
读书笔记——《图解HTTP》(一)
第一章 了解Web及网络基础
- http的诞生:
- http0.9为1990年问世,由于没有正式标准建立,从而成为http1.0的前身,为http0.9
- http1.0为1996年正式发布,为最初的标准协议。
- http1.1为1997年正式发布,为目前最主流的协议版本。
- http2.0正在制定中。。。
- TCP/IP:
分为4层:应用层、传输层、网络层、数据链路层。
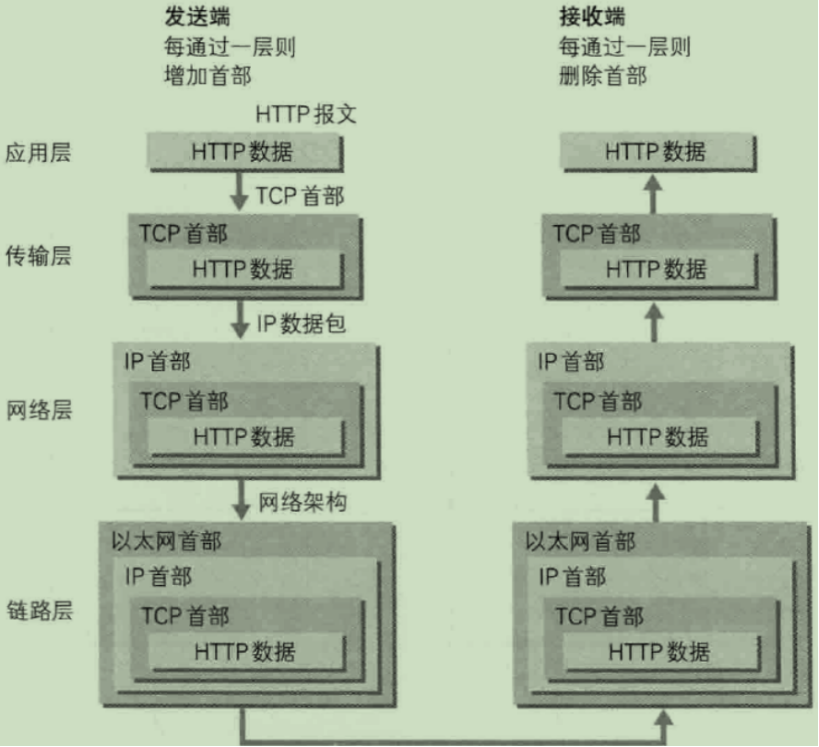
每一层必须打上上一层的首部。
- URI:
URI用字符串标识某一互联网资源,而URL表示资源的地点(互联网上所处的位置)。可见URL是URI的子集。
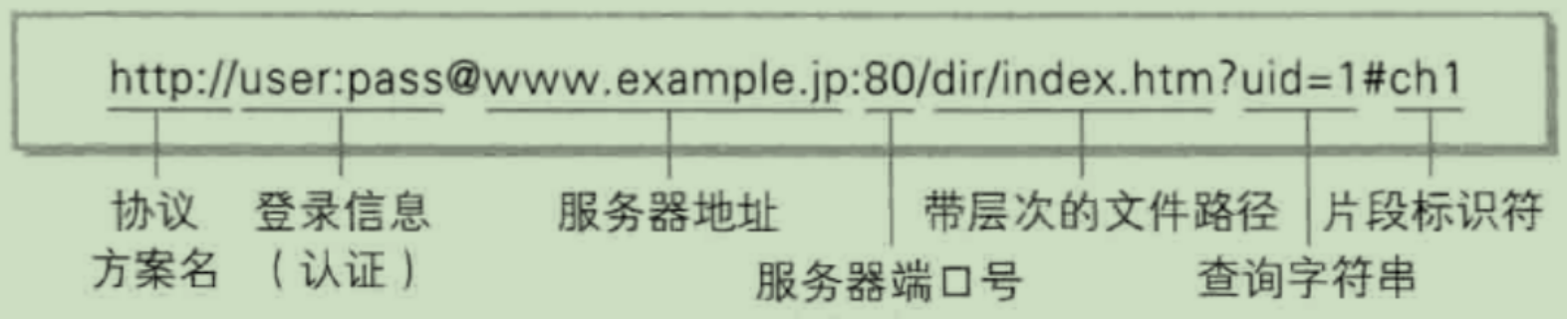
绝对URI格式:
- 使用http:
或https:等协议方案名获取访问资源时要指定协议类型。不区分字母大小写,最后附一个冒号:。也可使用data:或javascript:这类指定数据或脚本程序的方案名。
- 登录信息(认证)
指定用户名和密码作为从服务器端获取资源时必要的登录信息(身份认证)。此项是可选项。
- 服务器地址
使用绝对URI必须指定待访问的服务器地址。地址可以是类似hackr.jp这种DNS可解析的名称,或是192.168.1.1这类IPv4地址名,还可以是[0:0:0:0:0:0:0:1]这样用方括号括起来的Pv6地址名。
