
2019OO第三单元总结
一、JML语言理论基础和应用工具链
JML是一种形式化的、面向Java的行为接口规格语言。JML以javadoc注释的方式来表示规格,每行都以@起头。
requires子句定义该方法的前置条件
assignable列出这个方法能够修改的类成员属性
ensures子句定义了后置条件
signals子句的结构为signals (***Exception e) b_expr ,意思是当b_expr 为true 时,方法会抛出括号中给出的相应异常e
\result表示返回值
\old(expression)表示expression在进入方法之前的值
\forall表示全称量词
\exists表示存在量词
normal_behavior和exception_behavior区分正常和异常
JML相关的工具主要有OpenJML和JMLUnitNG,OpenJML用来检查JML语法的正确性,JMLUnitNG用于单元测试。
二、使用JMLUnitNG
这里使用一个简单的例子来说明JMLUnitNG的用法。
假设src文件夹下有demo.java,内容如下:
public class Demo {
/*@ public normal_behaviour
@ ensures \result == lhs - rhs;
*/
public static int compare(int lhs, int rhs) {
return lhs - rhs;
}
public static void main(String[] args) {
compare(114514,1919810);
}
}
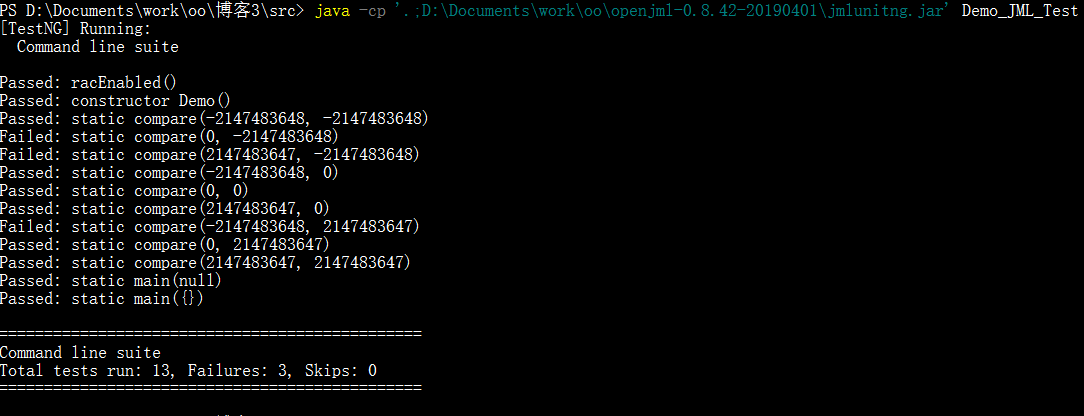
在PowerShell下,执行(请根据自己的实际情况,对jar包的路径进行修改)
java -jar D:\Documents\work\oo\openjml-0.8.42-20190401\jmlunitng.jar demo.java
javac -cp D:\Documents\work\oo\openjml-0.8.42-20190401\jmlunitng.jar (dir . -recurse -name *.java)
java -jar D:\Documents\work\oo\openjml-0.8.42-20190401\openjml.jar -rac demo.java
java -cp '.;D:\Documents\work\oo\openjml-0.8.42-20190401\jmlunitng.jar' Demo_JML_Test
可以看到运行结果
三、作业分析
第一次作业:
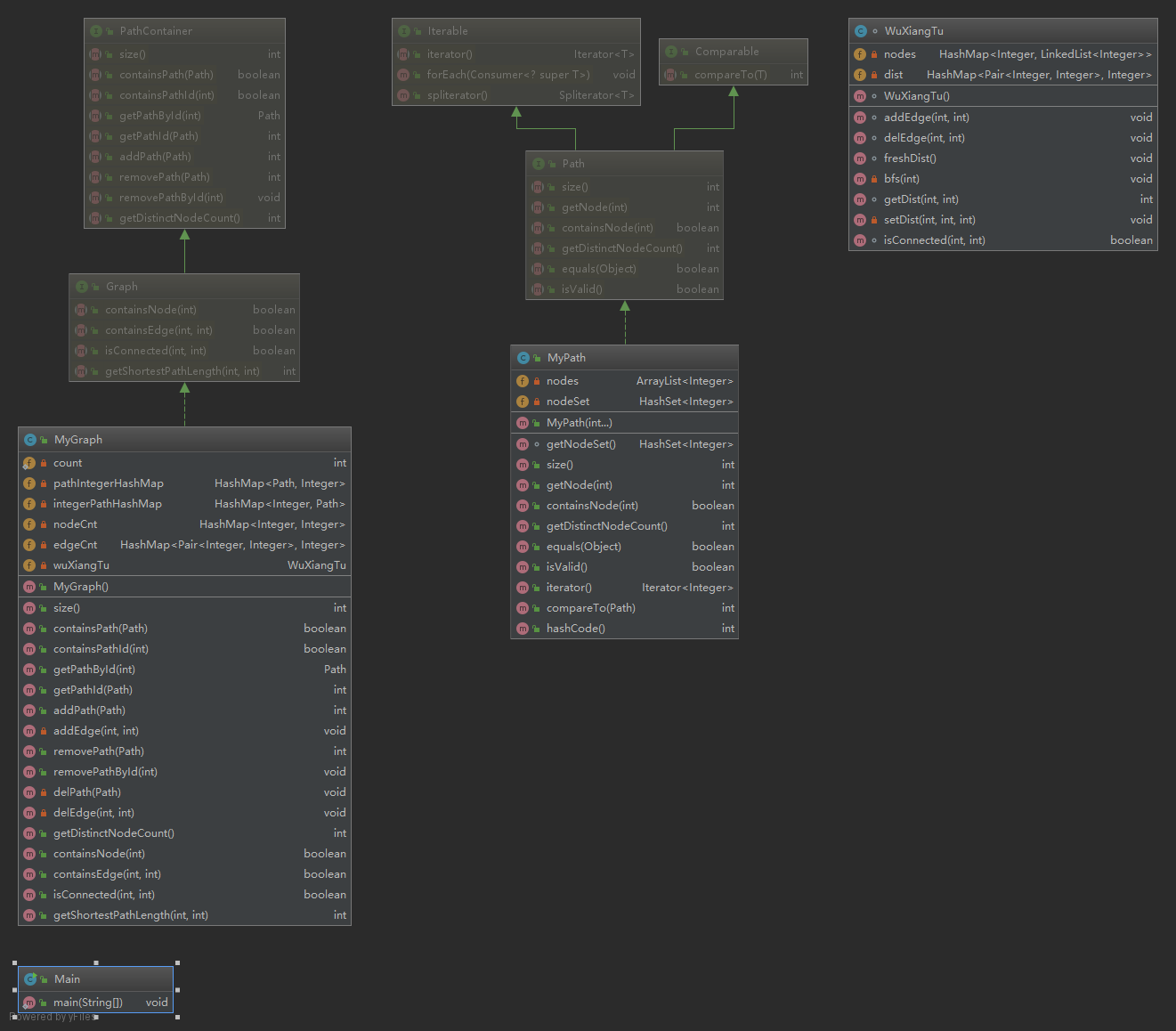
难点在于pathId和path的对应,因此我使用了两个HashMap,一个是HashMap<Integer, Path>,一个是HashMap<Path, Integer>,这样可以进行双向查询,由于HashMap通过key来查找value的时间复杂度很低,通过这种方式可以有效降低时间复杂度。
