1
称x服从正态分布,记为X~N(m,s2),其中μ为均值,s为标准差,X∈(-∞,+ ∞ )。标准正态分布另正态分布的μ为0,s为1
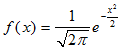
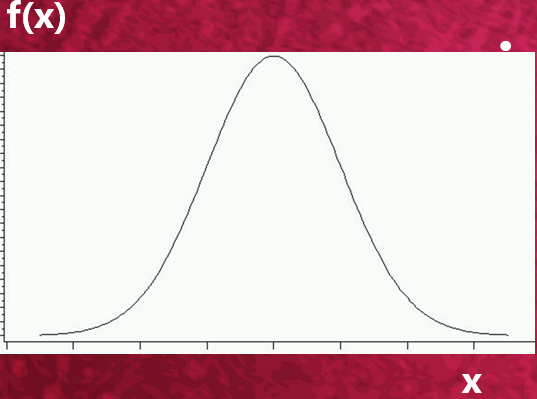
标准正态分布图形如下所示
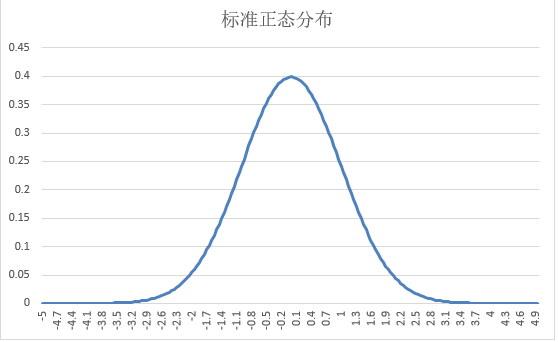
1.4正态分布函数密度曲特征
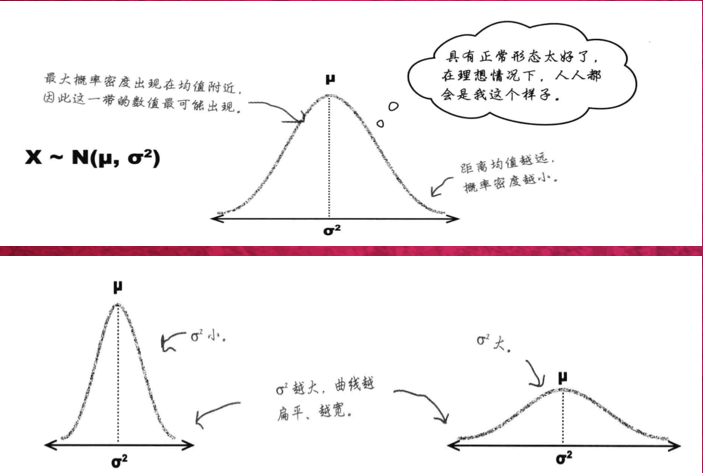
A、正态分布函数密度曲线在横轴上方均数处最高。
B、正态分布函数密度曲线以均数为中心,左右对称。
C、正态分布函数密度曲线有两个参数,即均数(μ)和标准差( s )。 μ是位置参数,当s固定不变时, μ越大,曲线沿横轴,越向右移动;反之, μ越小,则曲线沿横轴,越向左移动。是形状参数,当μ固定不变时, s越大,曲线越平阔; s 越小,曲线越尖峭。通常用N( μ , 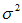 )表示均数为μ ,方差为s的正态分布。用N(0,1)表示标准正态分布。
)表示均数为μ ,方差为s的正态分布。用N(0,1)表示标准正态分布。
D、正态分布函数密度曲线下面积的总和为1。
1.5正态概率计算公式
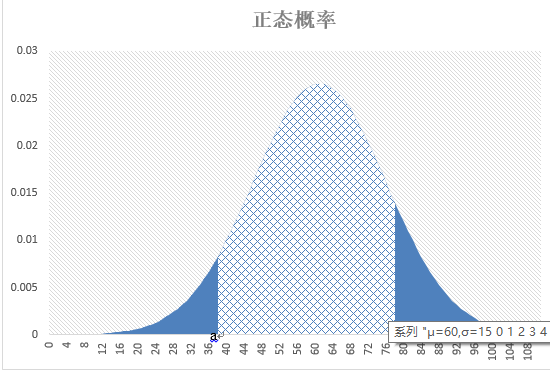
如图下图所示a到b的阴影部分面积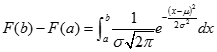 其中a,b为自变量,μ为期望,s为标准差。
其中a,b为自变量,μ为期望,s为标准差。
对于标准正态分布概率求解公式如下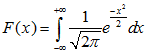 ,即令一般正态概率公式μ为0,s为1,上下限为负无穷到正无穷即可得到,通常我们用来表示标准正态概率。
