第三次作业
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
一.单线程
核心代码:
# URL管理
urls_to_visit = deque([start_url])
visited_urls = set()
# 计数器
pages_scraped_count = 0
images_downloaded_count = 0
start_time = time.time()
# 标记是否已达到图片上限,用于跳出外层循环
image_limit_reached = False
#循环爬取页面,直到达到页面上限或无页面可爬
while urls_to_visit and pages_scraped_count < MAX_PAGES_TO_SCRAPE:
current_url = urls_to_visit.popleft()
if current_url in visited_urls:
continue
print(f"\n[页面 {pages_scraped_count + 1}/{MAX_PAGES_TO_SCRAPE}] 正在爬取: {current_url}")
visited_urls.add(current_url)
pages_scraped_count += 1
# 爬取当前页面内容
try:
response = requests.get(current_url, headers=headers, timeout=10)
response.raise_for_status()
response.encoding = response.apparent_encoding
except requests.RequestException as e:
print(f" -> 请求页面失败: {e}")
continue
soup = BeautifulSoup(response.text, 'html.parser')
# 提取并下载图片,直到达到图片上限 ---
img_tags = soup.find_all('img')
for img_tag in img_tags:
if images_downloaded_count >= MAX_IMAGES_TO_DOWNLOAD:
print(f"\n已达到图片下载上限 ({MAX_IMAGES_TO_DOWNLOAD} 张),停止下载。")
image_limit_reached = True
break
img_url = img_tag.get('src')
if not img_url:
continue
img_url_full = urljoin(current_url, img_url)