对于PATH_DISTINCT_NODE_COUNT指令,可以把当前path中所有结点的号存入HashSet中,在通过这条指令查询的时候直接返回该HashSet的size即可。
对于DISTINCT_NODE_COUNT指令,可以使用HashMap<Integer, Integer>,让结点的号和它在PathContainer中出现次数进行对应,增加path的时候让出现次数加一,删除path的时候让出现次数减一(如果减到0的时候删除key为pathid的映射),在通过这条指令查询的时候直接返回该HashMap的size即可。

第二次作业:
相比第一次作业而言,难度略有提升,主要是要查询两个结点之间的最短路径,因此需要用到无向图数据结构,我使用邻接表的方式存图;由于两个点之间的距离是1,使用BFS算法就能解决问题。
由于测试用例中图结构变更指令(增加、删除path)很少,很多指令都是查询类指令(查两个点是否连通、两个点最短距离之类的),因此我考虑了缓存机制,缓存的结构为HashMap<Pair<起点id, 终点id>, 距离>,用来避免多次进行BFS计算,在变更图结构之前缓存是一直有效的,只有在缓存中查不到的时候才进行BFS。
在执行bfs(fromNodeId)的时候(其中fromNodeId是起点),每遍历到点v,能得到fromNodeId到v的最短路径dist,并存入缓存中。
第三次作业:
需要实现地铁系统的各个查询功能,可以查询两个点之间的最少票价、最少换乘次数、最少不舒适度,但其实本质上和第二次作业差不多,就是各种求最短路径,只不过是“距离”不一样,此时我使用了Dijkstra算法,通过优先队列优化。
第二次作业使用的无向图结构可以继续沿用,只是需要记录一下两个点之间通过几号线连接;缓存机制修改了一下,改为HashMap<起点id, HashMap<终点id, 距离> >。
但是这次的难点就是,通过p1号线到u点,和通过p2号线到u点,是不一样的!因此我用到了“拆点”的方法,不妨在计算的时候考虑把u点“拆开”,拆成up1点和up2点(其中up代表通过p号线到u点)。因此计算最低票价(s代表起点)的大概步骤就是:
1. 到s0的票价为-2,入队(该算法认为从起点开始坐p号线,就是从0号线换乘到p号线,所以平白多了2块钱,在这里先把这两块钱减去)
2. 从优先队列中抽出票价最小的up(距离为c),标记up,更新缓存(如果这个c比缓存中记录更小的话)
3. 对于与u相邻的点vq而言,若vq没有被标记,认为到vq的票价为c+1+((p!=q)?2:0),入队。重复进行2,3步
对于其他的“距离”,也是用类似的做法。

四、bug的情况
这三次作业在强测和互测中都没有被发现bug。
五、心得体会
这几次作业,需要用到很多新东西(比如OpenJML,JMLUnitNG),写起来感觉也有点接近实际工程(特别注重严密性),主要感受就是JML有点像大一数分课上使用的数学语言,JML说了那么一堆(自己看着也是比较费劲),但实际上就是求一个最短路径而已。虽然麻烦了一点,但对于bug的发现、自动化测试还是有很大的帮助,代码更接近未来的实际工程,因此JML这一单元对我也是受益匪浅的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号