【NLP】蓦然回首:谈谈学习模型的评估系列文章(三)
基于NLP角度的模型评价方法
作者:白宁超
2016年7月19日19:04:51
摘要:写本文的初衷源于基于HMM模型序列标注的一个实验,实验完成之后,迫切想知道采用的序列标注模型的好坏,有哪些指标可以度量。于是,就产生了对这一专题进度学习总结,这样也便于其他人参考,节约大家的时间。本文依旧旨在简明扼要梳理出模型评估核心指标,重点达到实用。本文布局如下:第一章采用统计学习角度介绍什么是学习模型以及如何选择,因为现今的自然语言处理方面大都采用概率统计完成的,事实证明这也比规则的方法好。第二章采用基于数据挖掘的角度探讨模型评估指标和选择。第三章采用统计自然语言处理的方法看看模型评价方法。第四章以R语言为实例,进行实战操作,更深入了解模型的相关问题。(本文原创,转载请注明出处:基于NLP角度的模型评价方法。)
目录
【自然语言处理:谈谈学习模型的评估(一)】:统计角度窥视模型概念
【自然语言处理:谈谈学习模型的评估(二)】:基于Data Mining角度的模型评估与选择
【自然语言处理:谈谈学习模型的评估(三)】:基于NLP角度的模型评价方法
【自然语言处理:谈谈学习模型的评估(四)】:基于R语言的模型案例实战
1 信息检索中的模型评价?
信息检索中的评价经常使用:精确率(precision)和召回率(recall)的概念,而且在自然语言处理模型评价中取得良好的效果。
信息检索中的精确度和召回率度量分析
实例:在信息检索中,我们去百度或者google一个词条,通过搜索算法返回网页信息。这个搜索算法模型如何去度量呢?如图:其中tn表示真的不相关的搜索(一般数目非常大),tp表示就是要搜索的目标网页;fp表示非目标网页,但是错误的标记成目标网页;fn表示搜索目标网页但是错误标记成不相关的网页了;selected表示选择反馈搜索者的数据集条目,系统认为相关的搜索文档(含有标记错误的页面);target是目标集,目标相关的文档(可能没有被现实出来)。
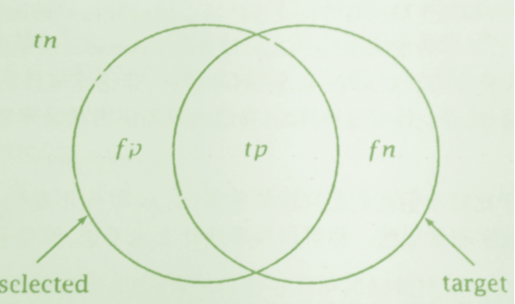
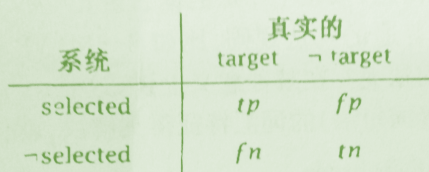
如上信息检索的文档,其混淆矩阵如下:target是检索目标,-target是非检索目标
精确率:

召回率:

在信息抽取中,精确率和召回率是相逆的(可以选择文档集合中的所有文档,得到100%的召回率,但是精确率却非常低),正是由于这样的原因,将精确率和召回率得到一个全面的度量中,一种方法是使用F度量,公式如下:
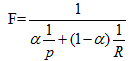
其中P是精确度,R是召回率。α表示确定精确率和召回率的权重因子。α=0.5对应着P和R相同的权重;对应α这个值,F度量简化:
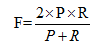
总结:在信息检索结果矩阵中,TP+TN是检索的正确数目,FP+FN是检索的错误信息数目,为何不采用准确率和错误率作为性能度量的指标?实际中不采用准确率和错误率去作为指标度量是有道理的,因为大部分实际问题中,TN的值(非目标网页的数目很大,数以亿计。)都非常大,从而使得其他数据显得微不足道。针对该情况,一般采用精确率和召回率作为度量的方法。
2 采用精确率和召回率评估检索模型的优点:
① 准确率数值对于比较小但是我们感兴趣的数值TP、FP和FN不是特别敏感,而精确率和召回率对于这样数据比较敏感。(其实就是避免FN这样庞大的数据的原因)
② 在其他条件相等情况下,F度量和TP的数量成正比,而准确率只是针对错误的数量很敏感。F度量这种倾向和我们直观感觉是一致的,我们对目标事件很敏感,甚至返回一些垃圾数据也在所不惜。
③ 遗漏的目标事件和所谓的垃圾事件对系统的影响其实并不相同,而利用精确率和召回率可以衡量其中差异。
3 准确率和F度量评价结果比较
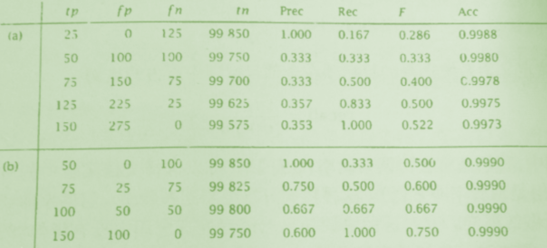
表中显示的精确率、召回率、F度量(α=0.5)和准确率对于一个100 0000项数据集进行选择的结果,这个数据集中150项数据是目标数据。
(a)表显示随着F度量值的增加准确率在下降。
(b)表显示有同样大小的准确率,但是F度量值仍在增加。F度量倾向最大化真正确TP,而准确率仅仅针对错误的数值敏感。
漏识率:一个不太常用的指标,表示被错误选择的非目标项在非目标集中所占的百分比,也就是错误出现,却被系统判断为正确的。公式表示如下:
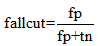
当系统很少假正确FP情况下,漏识率可以评价系统构建困难程度。如果非目标项数目非常大,那么FP较大而产生较低的精确率就有可能无法避免,因为非目标数目非常大,那么由于FP较大产生的精确率就可能无法避免。
4 参考文献
【1】 数据挖掘概念与技术(364--386) 韩家炜
【2】 数据挖掘:R语言实战(274--292) 黄文、王正林
【3】 统计自然语言处理基础 (166—169) 宛春法等译
【4】 统计学习方法(10---13) 李航
5 自然语言相关系列文章
【自然语言处理:马尔可夫模型(一)】:初识马尔可夫和马尔可夫链
【自然语言处理:马尔可夫模型(二)】:马尔可夫模型与隐马尔可夫模型
【自然语言处理:马尔可夫模型(三)】:向前算法解决隐马尔可夫模型似然度问题
【自然语言处理:马尔可夫模型(四)】:维特比算法解决隐马尔可夫模型解码问题(中文句法标注)
【自然语言处理:马尔可夫模型(五)】:向前向后算法解决隐马尔可夫模型机器学习问题
声明:关于此文各个篇章,本人采取梳理扼要,顺畅通明的写作手法。系统阅读相关书目和资料总结梳理而成,旨在技术分享,知识沉淀。在此感谢原著无私的将其汇聚成书,才得以引荐学习之用。其次,本人水平有限,权作知识理解积累之用,难免主观理解不当,造成读者不便,基于此类情况,望读者留言反馈,便于及时更正。本文原创,转载请注明出处:基于NLP角度的模型评价方法。
作者:白宁超,工学硕士,现工作于四川省计算机研究院,研究方向是自然语言处理和机器学习。曾参与国家自然基金项目和四川省科技支撑计划等多个省级项目。著有《自然语言处理理论与实战》一书。 自然语言处理与机器学习技术交流群号:436303759 。
出处:http://www.cnblogs.com/baiboy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号