# 对 // 开头的URL进行处理
if img_url_full.startswith('//'):
img_url_full = 'http:' + img_url_full
# 下载单张图片
try:
img_response = requests.get(img_url_full, headers=headers, stream=True, timeout=15)
img_response.raise_for_status()
img_name = os.path.basename(urlparse(img_url_full).path)
if not img_name:
img_name = f"image_{int(time.time() * 1000)}.jpg"
save_path = os.path.join(save_dir, img_name)
with open(save_path, 'wb') as f:
for chunk in img_response.iter_content(1024):
f.write(chunk)
images_downloaded_count += 1
print(f" -> [图片 {images_downloaded_count}/{MAX_IMAGES_TO_DOWNLOAD}] 成功下载: {img_url_full}")
except requests.RequestException as e:
print(f" -> 下载图片失败: {img_url_full}, 原因: {e}")
except Exception as e:
print(f" -> 处理图片时发生未知错误: {img_url_full}, 原因: {e}")
# 如果图片数量已达上限,则彻底停止爬取
if image_limit_reached:
break
代码采用了广度优先搜索的方法进行网页爬取。在第二次作业爬取该网站的基础上,它使用了一个双端队列 deque 来维护待访问的URL列表,并从起始网址开始逐层访问页面链接,同时确保不会重复访问相同的URL。
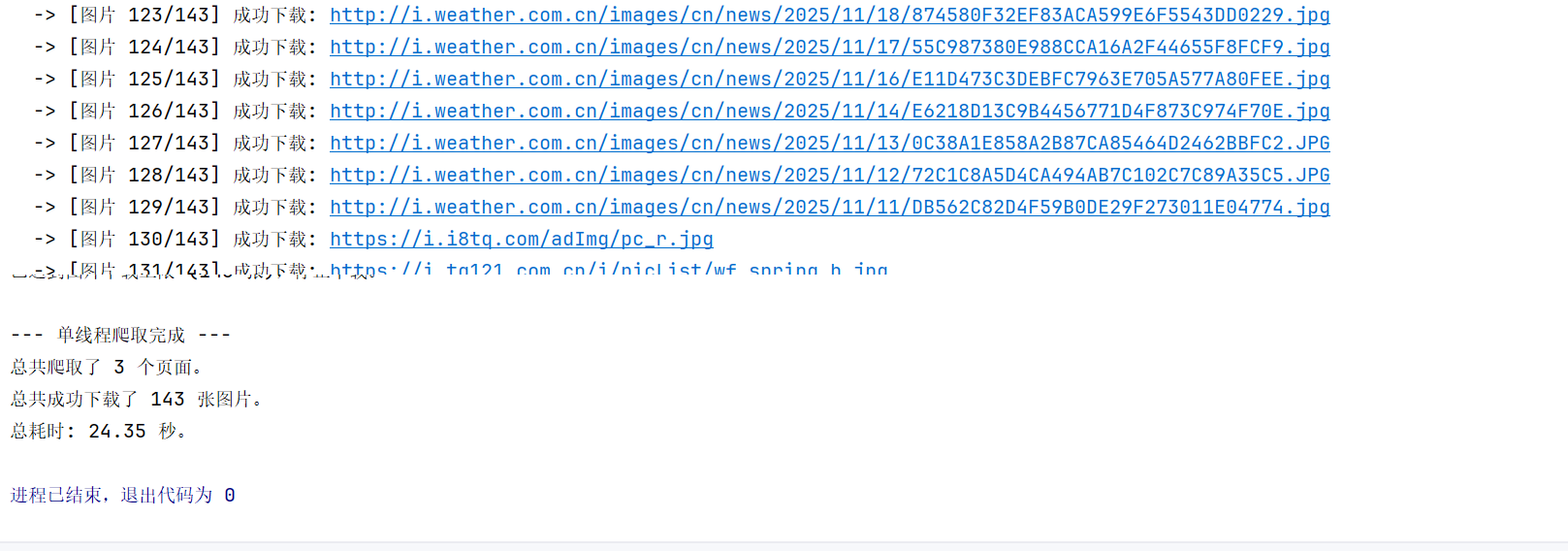
运行结果:
二.多线程
核心代码:
带限制的多线程爬虫
def controlled_image_scraper(start_url, save_dir='images_controlled', max_workers=10):
print("--- 开始带限制的多线程爬取 ---")
print(f"学号: {STUDENT_ID}")
print(f"页面爬取上限: {MAX_PAGES_TO_SCRAPE} 页")
print(f"图片下载上限: {MAX_IMAGES_TO_DOWNLOAD} 张")