,即令一般正态概率公式μ为0,s为1,上下限为负无穷到正无穷即可得到,通常我们用来表示标准正态概率。
1.5标准正态分布方差和期望
标准正态分布期望E(x)=μ
标准正态分布方差Var(x)=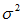
1.6正态概率计算步骤
第一步:确定数据分布:在做正态概率分计算,首先确定数据是否符合正态分布,确定正态分布的均值和方差。对一些不符和正态分布的数据进行取对数或者样本重新排列称符合正态分布的标准后,在确定均值和方差。
第二步:标准化(平移,收放):对一般正态分布进行标准化,标准化的过程为先平移,平移过程用公式表达即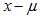 ,再对结果进行收放,收放过程即为
,再对结果进行收放,收放过程即为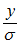 ,其中y=
,其中y=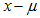 。则标准化公式:
。则标准化公式: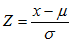 ;其中Z为标准分,x为随机变量,μ为均值,s为标准差。
;其中Z为标准分,x为随机变量,μ为均值,s为标准差。
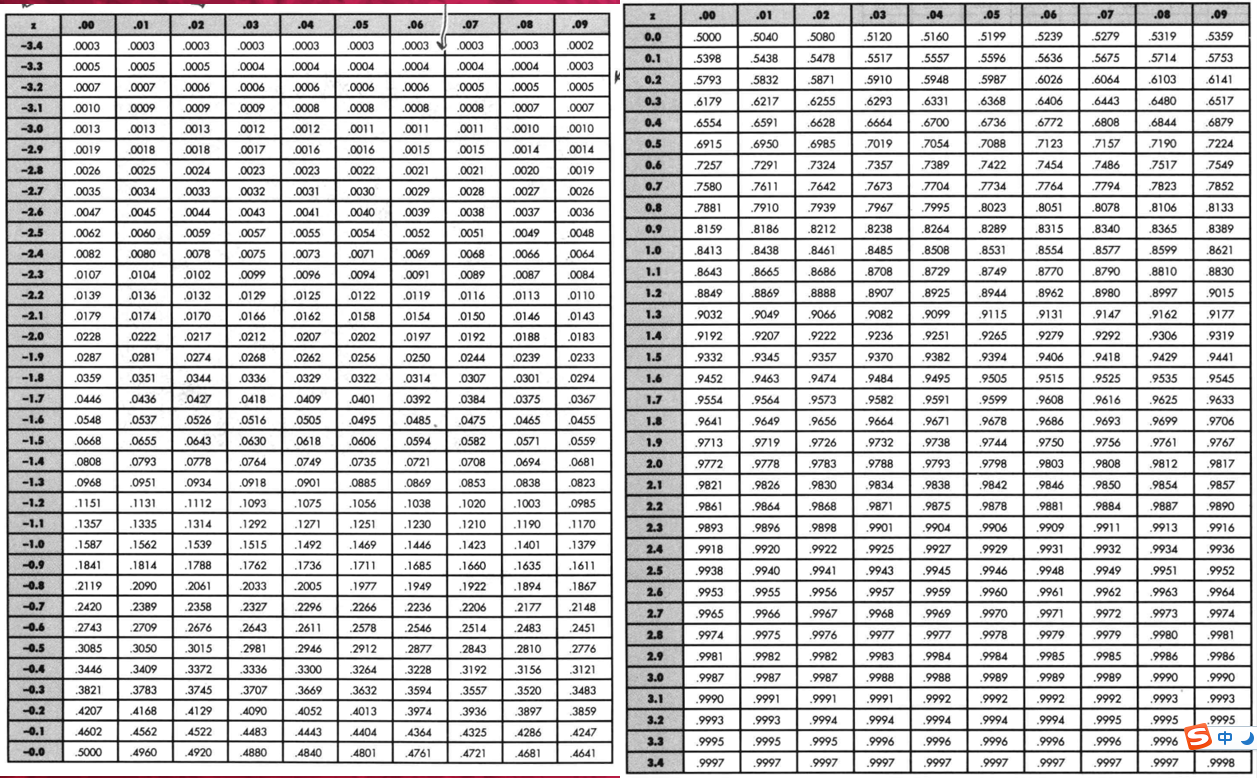
第三步:使用概率表:通过标准分,进行查表(标准正态分布概率表),得到具体的概率。
2正态概率的应用
例:某公司准备通过考试招工300名。其中280名正式工,20名临时工。实际报考人数为1675名。考试满分400分。考试不久后,通过当地新闻媒体得到如下消息:考试平均成绩是166分,360分以上的高分考生31名。某考生的成绩为256分。问他能否被录取?若被录取,能否是正式工?
