

undo log 即重做日志,记录了事务的行为,在事务执行失败\回滚时。可以利用undolog将数据回滚到之前的状态,此外mvcc也是通过undo log实现。
之前说过redo log是放在ib_logfile里的,undo log是放在共享表空间,即ibdata1里(8.0 将undo 单独拿出来放在undo_001~003里)
redolog是记录的页的修改记录,是物理记录,而undo log是逻辑记录,比如insert的undo就是delete,update的undo也是update,所以undo是逻辑上将数据恢复,恢复后的数据页和之前的页记录是不一样的,这个redolog不同
undo log有几种格式? undo log分为两种格式 insert undo log 和update undo log,其中insert 操作的记录只对事务本身可见,对其他事务不可见(隔离),故在事务提交后,undo log可以直接删除。而update/delete 操作产生的undo log需要支持MVCC,故不能立刻删除,需要放入undo log链表,由purge线程判断删除
undo log何时删除? 当事务提交时,innodb会做两件事,1,将undo log放入链表,以供之后的purge操作,2判断undo log所在的页是否可以重用,若可以分配给下个事务使用。事务提交后,是不能立刻删除undo log和undo log所在的页,因为可能还有其他事务需要通过undo获得之前版本的数据(MVCC),所以是将undo log放到一个链表里,删除操作由purge线程执行
undo log 如何写入链表?对我们而言,大部分是OLTP应用,特点是产生的undo log多且小,所以如果一个undo页只放一个事务的undo log,会产生大量浪费,很容易打满磁盘,故在写入undo log时,会判断当前页的剩余容量是否超过3/4,是则将此页视为空,可以继续顺序写入
purge线程作用是?当我们执行update/delete 操作时,实际上不会执行真正的删除操作,本质是在相应的主键上将delete flag置为1,所有索引树上的数据都没有变化,甚至没有生成undo log。真正的操作要等到purge线程延时处理。
为什么要有purge线程,不能实时处理么?因为需要支持MVCC,数据在事务1进行了变更/删除,但是可能事务2还需要读取历史的数据,所以不能实时处理。需要等到所有可能读到该数据的事务都提交后,才能调用purge线程清理/变更数据。这个时间点大概是,所有在事务1提交前开启的事务都已经提交,事务id本身时有序递增的,只需要简单的判断即可。
purge线程怎么做?
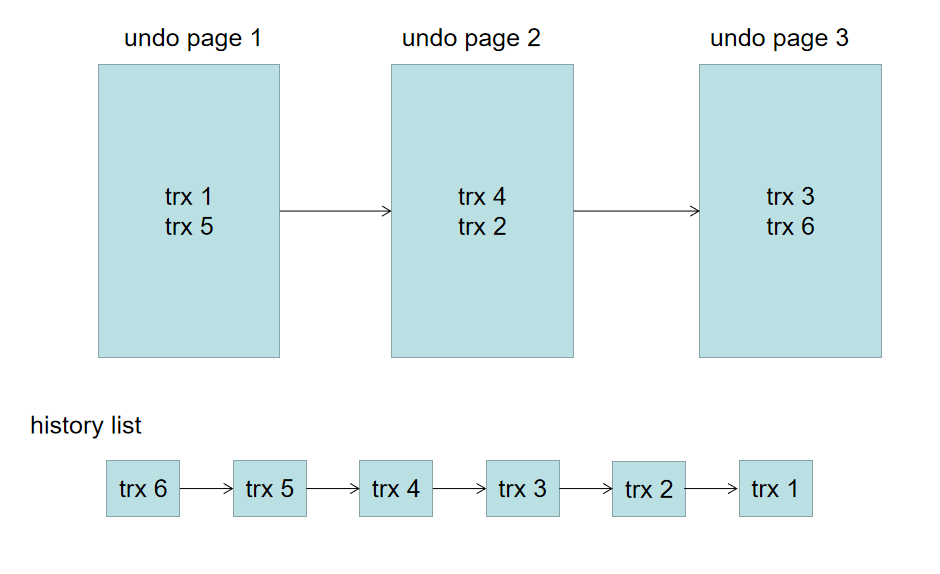
结合图说明,innodb引擎维护了一个链表,他根据事务的提交顺序,来连接undo log,如上图history list 所示。但是undo log落到undo page上是“见缝插针”的,所以在图中的3个undo page上是无序的。当开始purge时,purge线程会现根据history list链表找到最早提交的事务trx1,然后判断是否可删除,可删除则去相应的undo page(为undo page 1)删除 trx1 的undo log,然后purge会在undo page 1上顺序查找其他事务的undo log,如果能删除就一起删除。如果不能,比如trx 5的数据还有可能被引用,就重复之前的流程,去找history list 最后的事务(此为trx 2)。如果一个undo page 上的数据都被删完了,即刻复用。
为何要使用这种看似麻烦的方式呢,这是为了尽可能的将随机读转换为顺序读,提升purge的效率。每次purge需要清理的undo page数量由innodb_purge_batch_size控制,但不建议修改此参数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号