if not os.path.exists(save_dir):
os.makedirs(save_dir)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# 获取域名,用于判断链接是否为站内链接
base_domain = urlparse(start_url).netloc
# URL管理
urls_to_visit = deque([start_url])
visited_urls = set()
# 计数器
pages_scraped_count = 0
images_queued_count = 0
start_time = time.time()
# 使用线程池下载图片
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_url = {}
#循环爬取页面,直到达到页面上限或无页面可爬 ---
while urls_to_visit and pages_scraped_count < MAX_PAGES_TO_SCRAPE:
current_url = urls_to_visit.popleft()
if current_url in visited_urls:
continue
print(f"\n[页面 {pages_scraped_count + 1}/{MAX_PAGES_TO_SCRAPE}] 正在爬取: {current_url}")
visited_urls.add(current_url)
pages_scraped_count += 1
# 爬取当前页面内容
try:
response = requests.get(current_url, headers=headers, timeout=10)
response.raise_for_status()
response.encoding = response.apparent_encoding
except requests.RequestException as e:
print(f" -> 请求页面失败: {e}")
continue
soup = BeautifulSoup(response.text, 'html.parser')
# 提取图片链接并提交下载任务,直到达到图片上限 ---
img_tags = soup.find_all('img')
for img_tag in img_tags:
if images_queued_count >= MAX_IMAGES_TO_DOWNLOAD:
print(f"\n已达到图片下载上限 ({MAX_IMAGES_TO_DOWNLOAD} 张),不再添加新图片。")
break # 停止在此页面上查找图片
img_url = img_tag.get('src')
