消息队列MQ
消息队列MQ
MQ全称为Message Queue 消息队列(MQ)是一种应用程序对应用程序的通信方法。MQ是消费-生产者模型的一个典型的代表,一端往消息队列中不断写入消息,而另一端则可以读取队列中的消息。这样发布者和使用者都不用知道对方的存在。
生产消费模型:
'''
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
'''
我们先不管消息(Message)这个词,来看看队列(Queue)。这一看,队列大家应该都熟悉吧。
队列是一种先进先出的数据结构。

消息队列可以简单理解为:把要传输的数据放在队列中。
为什么要用消息队列?
消息队列中间件是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削锋等问题,实现高性能,高可用,可伸缩和最终一致性架构。目前使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ。
接下来利用一个外卖系统的消息推送给大家解释下MQ的意义。

RabbitMQ
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。
rabbitMQ是一款基于AMQP协议的消息中间件,它能够在应用之间提供可靠的消息传输。在易用性,扩展性,高可用性上表现优秀。使用消息中间件利于应用之间的解耦,生产者(客户端)无需知道消费者(服务端)的存在。而且两端可以使用不同的语言编写,大大提供了灵活性。

rabbitMQ工作模型之简单模式
### 生产者
import pika #导入python与rabbitMQ的包
#连接rabbitMQ
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
#得到连接对象,通过他来操作
channel = connection.channel()
#声明消息队列叫hello
channel.queue_declare(queue='hello')
#往消息队列里插入数据
channel.basic_publish(exchange='', #这是交换机,暂时没有
routing_key='hello', #路由密钥 就是你想在什么消息队列插入数据
body='Hello World!') #body传输的数据
print(" Sent 'Hello World!'")
### 消费者
import pika
#连接rabbitMQ
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
#声明消息队列,至于为什么生产者创建队列,而消费者同时也需要,因为有可能消费者想监听消息队列,但此时生产者还没有声明,如果声明了此句声明就是作废了,所以两边都创建,但是有一个会作废,不影响。防止不知道谁先运行而造成的错误
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
#消费者获取数据
channel.basic_consume(queue='hello', 消息队列的名字
auto_ack=True, 参数,自动应答模式
on_message_callback=callback) 执行回调函数
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() 开始消费,就是跟监听似的,每次获取完数据,从新监听,有数据再拿
参数
应答参数
# auto_ack=False
默认情况下,rabbitmq开启了消息的自动应答。此时,一旦rabbitmq将消息分发给了消费者,就会将消息从内存中删除。这种情况下,如果正在执行的消费者被“杀死”或“崩溃”,就会丢失正在处理的消息。
如果想要确保消息不丢失,我们需要设置消息应答方式为手动应答。设置为手工应答后,消费者接受并处理完一个消息后,会发送应答给rabbitmq,rabbitmq收到应答后,会将该条消息从内存中删除。如果一个消费者在处理消息的过程中“崩溃”,rabbitmq没有收到应答,那么”崩溃“前正在处理的这条消息会重新被分发到别的消费者。
假如使用手动应答模式
# 定义回调函数
def callback(ch, method, properties, body):
print('[x] Recieved %r' % body)
# channel.close()
ch.basic_ack(delivery_tag=method.delivery_tag) 手动应答都放在回调函数的最后一行,就是执行完逻辑之后,手动告知rabbitmq,处理完成。
channel.basic_consume(queue='hello',
auto_ack=False,# 手动应答机制
on_message_callback=callback)
# auto_ack=True 表示消费完以后不主动把状态通知rabbitmq
ch.basic_ack(delivery_tag=method.delivery_tag) 手动应答
#delivery 交付的意思 tag=标签
持久化参数
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 创建一个名为hello的队列
channel.queue_declare(queue='hello2',durable=True)
# 向hello队列插入'Hello World!'
channel.basic_publish(exchange='',
routing_key='hello2',
body='999',
#持久化参数 properties=pika.BasicProperties(
delivery_mode=2, # make message persistent 使其持久化
)
)
print(" [x] Sent 'Hello World!'")
持久化参数是为了防止,rabbitMQ突然崩了,此时队列的数据也会消失,因为是存储内存的,没分配给消费者,消费者应答之后就删除了,而持久化放在磁盘中,队列和其中数据还在。 设置持久化参数即可
分发参数
有两个消费者同时监听一个的队列。其中一个线程sleep2秒,另一个消费者线程sleep1秒,但是处理的消息是一样多。这种方式叫轮询分发(round-robin)不管谁忙,都不会多给消息,总是你一个我一个。想要做到公平分发(fair dispatch),必须关闭自动应答ack,改成手动应答。使用basicQos(perfetch=1)限制每次只发送不超过1条消息到同一个消费者,消费者必须手动反馈告知队列,才会发送下一个。
channel.basic_qos(prefetch_count=1)
#生产者
import pika # pika是python连接rabbitmq的模块
# 连接rabbitmq
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 创建一个名为hello的队列
channel.queue_declare(queue='hello')
# 向hello队列插入'Hello World!'
channel.basic_publish(exchange='',
routing_key='hello',
body='3333333332111')
print(" [x] Sent 'Hello World!'")
