


Hadoop学习笔记之六:HDFS功能逻辑(2)
 描述Lease、Block Recovery、Replication、SafeMode
描述Lease、Block Recovery、Replication、SafeMode
Lease(租约)
HDFS(及大多数分布式文件系统)不支持文件并发写,Lease是HDFS用于保证唯一写的手段。
Lease可以看做是一把带时间限制的写锁,仅持有写锁的客户端可以写文件。
租约的有效期
HDFS的Lease设定了两个时间限制:softLimit(默认1m),hardLimit(默认1h);
- Lease持有者在softLimit时限内可以写文件,且不用担心被其它写者抢走Lease;
- 在超过softLimit仅未及hardLimit时限可以续约,否则Lease可能被其它写者申请走;
- 在超过hardLimit后,Lease会被释放,写者需要重新申请Lease;对hardLimit的超时检查是由Namenode的lmthread线程执行;
租约的释放
对应于有效期的设计,Lease会在三种情况下被释放:
- 客户端显式地请求NameNode对某个文件进行 recoverLease操作;
- Lease超过softLimit,此时另一客户端申请该文件Lease;
- Lease超过harLimit,由Namenode的lmthread线程发现并执行释放;
租约的释放会引发DataNode对block的recovery过程,当DataNode完成recover block过程后,文件会被关闭。详见Recover Block
租约的结构
Lease由<holder, lastUpdate, paths>组成;
- holder是客户端的名字,支持以holder为粒度对holder对应的所有Lease进行续约;
- lastUpdate是该holder上次续约时间,用于进行超时检查;
- paths是指该holder对哪些路径持有租约;
NameNodeResourceMonitor
NameNodeResourceMonitor默认每5秒执行一次检查,查看保存image/edits的目录所在的磁盘卷空间。
磁盘卷空间信息获取是通过调用linux的shell命令实现。
如果剩余可用空间小于默认的100M,则认为该卷磁盘空间不足。当所有磁盘卷空间都不足时,则NameNode会进入safeMode。
Recover Block
客户端发起的recover block
HDFS客户端在写流水线(pipeline)的时候,如果遇到异常,会对写文件的最后一个block进行差错恢复(error recovery);这个过程被称为recover block,或block recovery;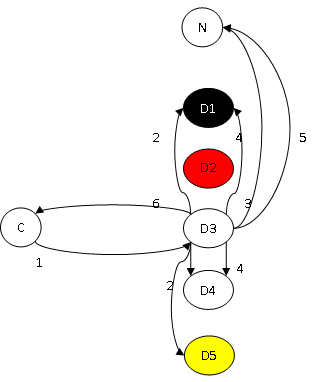
注:
- targets:D1、D3、D4、D5;
- syncList:D1、D3、D4;
- successList:D3、D4;
对该过程的简单描述如下,配合上图:
- 客户端C在写 D1->D2->D3->D4->D5流水线时,D2异常,C发起对文件最后一个block的recover block过程,根据一定的规则,选定D3为首DN(primaryDatanode),对targets中所有DN进行recover block;
- D3向其它的DataNode收集该block的信息,这个过程中可能再遇到DataNode异常或不适合recover block,如D5,将其排除后,组织成syncList队列,并选定其中最短的长度作为;
- D3向NameNode(N)发送消息请求更高的Block版本号;
- D3向syncList中所有DN发送消息,要求其对该block进行更新(包括内存对象及磁盘文件的版本号、长度,可能引发磁盘文件被切短);在这个过程中,可能再遇到DataNode异常,如D1,将其排除后,组织成successList队列;
- D3向N发送消息,提交recover block的结果:删除旧的block对象,增加新的block对象;
- 将successList返回给客户端,客户端根据该列表,重新构建流水线,继续写文件;
NameNode发起的recover block
除客户端外,在某些特殊情况下,会由NameNode发起recover block过程;其通常是由recover lease过程引起的(详见Lease(租约)的“租约释放”部分);
与客户端发起的recover block过程相比,不同之处在于:
- recover block过程的启动过程不是由客户端请求,而是通过NameNode在响应DataNode的心跳时返回命令;