if not img_url:
continue
img_url_full = urljoin(current_url, img_url)
# 提交到线程池
future = executor.submit(download_image, img_url_full, save_dir, headers)
future_to_url[future] = img_url_full
images_queued_count += 1
print(f" -> [图片 {images_queued_count}/{MAX_IMAGES_TO_DOWNLOAD}] 已添加下载任务: {img_url_full}")
if images_queued_count >= MAX_IMAGES_TO_DOWNLOAD:
break # 彻底停止爬取新页面
# 提取页面内的链接,加入待爬取队列
link_tags = soup.find_all('a', href=True)
for link_tag in link_tags:
link_url = urljoin(current_url, link_tag['href'])
# 确保是站内链接、是http/https协议、并且未被访问过
if (urlparse(link_url).netloc == base_domain and
urlparse(link_url).scheme in ['http', 'https'] and
link_url not in visited_urls):
urls_to_visit.append(link_url)
print("\n--- 所有爬取任务已提交,等待下载完成 ---")
这段代码采用了广度优先搜索结合多线程并发下载的方法进行爬取。
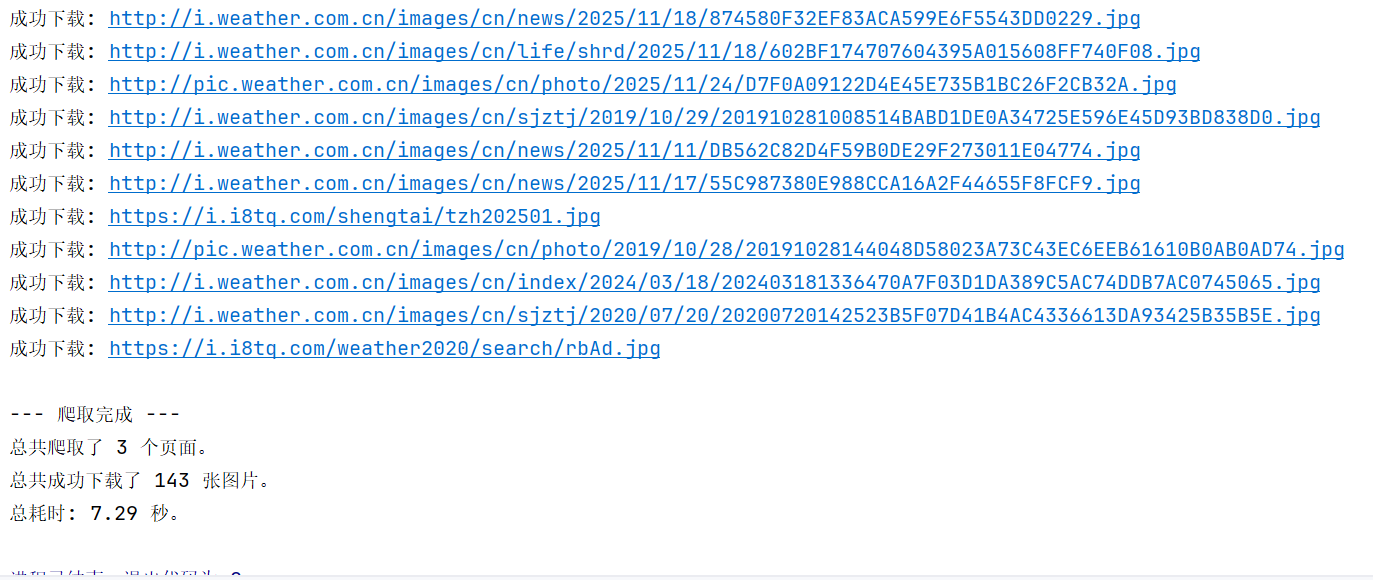
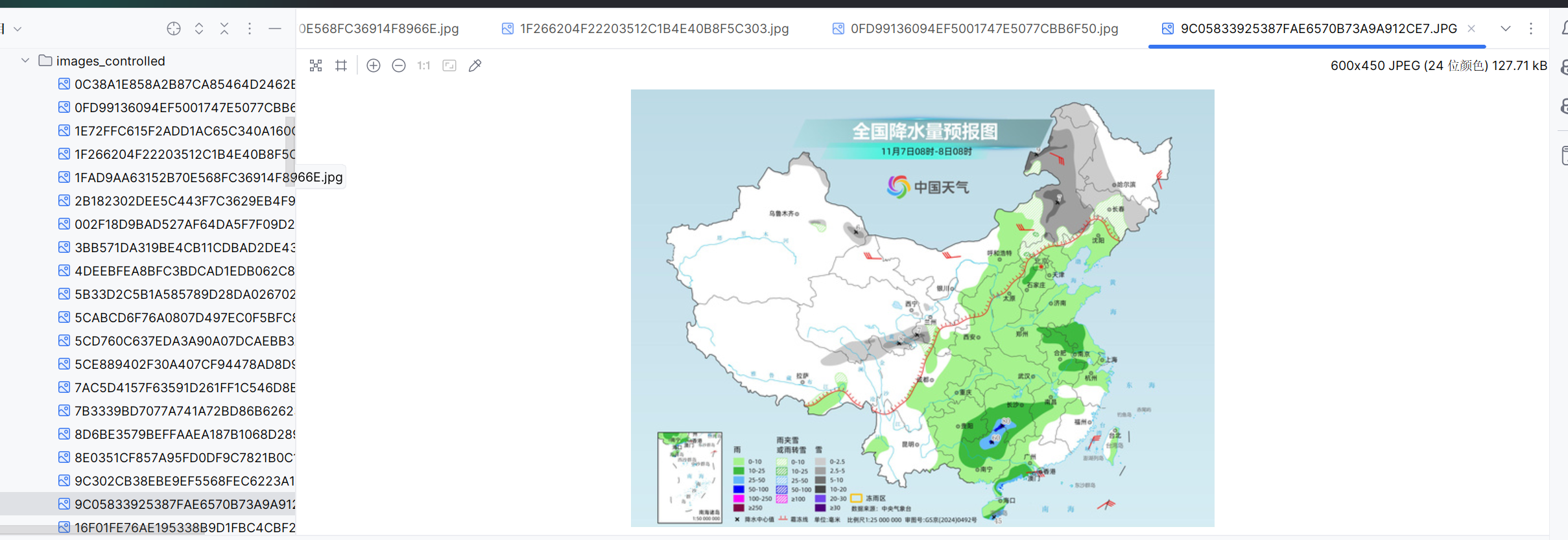
运行结果:
心得体会:
从这次作业我掌握了如何使用单线程和多线程的方法爬取数据,并且认识到多线程在效率上远比单线程高得多,体会到了并发的优越性。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
scrapy框架展示:
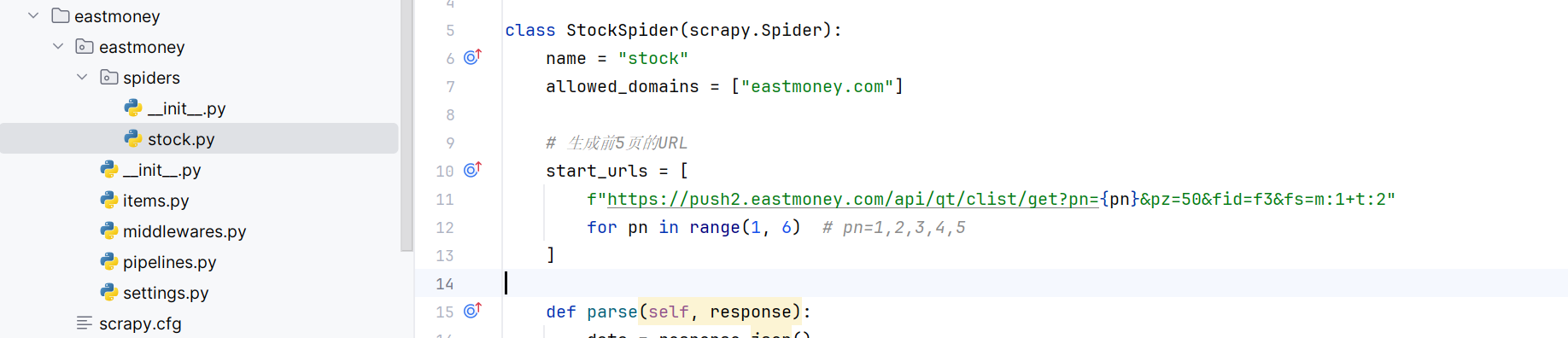
核心代码:
1.items
import scrapy
class EastmoneyItem(scrapy.Item):
bStockNo = scrapy.Field()
bStockName = scrapy.Field()
bLatestPrice = scrapy.Field()
