Hadoop综合大作业
Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
由于我的爬虫大作业是中文的,所以我下载了一篇英文小说(哈利波特1-7章,共58000行数据)来进行词频统计分析。
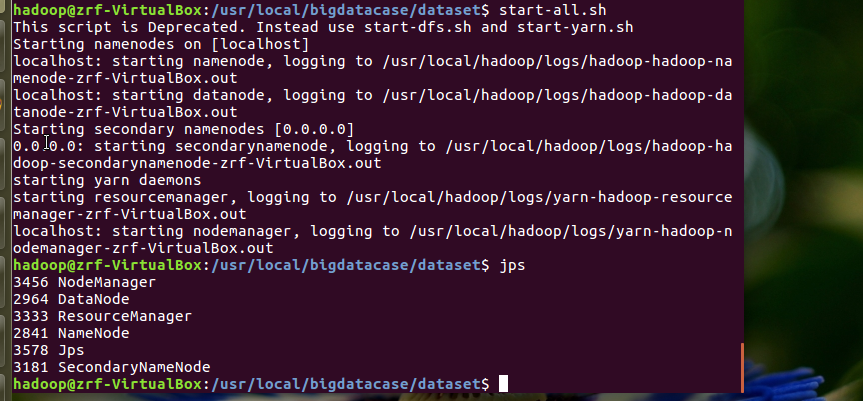
首先启动hadoop
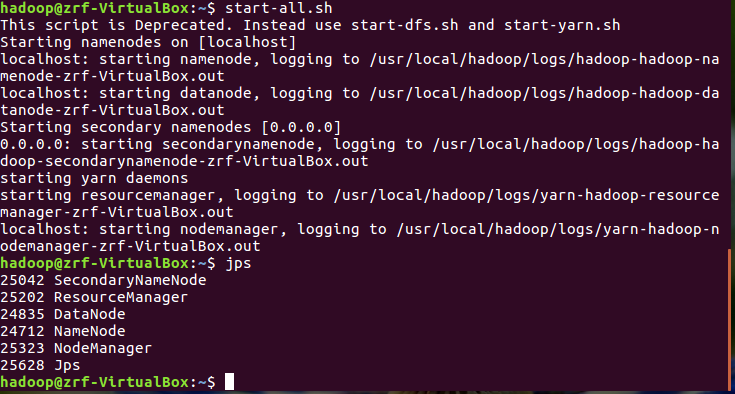
文件上传到hdfs