- 客户端recover block通常不会关闭文件,以期完成恢复后继续写文件;而NameNode完成恢复后会关闭文件,以便客户端可以重新打开;
结合这两点,整个recover block过程的逻辑流程如下: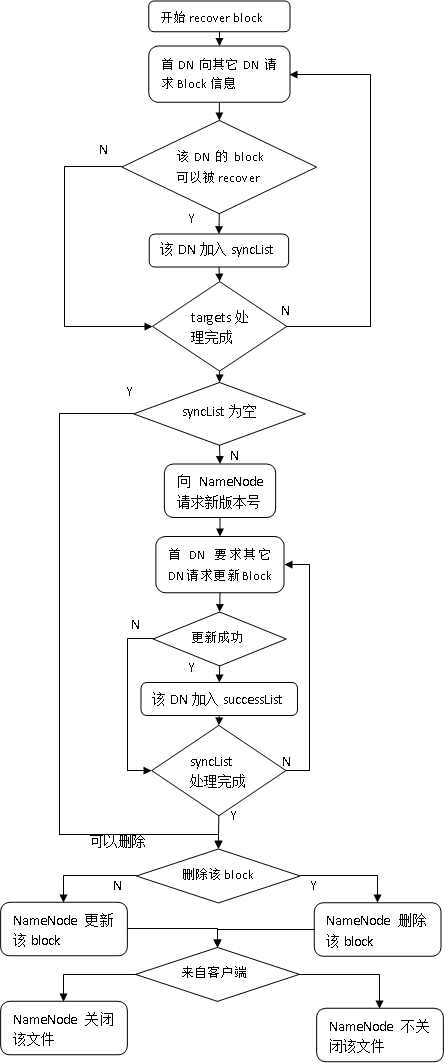
Replication(复制)
HDFS通过Replication过程保证数据块始终拥有足够多副本;
当系统发现了Block副本损坏、副本删除等操作时,会在blocksMap中对Block的副本数进行检查,将副本数不足的Block添加到FSNamesystem的neededReplications数据结构中;当进行了关闭文件、添加副本等操作后,也会检查以修正该数据结构。
Namenode节点上运行一个ReplicationMonitor线程,每dfs.replication.interval(默认为3)秒进行一次computeDatanodeWork()操作,主要是为Datanode分配Replication任务(另外还会分配删除任务);
- ReplicationMonitor从neededReplications中取出一定数量的Block;
- 为每个Block挑选Replication的源节点,将该Block添加到源节点DatanodeDescriptor的replicateBlocks数据结构中;
- 同时该将该Block添加到FSNamesystem的pendingReplications数据结构中;
- 如果复制后副本数足够,将该Block从neededReplications数据结构中移除;
之后, ReplicationMonitor线程会检查pendingReplications数据结构,找出已经超时的Replication操作,重新加入到neededReplications数据结构中。
在pendingReplications数据结构内部,使用一个数据结构保存当前pending的Replication操作,另一个数据结构保存已经超时的Replication操作,并使用一个线程(timerThread)定期(默认5m)检查,以5m超时;
整体示意图如下:

SafeMode(安全模式)
SafeMode是HDFS集群的一种特殊状态,在该状态下,很多对命名空间的修改都被禁止。被禁止的操作有:
- 修改文件属性;
- 修改文件属主;
- 修改文件时间属性;
- 修改文件复本数;
- 创建/追加文件;
- 为文件增加文件块;
- 舍弃一个文件块;
- 关闭文件;
- 重命名文件;
- 删除文件;
- 创建目录;
- 设置配额;
- 对文件进行同步;fsync
- 对文件块进行同步;commitBlockSynchronization
- 获取下一个GenerationStamp;
- 恢复租约;
- 更新租约;
- 获取、更新、销毁安全令牌;
- 滚动元数据存储文件(fsimge及edits)
NameNode进入safeMode后,对内存及磁盘上的元数据文件的“小规模修改”都无法进行,但“大规模替换”,如加载(loadFSImage、loadFSEdit)、写出(saveNamespace)则可以进行。
safeMode的进入条件
在0.20.2-cdh3u2版本中,是否应当进入safeMode由以下参数决定:
| 参数名 | 默认值 | 作用 |
| dfs.safemode.threshold.pct | 95% | 如果已经汇到的block数少于总block数的该比例,则需要进入safeMode; |
| dfs.safemode.min.datanodes | 0 | 当前存活的datanode个数少于该数字则需要进入safeMode; |
此外,当namenode节点资源不足时也会进入safeMode,见:NameNodeResourceMonitor
safeMode在以下过程中会触发条件检查:
- 设定block总数(命名空间初始化时执行);
- 增加安全block的个数;
- 减少安全block的个数;
- 注册一个datanode;(注:在hadoop-0.2x版本中,该过程并不触发条件检查)
- 删除一个datanode;(注:同上)
safeMode监测
NameNode进入safeMode的同时,会启动一个线程进行safeMode状态监测,其每秒钟检查一次是否可以离开safeMode;离开safeMode后,线程结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号