- 服务器端口
指定服务器连接的网络端口号。此项也是可选项,若用户省略则自动使用默认端口号。带层次的文件路径。指定服务器上的文件路径来定位特指的资源。这与UNIX系统的文件目录结构相似。
- 带层次的文件路径
指定服务器上的文件路径来定位特指的资源。这与UNIX系统的文件目录结构相似。
- 查询字符串
针对已指定的文件路径内的资源,可以使用查询字符串传入任意参数。此项可选。
- 片段标识符
使用片段标识符通常可标记出已获取资源中的子资源(文档内的某个位置)。但在RFC中并没有明确规定其使用方法。该项也为可选项。
第二章 简单的HTTP协议
查看网页header部分:
F12后进入开发者模式,然后选中All,然后F5刷新网页,在name中随便打开一个,就可以打开其相关的Headers信息了。
·HTTP是一种不保存状态,即无状态(stateless)协议。HTTP协议自身不对请求和响应之间的通信状态进行保存。也就是说在HTTP这个级别,协议对于发送过的请求或响应都不做持久化处理。现在使用Cookie技术来达到一个处理状态的。
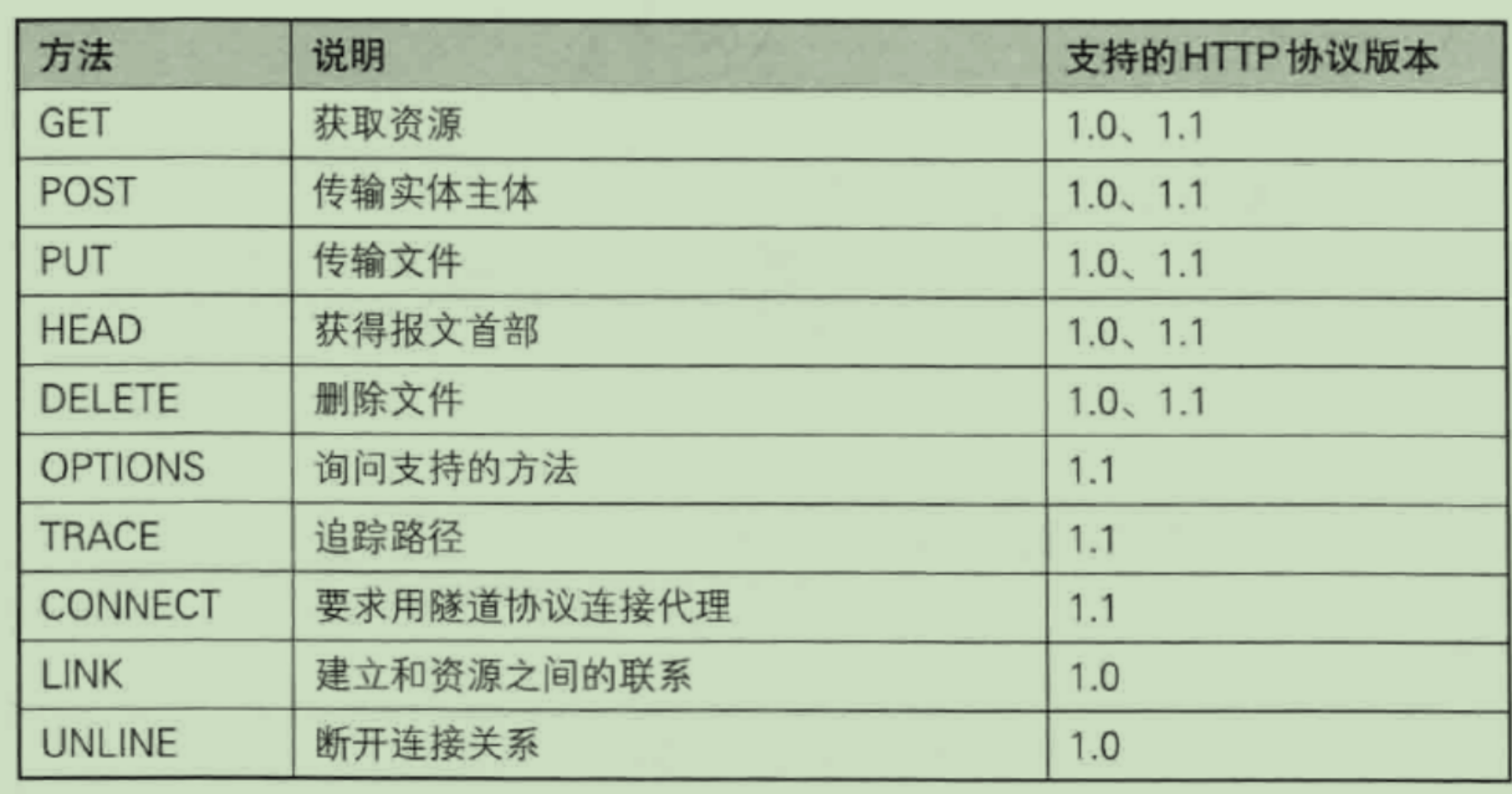
- GET:获取资源
GET方法用来请求访问已被URI识别的资源。指定的资源经服务器端解析后返回响应内容。也就是说,如果请求的资源是文本,那就保持原样返回;如果是像CGl(Common Gateway Interface,通用网关接口)那样的程序,则返回经过执行后的输出结果。