bUpDownRange = scrapy.Field()
bUpDownAmount = scrapy.Field()
bVolume = scrapy.Field()
bAmplitude = scrapy.Field()
bHighest = scrapy.Field()
bLowest = scrapy.Field()
bTodayOpen = scrapy.Field()
bYesterdayClose = scrapy.Field()
2.piplines
import pymysql
class EastmoneyPipeline:
def open_spider(self, spider):
self.db = pymysql.connect(
host='localhost',
user='root',
password='zzx041225',
database='stockdb',
charset='utf8mb4'
)
self.cursor = self.db.cursor()
def process_item(self, item, spider):
sql = """
INSERT INTO tb_stock(
bStockNo, bStockName, bLatestPrice, bUpDownRange,
bUpDownAmount, bVolume, bAmplitude, bHighest, bLowest,
bTodayOpen, bYesterdayClose
) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
values = (
item['bStockNo'],
item['bStockName'],
item['bLatestPrice'],
item['bUpDownRange'],
item['bUpDownAmount'],
item['bVolume'],
item['bAmplitude'],
item['bHighest'],
item['bLowest'],
item['bTodayOpen'],
item['bYesterdayClose']
)
self.cursor.execute(sql, values)
self.db.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.db.close()
3.spider
import scrapy
from eastmoney.items import EastmoneyItem
class StockSpider(scrapy.Spider):
name = "stock"
allowed_domains = ["eastmoney.com"]