#消费者 默认是轮询模式,不管2个消费者性能如何,都轮流给每人一个
如果用公平模式,需手动应答,当消息队列多个数据时,谁先干完,谁继续拿,不是轮流给没人
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
import time
time.sleep(35)
print(" [x] Received %r" % body)
#手动应答
ch.basic_ack(delivery_tag=method.delivery_tag)
# 将轮询分配改为公平分配
channel.basic_qos(prefetch_count=1)
channel.basic_consume(queue='hello',
auto_ack=False,# 手动应答机制
on_message_callback=callback)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
用time.sleep来测试,一个5S,一个25s,然后执行,5s拿的多干的多,因为每5s就拿一个干完继续拿,但25s干完继续拿
感想:每个参数都有每个参数的优势,看你的需求,如果你需求效率就用公平分发,自动应答。如果要数据安全就持久化,手动应答。
交换机模式(exchange)
交换机之发布订阅
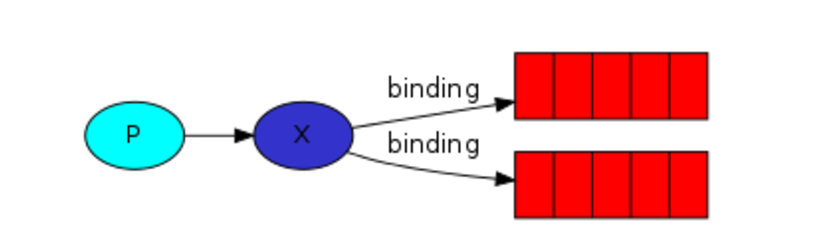
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
# 生产者
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
#声明一个交换机
channel.exchange_declare(exchange='logs', 交换机的名字
exchange_type='fanout') fanout类型,就是交换机得到生产者的消息,然后发给绑定此交换机的消费者的队列中
#发送的内容
message = "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='', 因为是给绑定此交换机的每个都有,所以不需要知道队列的名字
body=message)
print(" [x] Sent %r" % message)
connection.close()
# 消费者
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
exchange_type='fanout')
result = channel.queue_declare("",exclusive=True) #随机创建一个队列
queue_name = result.method.queue
channel.queue_bind(exchange='logs', #绑定交换机
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(queue=queue_name,
auto_ack=True,
on_message_callback=callback)
channel.start_consuming()
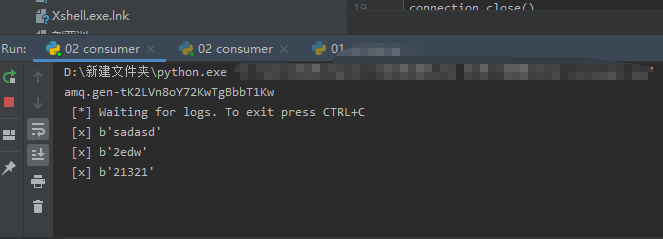
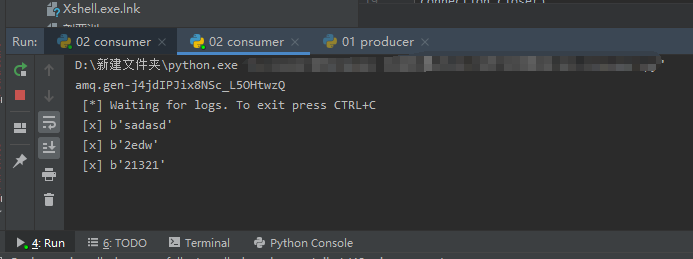
2个消费者的队列各收到来自生产者的数据,消费者创建随机队列,生产者不需要创建队列,创建了交换机,把消息给交换机,交换机给每个绑定他的队列发一份。
交换机之关键字
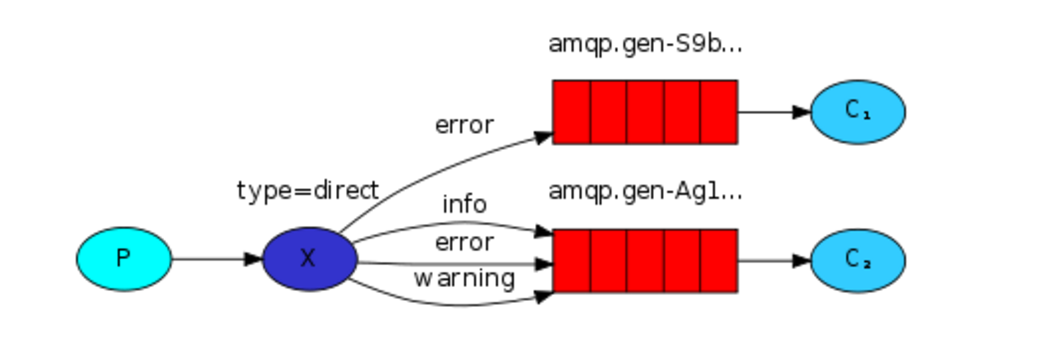
# 生产者
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs2',
exchange_type='direct') #关键字类型
message = "info: Hello Yuan!"