- POST:传输实体主体
POST方法用来传输实体的主体。虽然用GET方法也可以传输实体的主体,但一般不用GET方法进行传输,而是用POST方法。虽说POST的功能与GET很相似,但POST的主要目的并不是获取响应的主体内容。

- PUT:传输文件
PUT方法用来传输文件。就像FTP协议的文件上传一样,要求在请求报文的主体中包含文件内容,然后保存到请求URI指定的位置。但是,鉴于HTTP/1.1的PUT方法自身不带验证机制,任何人都可以上传文件,存在安全性问题,因此一般的Web网站不使用该方法。若配合Web应用程序的验证机制,或架构设计采用REST (REpresentational State Transfer,表征状态转移)标准的同类Web网站,就可能会开放使用PUT方法。

- HEAD:获得报文首部
HEAD方法和GET方法一样,只是不返回报文主体部分。用于确认URI的有效性及资源更新的日期时间等。

- DELETE:删除文件
DELETE方法用来删除文件,是与PUT相反的方法。DELETE方法按请求URI删除指定的资源。但是,HTTP/1.1的DELETE方法本身和PUT方法一样不带验证机制,所以一般的Web网站也不使用DELETE方法。当配合Web应用程序的验证机制,或遵守REST标准时还是有可能会开放使用的。

- OPTIONS:询问支持的方法
OPTIONS方法用来查询针对请求URI指定的资源支持的方法。

- TRACE:追踪路径
TRACE方法是让Web服务器端将之前的请求通信环回给客户端的方法。
发送请求时,在Max-Forwards首部字段中填入数值,每经过一个服务器端就将该数字减1,当数值刚好减到0时,就停止继续传输,最后接收到请求的服务器端则返回状态码200OK的响应。
客户端通过TRACE方法可以查询发送出去的请求是怎样被加工修改/篡改的。这是因为,请求想要连接到源目标服务器可能会通过代理中转,TRACE方法就是用来确认连接过程中发生的一系列操作。
但是,TRACE方法本来就不怎么常用,再加上它容易引发XST
(Cross-Site Tracing,跨站追踪)攻击,通常就更不会用到了。

- CONNECT:要求用隧道协议连接代理
CONNECT方法要求在与代理服务器通信时建立隧道,实现用隧道协议进行TCP通信。主要使用SSL(Secure Sockets Layer,安全套接层)和TLS(Transport Layer Security,传输层安全)协议把通信内容加密后经网络隧道传输。
CONNECT方法的格式如下所示。

