


scrapy模拟登录2018新版知乎
由于2018知乎改版,增加了几个登录所需要的post_data,让我这个初出茅庐的小白头疼了几天,经过一番search(github和各种大佬的博客),最终成功的模拟登录的2018新版知乎。
方法如下:
1.谷歌浏览器,打开知乎登录页面,F12打开调试,F5刷新,选中Network,输入账号,错误的密码(正确的密码登录成功直接跳到主页了就无法分析登录的请求了),观察登录的过程中提交了哪些请求
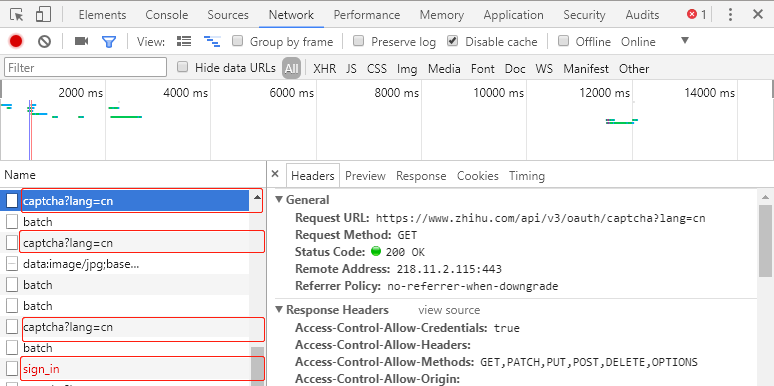
主要就是上图中4个请求
(1)第一个是一个GET请求,查看他的response是一个json格式的数据,show_captcha为true表示需要验证码,false为不需要

(2)第二个是一个PUT请求,这次请求得到了验证码的base64码,解码后可得到一张带有字母的图片验证码

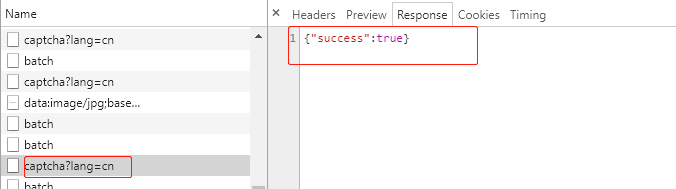
(3)第三个是一个POST请求,表示服务器的验证结果是否正确,如果为true,表示验证成功,可以进行最后一个登陆请求了
(4)最后一个为登陆请求(POST),就是登陆请求了,新版知乎的登录post数据变成了Request Payload,比以前复杂了许多