channel.basic_publish(exchange='logs2',
routing_key='info', #通过改变这里,设置关联队列关键字,交换机会把消息发给此名字的消息队列
body=message)
print(" [x] Sent %r" % message)
connection.close()
# 消费者
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# 声明交换机
channel.exchange_declare(exchange='logs2',
exchange_type='direct') # direct:关键字
# 创建队列,名为随机字符串
result = channel.queue_declare("",exclusive=True)
queue_name = result.method.queue
print(queue_name)
# 将队列绑定到某个交换机上
channel.queue_bind(exchange='logs2',
queue=queue_name,
routing_key="adsd" #这是绑定到交换得队列关键字,交换机就是通过关键字是否一致来判断发消息给队列
)
print(' [*] Waiting for logs. To exit press CTRL+C')
生产者得声明交换机以及模式exchange_type='direct',
channel.basic_publish(exchange='logs2',
routing_key='info', 这是生产者传消息,告知交换机给指定关键字为info得队列, body=message)
交换机之通配符
通配符交换机”与之前的路由模式相比,它将信息的传输类型的key更加细化,以“key1.key2.keyN....”的模式来指定信息传输的key的大类型和大类型下面的小类型,让消费者可以更加精细的确认自己想要获取的信息类型。而在消费者一段,不用精确的指定具体到哪一个大类型下的小类型的key,而是可以使用类似正则表达式(但与正则表达式规则完全不同)的通配符在指定一定范围或符合某一个字符串匹配规则的key,来获取想要的信息。
“通配符交换机”(Topic Exchange)将路由键和某模式进行匹配。此时队列需要绑定在一个模式上。符号“#”匹配一个或多个词,符号“**”仅匹配一个词。因此“audit.#”能够匹配到“audit.irs.corporate”,但是“audit.”只会匹配到“audit.irs”。(这里与我们一般的正则表达式的“”和“#”刚好相反,这里我们需要注意一下。)
下面是一个解释通配符模式交换机工作的一个样例
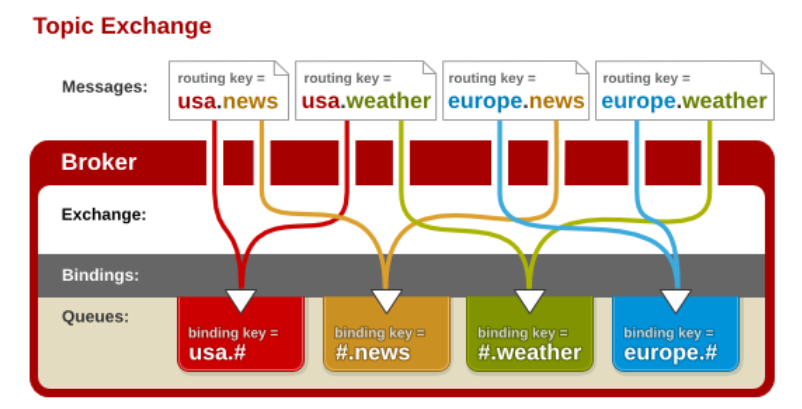
# 生产者
import pika
# 连接rabbitmq
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
# 声明创建一个交换机
channel.exchange_declare(exchange='logs3',
exchange_type='topic') #模糊匹配
message = "info: Hello World!"
channel.basic_publish(exchange='logs3',
routing_key='sdsd.sds.sdsd.news', # 信息绑定关键字
body="usa news... ... ...")
print(" [x] Sent %r" % message)
connection.close()
#消费者
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# 声明交换机
channel.exchange_declare(exchange='logs3',
exchange_type='topic') # topic:模糊匹配
# 创建队列,名为随机字符串
result = channel.queue_declare("",exclusive=True)
queue_name = result.method.queue
print(queue_name)
# 将队列绑定到某个交换机上
channel.queue_bind(exchange='logs3',
queue=queue_name,
routing_key="#.news"
)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(queue=queue_name,
auto_ack=True,
on_message_callback=callback)
channel.start_consuming()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号