数学建模:由具体问题,我们可以假设考生的成绩分布符合正态分布。设考生的成绩为x,最低分数线为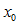 ,均值μ为166,方差设为
,均值μ为166,方差设为 ,正态分布可以记作:
,正态分布可以记作: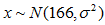 。
。
解决思想:根据条件求出方差 根据正态分布求出最低分数线 ,根据考生的成绩算出该考生在所有考生中的比例


3正态分布的优缺点
3.1正态分布优点
对于社会上遇到的大部分问题,其概率分布规律基本都满足正态分布,为了计算某种概率,我们就可以通过数学建模利用正态分布方便解决问题。
一般来说,如果一个量是由许多微小的独立随机因素影响的结果,那么就可以认为这个量具有正态分布(见中心极限定理)。从理论上看,正态分布具有很多良好的性质 ,许多概率分布可以用它来近似;还有一些常用的概率分布是由它直接导出的,例如对数正态分布、t分布、F分布等。
在一定条件下可以利用正态分布近似估算二项分布和泊松分布。
3.2正态分布缺点
无法近似估算符合几何分布的问题,无法精确解决离散数据概率。
3.3正态分布不适用场景
数据离散性太大,数据不符合正态分布特点,通过对数据进行取对数或者重新排序亦无法达到正态分布特点,无法得出均数(期望)和标准差。
3.4正态分布适用场景
连续型数据或者数据离散性小,数据基本符合正态分布特点,或者对不符合的数据进行取对数或者样本重新排序达到正态分布特点,有具体的均数(期望)和标准差。
4正态概率算法输入数据
4.1正态概率算法输入数据
* @param μ double,表示正态分布均数(期望)
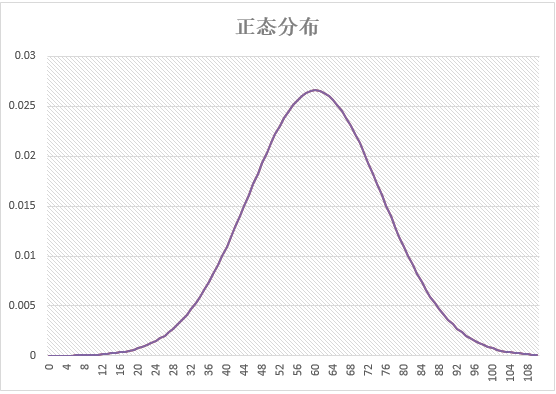
* @param
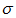 double,表示正态分布标准差(方差的开平方)
double,表示正态分布标准差(方差的开平方)
4.2正态概率算法中间结果
* @param z double,表示正态分布标准差
4.3正态分布算法输出结果
* @return S1 double,表示正态概率值
4.4正态概率算法图形化展示
5正态概率算法异常和误差
5.1正态概率算法可能异常或误差
异常:算出的标准差超出概率表出现异常
误差:保留小数位数造成不精确
5.2正态概率算法异常或误差处理
异常:解决,过小捕获异常并给予概率为0。
误差:解决,进行小数点位数自定义保留封装,根据具体精度进行设置。
6正态概率算法描述
6.1类和方法描述
类源码见源程序: Distribution.src.NormalDistribution.zheng04
方法描述:通过对需要计算标准概率的的正态分布的均值和标准差进行计算得出具体标准分再通过调用org.apache.commons.math3.distribution类来实现。
6.2类和方法调用接口
见源程序:Distribution.src.NormalDistribution.zheng04
zheng04.java 下包含如下方法:
cumulativeProbability(double z) //需要求的正态分布的标准分
调用封装方法:
NumFormat.java 下如下方法:
ZeroFormat (double num ,int n) //对num数值保留位数n的自行设置
/** * 保留几位小数 * @param num double,预备格式数据 * @return result double,保留指定小数点数据 */ public static double ZeroFormat(double num,int n) { BigDecimal bigDecimal=new BigDecimal(num); //DecimalFormat ff = new DecimalFormat("#.0000"); //保留四位小数 //double result = Double.valueOf(ff.format(num)); //return result; return bigDecimal.setScale(n, BigDecimal.ROUND_HALF_UP).doubleValue(); //setscale(n,BigDecimal.ROUND_HALF_UP).doubleValue; }
6.3源码