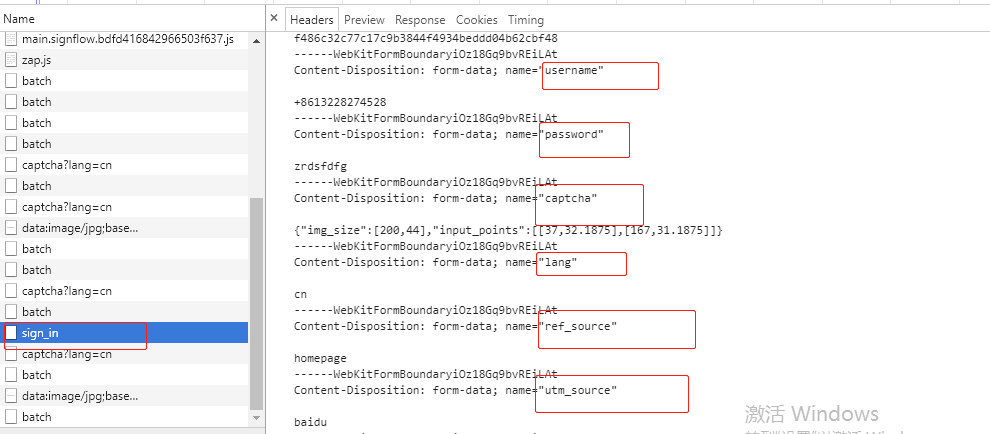
发送请求的时候带上这些数据就可以啦。其中signature和timestamp较为复杂,signature是通过js加密过的(通过ctrl+alt+F搜索signature),可用python模拟js加密过程获得signature的值,timestamp为13位的时间戳。client_id和request header中的authorization后面部分是一样的。
2.下面附上整体代码:
1 # -*- coding: utf-8 -*- 2 __author__ = 'Mark' 3 __date__ = '2018/4/15 10:18' 4 5 import hmac 6 import json 7 import scrapy 8 import time 9 import base64 10 from hashlib import sha1 11 12 13 class ZhihuLoginSpider(scrapy.Spider): 14 name = 'zhihu03' 15 allowed_domains = ['www.zhihu.com'] 16 start_urls = ['http://www.zhihu.com/'] 17 agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' 18 # agent = 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36' 19 headers = { 20 'Connection': 'keep-alive', 21 'Host': 'www.zhihu.com', 22 'Referer': 'https://www.zhihu.com/signup?next=%2F', 23 'User-Agent': agent, 24 'authorization': 'oauth c3cef7c66a1843f8b3a9e6a1e3160e20' 25 } 26 grant_type = 'password' 27 client_id = 'c3cef7c66a1843f8b3a9e6a1e3160e20' 28 source = 'com.zhihu.web' 29 timestamp = str(int(time.time() * 1000)) 30 timestamp2 = str(time.time() * 1000) 31 print(timestamp2) 32 33 def get_signature(self, grant_type, client_id, source, timestamp): 34 """处理签名""" 35 hm = hmac.new(b'd1b964811afb40118a12068ff74a12f4', None, sha1) 36 hm.update(str.encode(grant_type)) 37 hm.update(str.encode(client_id)) 38 hm.update(str.encode(source)) 39 hm.update(str.encode(timestamp)) 40 return str(hm.hexdigest()) 41 42 def parse(self, response): 43 print(response.body.decode("utf-8")) 44 45 def start_requests(self): 46 yield scrapy.Request('https://www.zhihu.com/api/v3/oauth/captcha?lang=en', 47 headers=self.headers, callback=self.is_need_capture) 48 49 def is_need_capture(self, response): 50 print(response.text) 51 need_cap = json.loads(response.body)['show_captcha'] 52 print(need_cap) 53 54 if need_cap: 55 print('需要验证码') 56 yield scrapy.Request( 57 url='https://www.zhihu.com/api/v3/oauth/captcha?lang=en', 58 headers=self.headers, 59 callback=self.capture, 60 method='PUT' 61 ) 62 else: 63 print('不需要验证码') 64 post_url = 'https://www.zhihu.com/api/v3/oauth/sign_in' 65 post_data = { 66 "client_id": self.client_id, 67 "username": "***********", # 输入知乎用户名 68 "password": "***********", # 输入知乎密码 69 "grant_type": self.grant_type, 70 "source": self.source, 71 "timestamp": self.timestamp, 72 "signature": self.get_signature(self.grant_type, self.client_id, self.source, self.timestamp), # 获取签名 73 "lang": "en", 74 "ref_source": "homepage", 75 "captcha": '', 76 "utm_source": "baidu" 77 } 78 yield scrapy.FormRequest( 79 url=post_url, 80 formdata=post_data, 81 headers=self.headers, 82 callback=self.check_login 83 ) 84 # yield scrapy.Request('https://www.zhihu.com/captcha.gif?r=%d&type=login' % (time.time() * 1000), 85 # headers=self.headers, callback=self.capture, meta={"resp": response}) 86 # yield scrapy.Request('https://www.zhihu.com/api/v3/oauth/captcha?lang=en', 87 # headers=self.headers, callback=self.capture, meta={"resp": response},dont_filter=True) 88 89 def capture(self, response): 90 # print(response.body) 91 try: 92 img = json.loads(response.body)['img_base64'] 93 except ValueError: 94 print('获取img_base64的值失败!') 95 else: 96 img = img.encode('utf8') 97 img_data = base64.b64decode(img) 98 99 with open('zhihu03.gif', 'wb') as f: 100 f.write(img_data) 101 f.close() 102 captcha = input('请输入验证码:') 103 post_data = { 104 'input_text': captcha 105 } 106 yield scrapy.FormRequest( 107 url='https://www.zhihu.com/api/v3/oauth/captcha?lang=en', 108 formdata=post_data, 109 callback=self.captcha_login, 110 headers=self.headers 111 ) 112 113 def captcha_login(self, response): 114 try: 115 cap_result = json.loads(response.body)['success'] 116 print(cap_result) 117 except ValueError: 118 print('关于验证码的POST请求响应失败!') 119 else: 120 if cap_result: 121 print('验证成功!') 122 post_url = 'https://www.zhihu.com/api/v3/oauth/sign_in' 123 post_data = { 124 "client_id": self.client_id, 125 "username": "***********", # 输入知乎用户名 126 "password": "***********", # 输入知乎密码 127 "grant_type": self.grant_type, 128 "source": self.source, 129 "timestamp": self.timestamp, 130 "signature": self.get_signature(self.grant_type, self.client_id, self.source, self.timestamp), # 获取签名 131 "lang": "en", 132 "ref_source": "homepage", 133 "captcha": '', 134 "utm_source": "" 135 } 136 headers = self.headers 137 headers.update({ 138 'Origin': 'https://www.zhihu.com', 139 'Pragma': 'no - cache', 140 'Cache-Control': 'no - cache' 141 }) 142 yield scrapy.FormRequest( 143 url=post_url, 144 formdata=post_data, 145 headers=headers, 146 callback=self.check_login 147 ) 148 149 def check_login(self, response): 150 # 验证是否登录成功 151 text_json = json.loads(response.text) 152 print(text_json) 153 yield scrapy.Request('https://www.zhihu.com/inbox', headers=self.headers)
3.经过多番挣扎,此次模拟登录新版知乎终于成功,给自己上了一课,还有好多好多需要学习,一起加油吧!
注:
最后调试过程中出现的问题:
(1)验证码票据问题:setting.py文件,设置
COOKIES_ENABLED = True
(2)输入验证码最后检查登录是否成功浏览器时出现500错误,本以为是user-agent的问题,各种设置后发现还是没用,最后经调试发现是自己的timestamp值提交错了

应该先取整然后再转成字符串,写代码一定要仔细仔细仔细啊!!!我是真的皮。。。
参考链接:
https://zhuanlan.zhihu.com/p/34073256
http://www.bubuko.com/infodetail-2485207.html
https://github.com/zkqiang/Zhihu-Login/blob/master/zhihu_login.py
https://github.com/superdicdi/zhihu_login/blob/master/ZhiHu/spiders/zhihu_login.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号