- 持久连接:
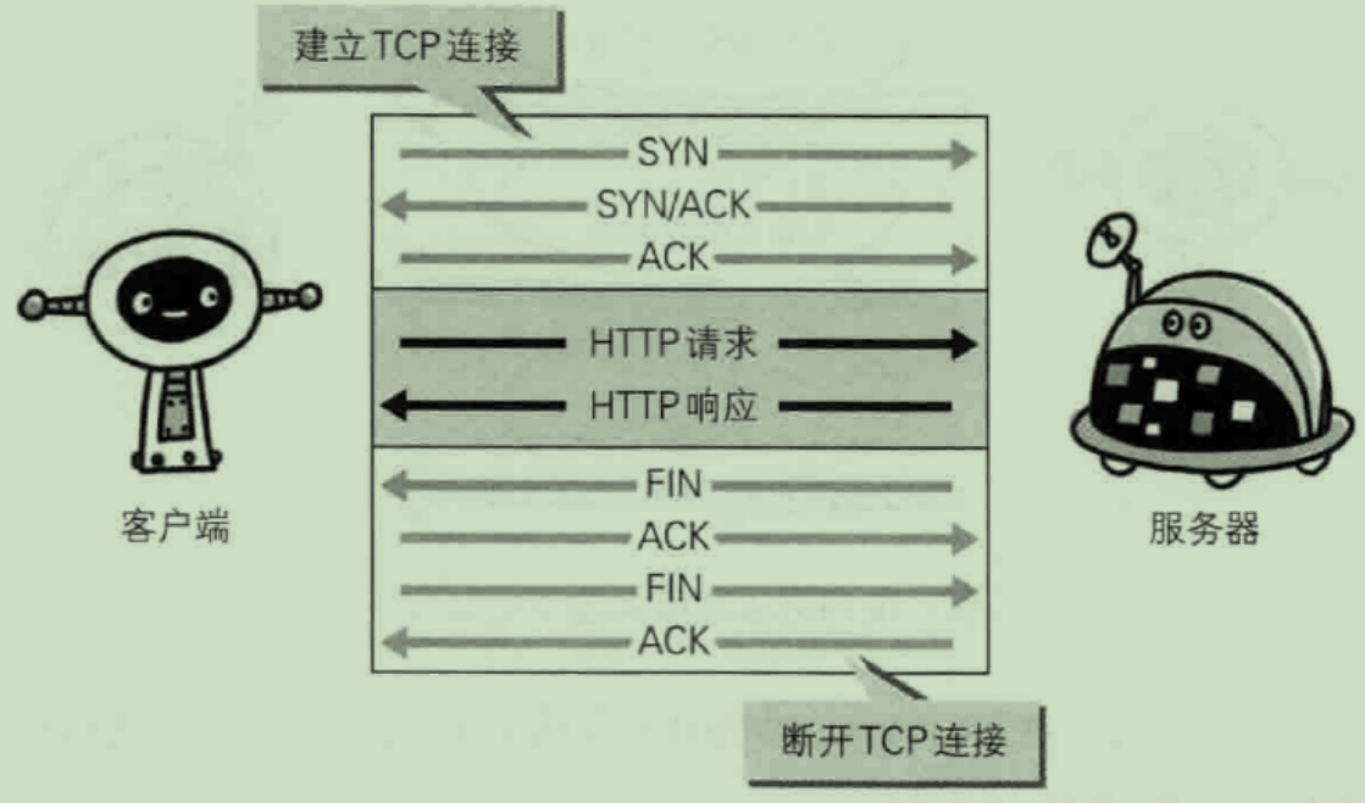
HTTP协议的初始版本中,每进行一次HTTP通信就要断开一TCP连接。
- 持久连接:
为解决上述TCP连接的问题,HTTP/1.1和一部分的HTTP/1.0想出了持久连接(HTTP Persistent Connections,也称为HTTP keep-alive或HTTP connection reuse)的方法。持久连接的特点是,只要任意一端没有明确提出断开连接,则保持TCP连接状态。
在HTTP/1.1中,所有的连接默认都是持久连接,但在HTTP/1.0内并未标准化。虽然有一部分服务器通过非标准的手段实现了持久连接,但服务器端不一定能够支持持久连接。毫无疑问,除了服务器端,客户端也需要支持持久连接。
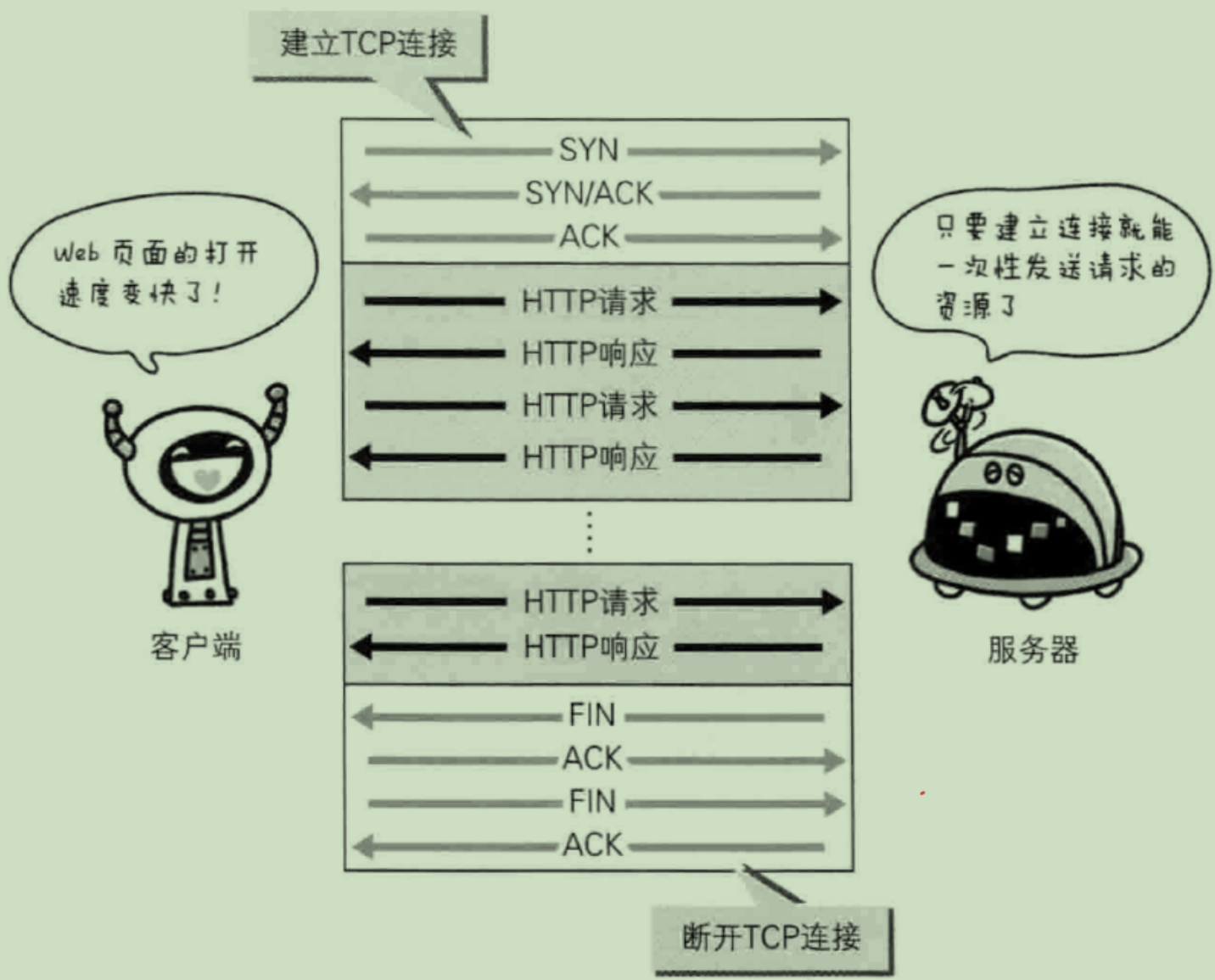
- 管线化:
持久连接使得多数请求以管线化(pipelining)方式发送成为可能。
从前发送请求后需等待并收到响应,才能发送下一个请求。管线化技术出现后,不用等待响应亦可直接发送下一个请求。
这样就能够做到同时并行发送多个请求,而不需要一个接一个地等待响应了。

- 使用Cookie:
HTTP是无状态协议,它不对之前发生过的请求和响应的状态进行管理。也就是说,无法根据之前的状态进行本次的请求处理。
假设要求登录认证的Web页面本身无法进行状态的管理(不记录已登录的状态),那么每次跳转新页面不是要再次登录,就是要在每次请求报文中附加参数来管理登录状态。
保留无状态协议这个特征的同时又要解决类似的矛盾问题,于是引入了Cookie技术。Cookie技术通过在请求和响应报文中写入Cookie信息来控制客户端的状态。
Cookie会根据从服务器端发送的响应报文内的一个叫做 Set-Cookie的首部字段信息,通知客户端保存Cookie。当下次客户端再往该服务器发送请求时,客户端会自动在请求报文中加入Cookie值后发送出去。
服务器端发现客户端发送过来的Cookie后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到之前的状态信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号