package NormalDistribution; import java.util.Scanner; import org.apache.commons.math3.distribution.NormalDistribution; /** * * @(#)zheng01.java * @Description:描述:根据提供的正态分布的均值和标准差得到正态概率的具体实现。 * @Definitions:定义:在处理符合正态分布的连续型数据,知道了这组数据的均值和方差为了求得随机变量符合某个范围的概率为:P(X<x)这类问题称之为正态概率。表达式为:X~N(μ,σ^2) * @Explanation:符号解释:μ为该组连续数据的均值;σ为该组连续数据的标准差。 * @Comments:条件:在一组连续型数据,已知该组数据的均值和标准差,求解随机变量x的正态概率。这种情况下适用于本算法。 * @优点:知道正态分布具体的均值和标准差可以利用此算法快速求出小于随机变量X的正态概率。 * @缺点:无法近似估算符合几何分布的问题,无法精确解决离散数据概率,对于没有给出均值或者标准差的正态分布无法计算。 * @适用场景:连续型数据或者数据离散性小,数据基本符合正态分布特点,或者对不符合的数据进行取对数或者样本重新排序达到正态分布特点,有具体的均数(期望)和标准差。。 * @不适用场景:数据离散性太大,数据不符合正态分布特点,通过对数据进行取对数或者重新排序亦无法达到正态分布特点,无法得出均数(期望)和标准差。 * @输入/出参数:见具体方法 * @异常/误差: * 异常:输入数据不合法,如:要求输入double数据,输入字母。 * 误差:保留小数位数造成不精确 * 解决: * 异常:输入不合法给予提示。 * 误差:进行小数点位数自定义保留封装,根据具体精度进行设置。 * @Create Date: 2015年8月6日16:39:25 * @since JDK1.6 s * @author Magicfairytail */ public class zheng04 { public static void main(String[] args) { /** * 均值为 μ标准差σ的正态分布的具体实现 * @param μ double型保留四位小数,表示正态分布均值 * @param σ double型保留四位小数,表示正态分布标准差 * @return S1 double型保留四位小数,表示p(X<x)的正态概率 */ NormalDistribution normalDistributioin = new NormalDistribution(0,1);//新建一个标准正态分布对象 Scanner in=new Scanner(System.in); do { System.out.println("请输入ц:"); double ц=in.nextDouble(); //ц=NumberFormat.ZeroFormat(ц);//对所得数据保留4位小数 System.out.println("请输入σ:"); double σ=in.nextDouble(); //σ=NumberFormat.ZeroFormat(σ); //对所得数据保留4位小数 System.out.println("请输入x:"); double x=in.nextDouble(); //x=NumberFormat.ZeroFormat(x);//对所得数据保留4位小数 double z=(x-ц)/σ; z=NumberFormat.ZeroFormat(z,4);//对所得数据保留4位小数 try { double S1 = normalDistributioin.cumulativeProbability(z); S1=NumberFormat.ZeroFormat(S1,4);//对所得数据保留4位小数 System.out.println("正态分布概率为:"); System.out.println(S1); System.out.println(); System.out.println("请问您还要继续输入吗?(1/0)"); } catch (Exception e) { // 这里的异常为所得的结果过小导致异常,直接将结果自动置0 System.out.println("正态分布概率为:"); System.out.println("0"); System.out.println(); System.out.println("请问您还要继续输入吗?(1/0)"); } } while (in.nextInt()==1);//while循环,当输入的值为1继续,为其他值则终止程序 } }
7正态分布的变换
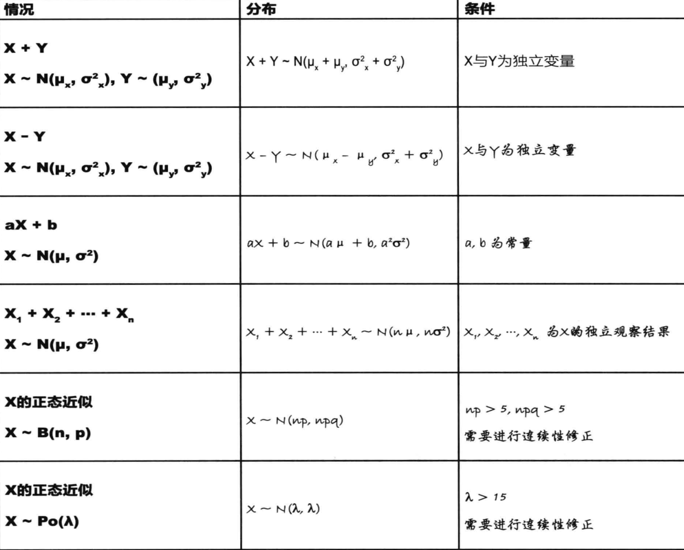
7.1在随机变量独立性的情况下,正态分布可以做以下的变换
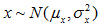 ;
; 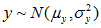 ;
;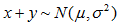 其中
其中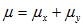 ;
;
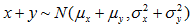 则
则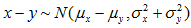

7.2在随机变量独立性的情况下,正态分布方差和期望的变换
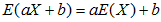 ;
;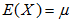 ;
;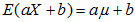 ;
;
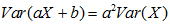 ;
