
碰巧今天遇到两个业务询问关于字符集和排序规则的问题,本次就研究下这个
具体的问题如下
问题1:
CREATE TABLE IF NOT EXISTS `t_todo_file` ( `id` int(11) NOT NULL AUTO_INCREMENT, .... PRIMARY KEY (`id`), KEY `status` (`status`), ... ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
报错如下:(本报错是建表预检查系统报错,具体原因不用在意)
{"status": -1,
"info": "表 t_todo_file 的字符集未通过检测!校对字符集为: utf8mb4_0900_ai_ci"}
解决:修改为default charest=utf8mb4 collate=utf8mb4_unicode_ci
问题2:
问:字段的varchar的编码默认是和table相同还是和库相同?
答:和表相同
问:有个表是utf8的,写进去sql是utf8的,但是读的时候是乱码,必须用set name latin1后,查询才是正常的,这是为什么?
答:如图所示:
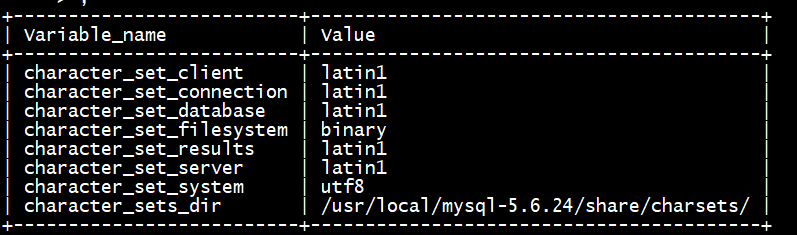
其中的character_set_results 参数是latin1,这个参数是数据库返回给客户端时使用的编码格式
问:那set name utf8后,是不是连接和返回的结果集编码都会改?
答:set name是客户端操作,不会影响服务端,也不能影响服务端
问:那为啥set name latin1后,再select 查询就不显示乱码了呢?
答:可能是你的客户端默认编码的utf8,无法识别latin1的数据,所以需要显示设置为latin1
首先要先明确,什么是字符集,什么是排序规则已经他们之间的关系
字符集是一组抽象字符组合的集合,是一套符号和编码规则,通过符号的组合来表示我们所熟悉的文字,常见的有的字符集有UTF8,gbk,Latin1等
排序规则是指对字符集中字符串进行的比较,排序规则。比如utf8字符集的排序规则有utf8mb4_unicode_ci ,utf8mb4_0900_ai_ci(MySQL8.0之后支持)等。
为什么一个字符集会有多种的排序规则,难道排序规则会变么?首先排序规则确实会变,比如是是否区分大小写,以_ci结尾的不区分大小写,以_cs结尾的区分大小写。还有排序速度的差异,utf8_general_ci校对速度快,但准确度稍差。utf8_unicode_ci准确度高,但校对速度稍慢,所以要根据需求选择不同的排序规则。
我们常用的字符集是utf8么? 是utf8mb4,由于utf8是3字节的,绝大多数情况下能够存在大部分的中文汉字,但一些特殊的字符,比如emoji表情就无法保存,故增加了utf8mb4字符集,他是utf8的超集,有4个字节,可以存下所有的中文。除非能明确不会有utf8不能保存的字符并且为了节省空间的场景,不然一般默认使用utf8mb4(还有一种情况就是业务习惯使用)
第一个问题是为什么会报错? 因为utf8mb4_0900_ai_ci是mysql8.0才支持的排序规则,而业务的实例的5.6.24的。
MySQL中的字符集是如何设计的
mysql设置了7条规则用于确定字符集
(1)编译MySQL 时,指定了一个MySQL默认的字符集,这个字符集是 latin1;
(2)安装MySQL 时,可以在配置文件 (my.ini) 中指定一个默认的的字符集,如果没指定,这个值继承自编译时指定的;
(3)启动mysql 时,可以在命令行参数中指定一个默认的的字符集,如果没指定,这个值继承自配置文件中的配置,此时 character_set_server 被设定为这个默认的字符集;
(4)当创建一个新的数据库时,除非明确指定,这个数据库的字符集被缺省设定为character_set_server;
(5)当选定了一个数据库时,character_set_database 被设定为这个数据库默认的字符集;
(6)在这个数据库里创建一张表时,表默认的字符集被设定为 character_set_database,也就是这个数据库默认的字符集;
(7)当在表内设置一栏时,除非明确指定,否则此栏缺省的字符集就是表默认的字符集;
类似优先级,7优先级最高,1最低
问题2图中参数分别代表什么
一、character_set_client
主要用来设置客户端使用的字符集。
二、character_set_connection
主要用来设置连接数据库时的字符集,如果程序中没有指明连接数据库使用的字符集类型则按照这个字符集设置。
三、character_set_database
主要用来设置默认创建数据库的编码格式,如果在创建数据库时没有设置编码格式,就按照这个格式设置。
四、character_set_filesystem
文件系统的编码格式,把操作系统上的文件名转化成此字符集,即把 character_set_client转换character_set_filesystem, 默认binary是不做任何转换的。
五、character_set_results
数据库给客户端返回时使用的编码格式,如果没有指明,使用服务器默认的编码格式。
六、character_set_server
服务器安装时指定的默认编码格式,这个变量建议由系统自己管理,不要人为定义。
七、character_set_system
数据库系统使用的编码格式,这个值一直是utf8,不需要设置,它是为存储系统元数据的编码格式。
八、character_sets_dir
这个变量是字符集安装的目录。
以上红色条目无需在意
如何修改字符集
可以通过alter table xxx character set xxxx 或者alter database xxx character set xxxx,但是这样修改字符集是不影响存量数据,只变更增量数据。如果想修改存量数据,可以采用按指定字符集导出再导入的方式
set names xxx做了什么
set names xxx实际上相当于重新设置了 character_set_client,character_set_connection,character_set_results,每次连接数据库都需要执行一遍,所以问题2中业务可用通过此方法解决乱码问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号