# 生成前5页的URL
start_urls = [
f"https://push2.eastmoney.com/api/qt/clist/get?pn={pn}&pz=50&fid=f3&fs=m:1+t:2"
for pn in range(1, 6) # pn=1,2,3,4,5
]
def parse(self, response):
data = response.json()
diff = data.get('data', {}).get('diff', {})
for s in diff.values():
item = EastmoneyItem()
item['bStockNo'] = s.get('f12')
item['bStockName'] = s.get('f14')
item['bLatestPrice'] = s.get('f2')
item['bUpDownRange'] = s.get('f3')
item['bUpDownAmount'] = s.get('f4')
item['bVolume'] = s.get('f5')
item['bAmplitude'] = s.get('f7')
item['bHighest'] = s.get('f15')
item['bLowest'] = s.get('f16')
item['bTodayOpen'] = s.get('f17')
item['bYesterdayClose'] = s.get('f18')
yield item
4.settings:
BOT_NAME = "eastmoney"
SPIDER_MODULES = ["eastmoney.spiders"]
NEWSPIDER_MODULE = "eastmoney.spiders"
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120 Safari/537.36"
}
ITEM_PIPELINES = {
'eastmoney.pipelines.EastmoneyPipeline': 300,
}
这次依然只爬取前五页数据,将爬取的数据存到MySQL并打印表格。
运行结果:
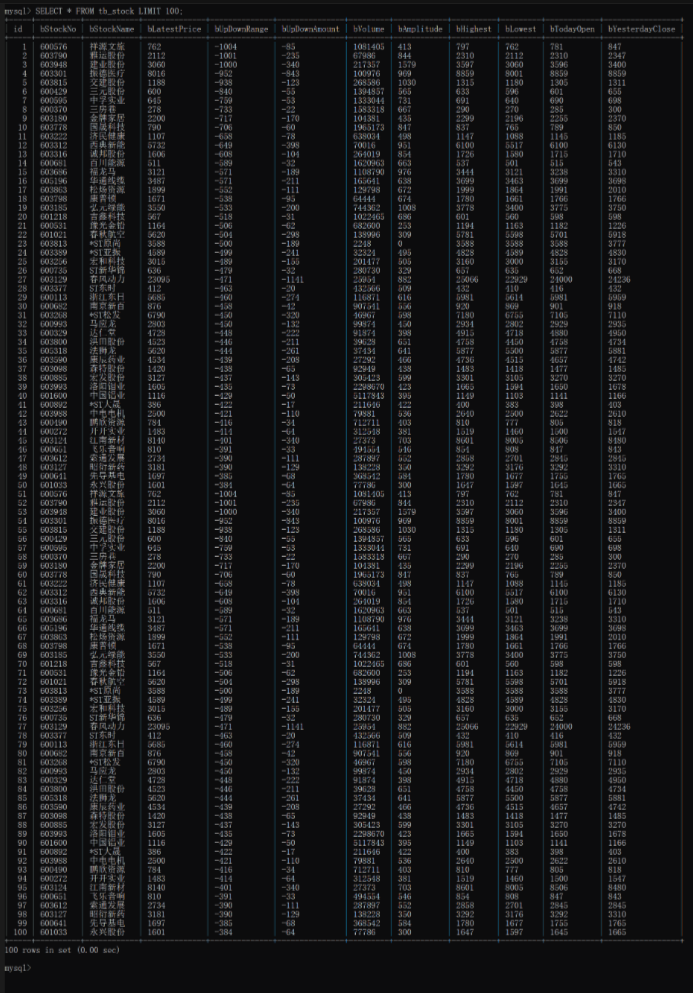
心得体会:
这次爬取借鉴了前面的股票爬取代码,改用scrapy框架,将爬取的数据存到Mysql中。从这次实验我掌握了scrapy运行的框架逻辑,并自己搭建了数据库,成功存入数据,学会了使用MySQL。
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
scrapy框架展示:
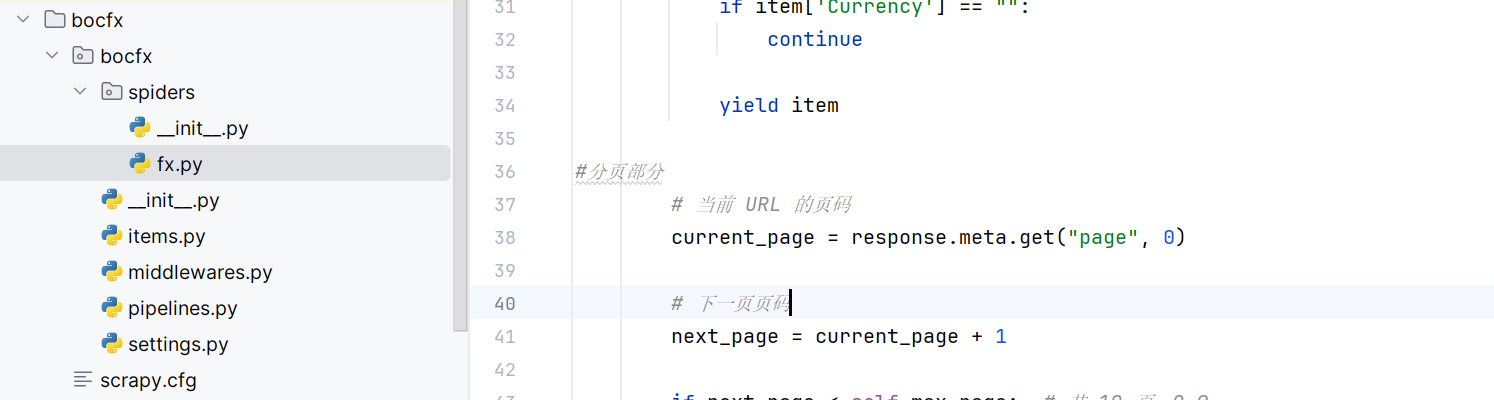
核心代码:
1.items:
import scrapy
class BocfxItem(scrapy.Item):
Currency = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
Time = scrapy.Field()
2.piplines:
import pymysql
class BocfxPipeline:
def open_spider(self, spider):
self.db = pymysql.connect(
host='localhost',
user='root',
password='zzx041225',
database='fxdb',
charset='utf8mb4'
)
self.cursor = self.db.cursor()
def process_item(self, item, spider):
sql = """
INSERT INTO tb_fx(Currency, TBP, CBP, TSP, CSP, Time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
values = (
item["Currency"],
item["TBP"],
item["CBP"],
item["TSP"],
item["CSP"],
item["Time"]
)
self.cursor.execute(sql, values)
self.db.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.db.close()
spider:
import scrapy
from bocfx.items import BocfxItem
class FxSpider(scrapy.Spider):
name = "fx"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
# 最多爬取 10 页
max_page = 10
def parse(self, response):
# 表格行
rows = response.xpath('//table//tr')
# 跳过标题
for row in rows[1:]:
if not row.xpath("./td"):
continue
item = BocfxItem()
item['Currency'] = row.xpath("./td[1]/text()").get(default="").strip()
item['TBP'] = row.xpath("./td[2]/text()").get(default="").strip()
item['CBP'] = row.xpath("./td[3]/text()").get(default="").strip()
item['TSP'] = row.xpath("./td[4]/text()").get(default="").strip()
item['CSP'] = row.xpath("./td[5]/text()").get(default="").strip()
item['Time'] = row.xpath("./td[7]/text()").get(default="").strip()
if item['Currency'] == "":
continue
yield item
#分页部分
# 当前 URL 的页码
current_page = response.meta.get("page", 0)
# 下一页页码
next_page = current_page + 1
if next_page < self.max_page: # 共 10 页:0~9
if next_page == 0:
next_url = "https://www.boc.cn/sourcedb/whpj/"
else:
next_url = f"https://www.boc.cn/sourcedb/whpj/index_{next_page}.html"
yield scrapy.Request(
url=next_url,
callback=self.parse,
meta={"page": next_page}
)
查找该页面想要爬取的元素所在位置,如图:
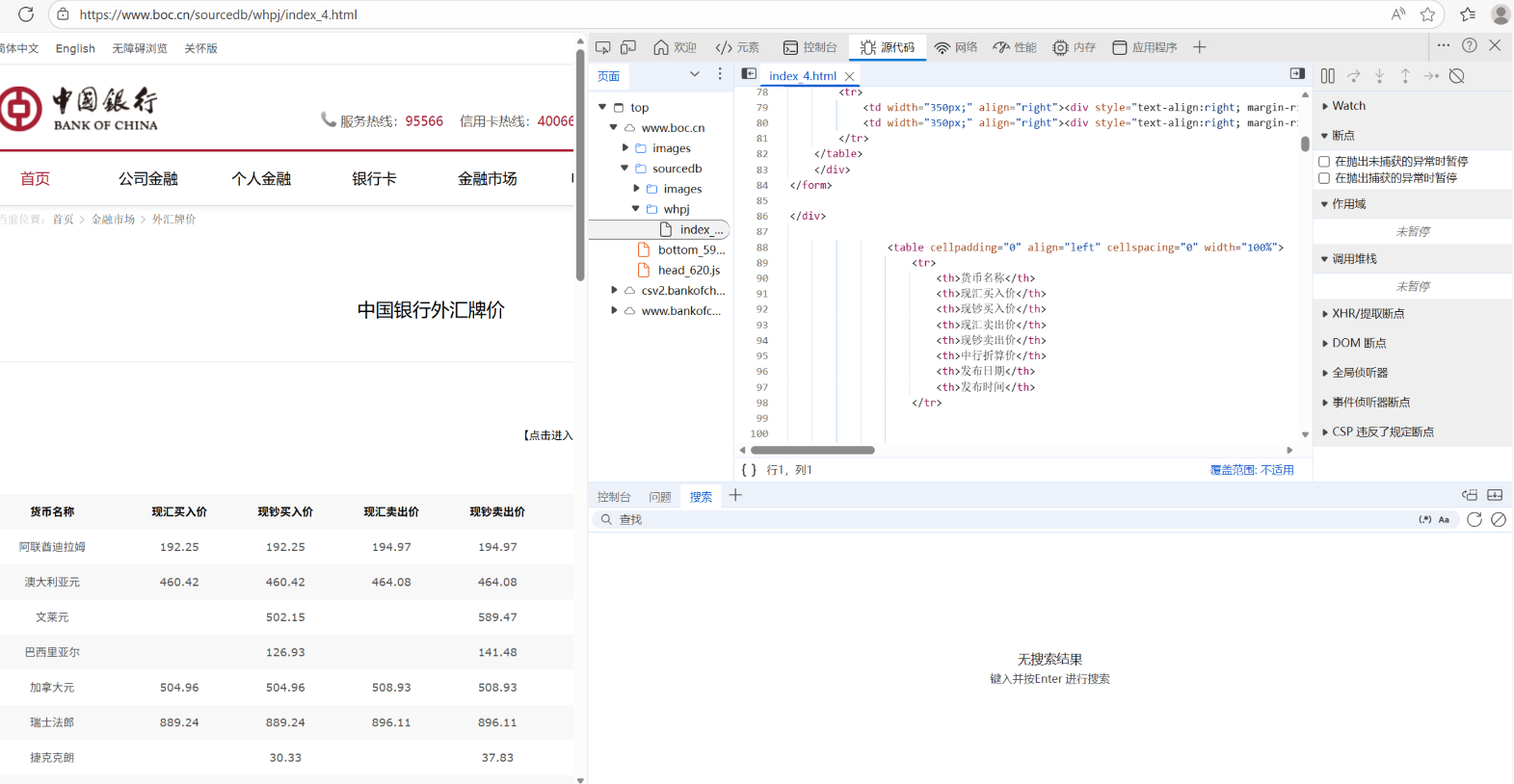
发现改页面数据只有10页,并且翻页只是简单的page,所以设定当页数据爬完之后page+1即可实现翻页功能。
4.settings:
BOT_NAME = "bocfx"
SPIDER_MODULES = ["bocfx.spiders"]
NEWSPIDER_MODULE = "bocfx.spiders"
ROBOTSTXT_OBEY = False
# UA
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120 Safari/537.36"
}
# 启用 Pipeline
ITEM_PIPELINES = {
"bocfx.pipelines.BocfxPipeline": 300,
}
运行结果:
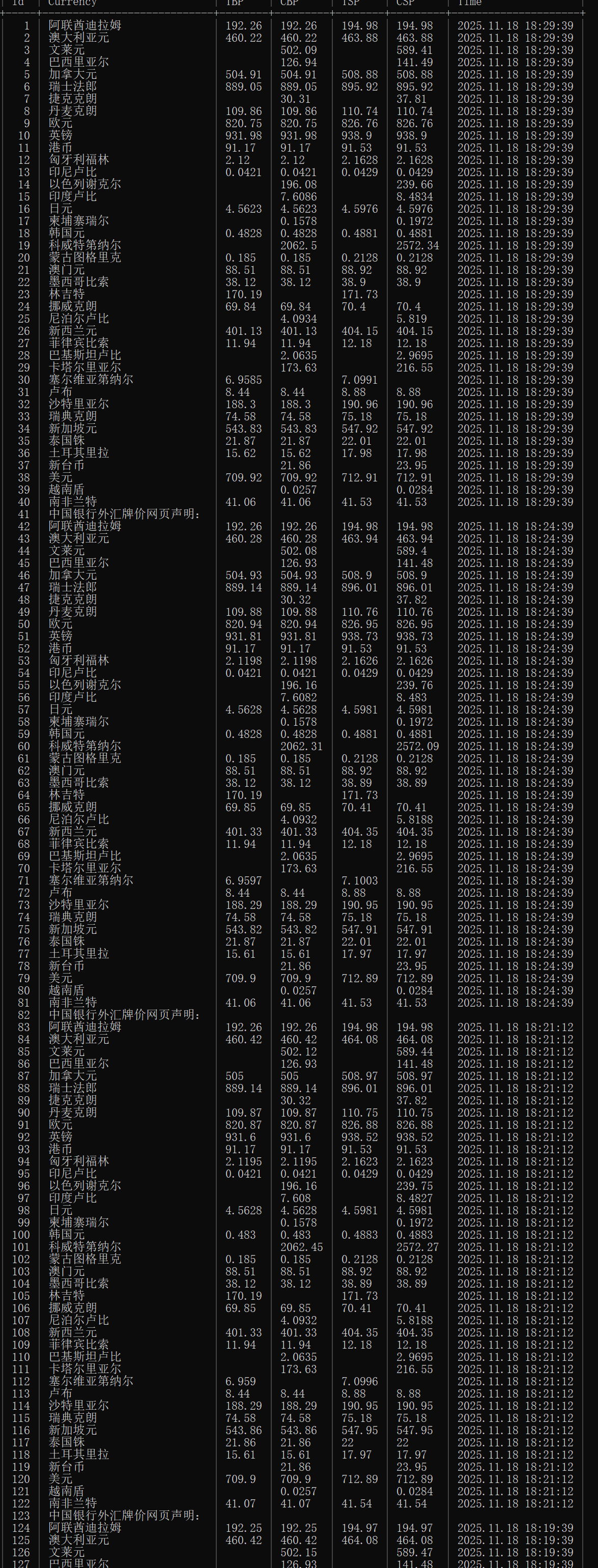
心得体会:
这次实验让我加深了对scrapy爬虫方法的理解,能够更加从容地应对基本的爬虫问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号