启动hive
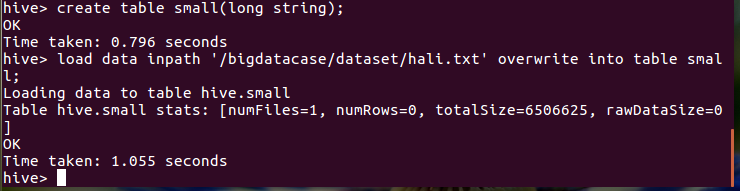
创建小说表,并导入数据
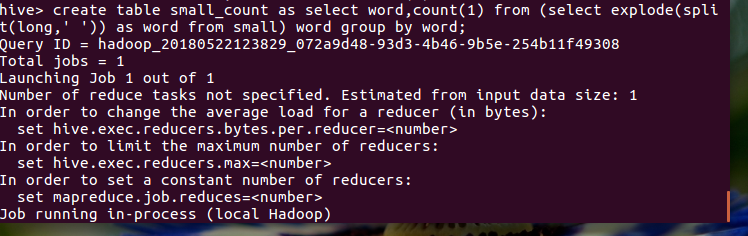
用HQL进行词频统计,结果放在表word_count里
查看统计结果
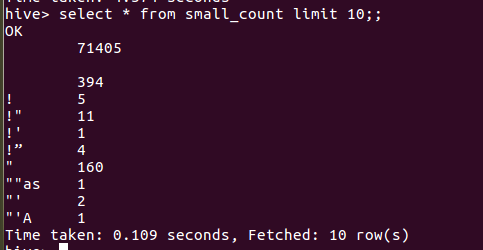
以下是我的爬虫大作业的数据提交到hive
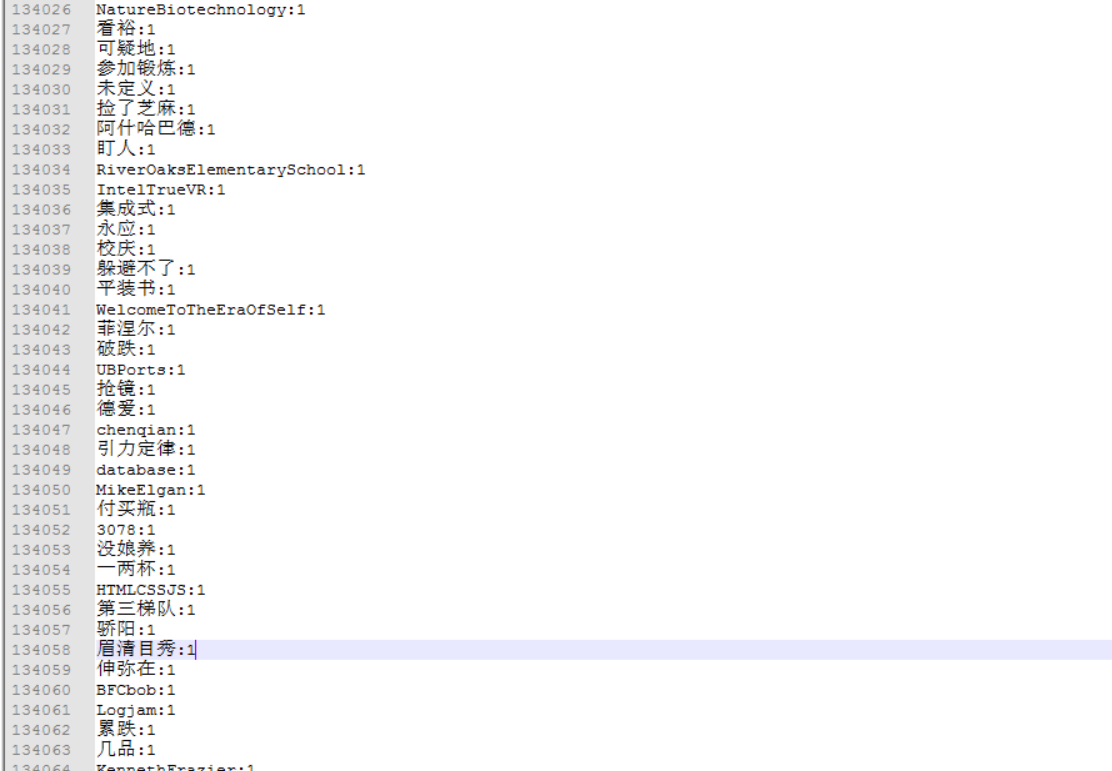
我统计的是博客园2018年到4月底的新闻词频统计,统计的结果大部分为中文,统计的最后几个单词如下图
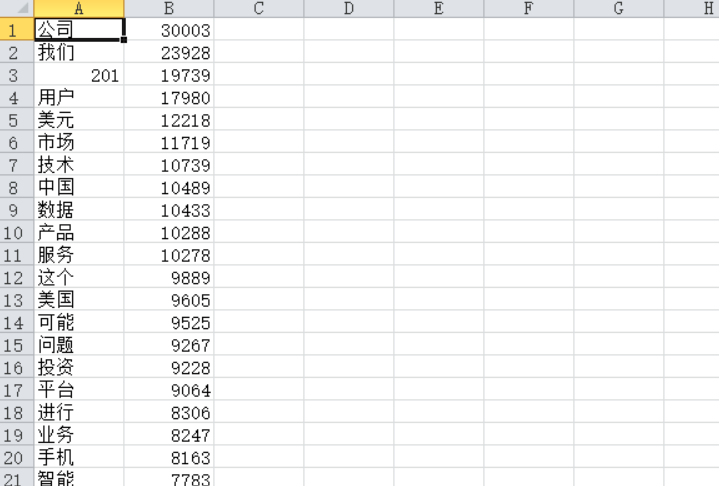
首先在本地把统计好的词频转化成csv格式和txt格式

通过软件WinSCP把文件上传到虚拟机

然后要启动hdfs
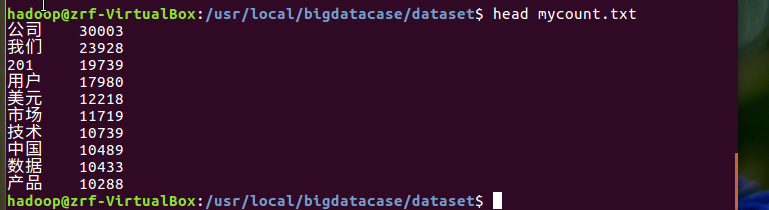
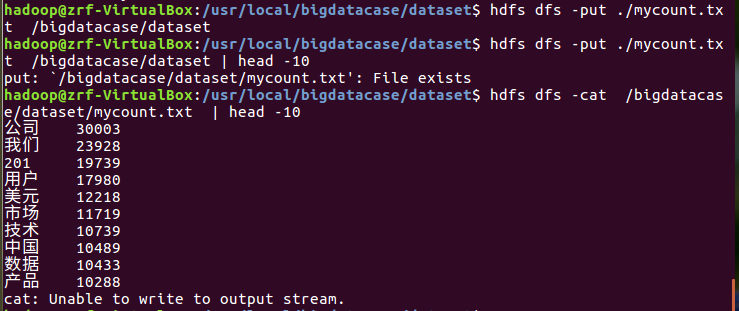
上传到hdfs并显示前10条
启动mysql

启动hive

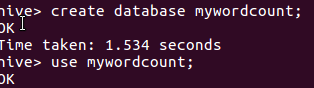
创建数据库
创建表

导入数据

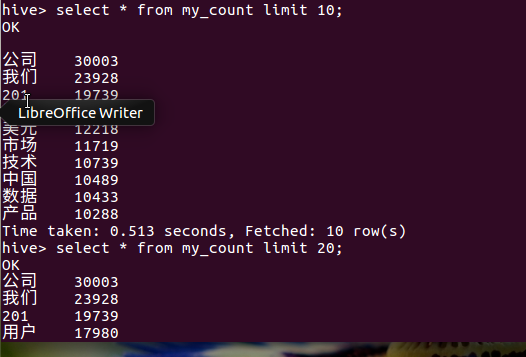
查看数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号