;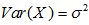 ;
;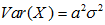 ;
;
那么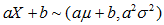

7.3在随机变量独立观察的情况下,正态分布方差和期望的变换
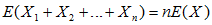
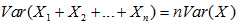
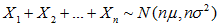
8正态分布估算二项分布
8.1正态分布估算二项分布条件
a、二项分布和正态分布的形状十分相似
b、np和nq双双大于5可以用正态分布近似代替二项分布
若符合以上2个条件,正态分布的期望等于np,方差等于npq即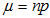 ;
; 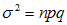
其中n为二项分布实验总次数,p为一次成功的概率,q为 。记作
。记作
8.2误差修正
8.2.1连续修正概念
将离散数据转换为连续标度时,所做的小幅调整,这个过程叫做连续修正
8.2.2连续修正使用方法
总结起来就是"小加大减",即在计算 这种形式的概率时,关键是要确保所选择的范围中包含离散数值a,在一个连续标度上一般加上相邻两个自变量单位距离的一半(eg:
这种形式的概率时,关键是要确保所选择的范围中包含离散数值a,在一个连续标度上一般加上相邻两个自变量单位距离的一半(eg: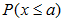 修正后即为
修正后即为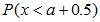 ;自变量X的单位距离为1);而在在计算
;自变量X的单位距离为1);而在在计算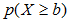 这种形式的概率时,一定要确保所选择的范围中包含离散数值b,在一个连续标度上一般减去相邻两个自变量单位距离的一半(eg:
这种形式的概率时,一定要确保所选择的范围中包含离散数值b,在一个连续标度上一般减去相邻两个自变量单位距离的一半(eg: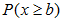 修正后即为
修正后即为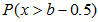 ;自变量X的单位距离为1);处理介于型数据
;自变量X的单位距离为1);处理介于型数据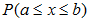 时,需要进行连续性修正,以便确保a和b均包含在内(eg:
时,需要进行连续性修正,以便确保a和b均包含在内(eg: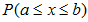 修正后即为
修正后即为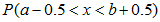 ;自变量X的单位距离为1) tip:这里的数据都为离散型数据,因为我们是拿正态分布来估算二项分布,所以就会存在误差,通过对离散数据的连续修正则可以减小误差。
;自变量X的单位距离为1) tip:这里的数据都为离散型数据,因为我们是拿正态分布来估算二项分布,所以就会存在误差,通过对离散数据的连续修正则可以减小误差。

9正态分布估算泊松分布
9.1正态分布估算泊松分布条件
a、泊松分布的形状与正态分布相似
b、如果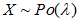 且
且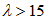 ,则可用
,则可用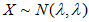 进行近似
进行近似
若符合以上2个条件,我们就可以用正态分布近似估算泊松分布,正态分布的期望等于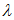 ,方差等于
,方差等于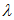 即
即 ;
; 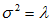 其中
其中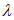 为泊松分布的平均发生次数(或者发生率)。
为泊松分布的平均发生次数(或者发生率)。
tip:近似计算时注意连续性修正。
10正态分布估算应用
10.1正态分布近似估算二项分布应用
在12个问题中答对5题或5题以下的概率,其中每个问题只有两个备选答案。
使用二项分布计算如下:
由题可知,即求出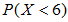 ,其中
,其中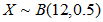
各个概率用下列公式进行计算:
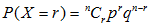 其中
其中 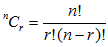
我们需要求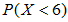 ,其中
,其中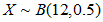 。为此,需要求
。为此,需要求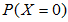 至
至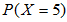 。然后将算得的所有概率加起来。各个概率为:
。然后将算得的所有概率加起来。各个概率为:
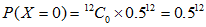
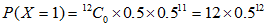
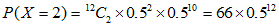
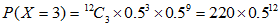
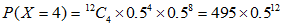
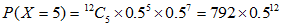
将以上概率加起来,得到总概率为:
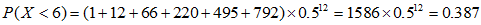 (保留三位小数)
(保留三位小数)
使用正态分布近似计算:
 ,即
,即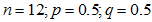 ,近似正态分布为
,近似正态分布为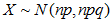 ,也就是
,也就是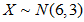 。我们要求
。我们要求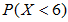 这里注意连续性修正应为
这里注意连续性修正应为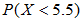 ,先计算标准差
,先计算标准差 (保留两位小数)
(保留两位小数)
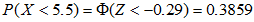
这与二项分布计算的0.387十分接近。
10.2正态分布近似估算泊松分布
游乐园过山车发生故障的次数符合泊松分布,其中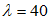 。求第一年的故障次数小于52次的概率有多大?
。求第一年的故障次数小于52次的概率有多大?
使用泊松分布计算:
如果某物体以某种平均频率发生故障,则这种情况符合泊松分布,以均值为其参数,如果X表示一年内的故障次数,则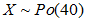 。
。
我们需要求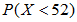 ,因此我们要求出52以内的所有X值分别对应的概率。
,因此我们要求出52以内的所有X值分别对应的概率。
这个概率太过复杂这里给出计算方法
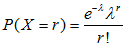
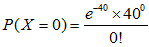
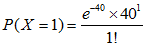
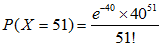
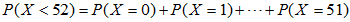
使用正态分布近似估算泊松分布:
如果用X表示一年内故障次数,则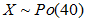 。
。
由于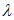 较大,我们可以用正态分布近似代替泊松分布。即可以用
较大,我们可以用正态分布近似代替泊松分布。即可以用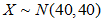
我们需要求故障次数小于52的概率,由于用连续概率分布近似代替离散概率分布,所以必须进行连续性修正。我们不应将52计算在内,只需要求出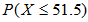 。
。
计算标准分
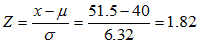 (保留两位小数)
(保留两位小数)
通过查询标准正态概率表可得结果为0.9656,则一年内的故障次数小于52的概率为0.9656。
11 总结与共享
11.1总结
11.2共享
PPT:http://yunpan.cn/cFBpqXeWsV5eA 访问密码 ed27
开源代码:http://yunpan.cn/cFBpBb46hgaA6 访问密码 8ff6
作者:白宁超,工学硕士,现工作于四川省计算机研究院,研究方向是自然语言处理和机器学习。曾参与国家自然基金项目和四川省科技支撑计划等多个省级项目。著有《自然语言处理理论与实战》一书。 自然语言处理与机器学习技术交流群号:436303759 。
出处:http://www.cnblogs.com/baiboy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号