HashMap
JDK1.8 HashMap 源码
put操作
//put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K, V>[] tab;
Node<K, V> p;
int n, i;
//判断当前数组是否为空,空则初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//对应数组位置无元素则直接添加
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K, V> e;
K k;
//当前数组位置key相等则直接替换
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//当前key不是要put的元素的key,是红黑树结构
else if (p instanceof TreeNode)
e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);
else {
//链表结构遍历,插入到链表尾部,JDF1.7插入到链表头部
for (int binCount = 0; ; ++binCount) {
//next为空说明没有,直接插入
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//新插入后,链表长度大于阈值,链表变红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//key已存在,对应Node为 e
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//当前key已存在
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
// put(key,value) 返回值为 key对应的旧值,没有则返回null
return oldValue;
}
}
++modCount;
// 扩容, map.size()> 容量*负载因子
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
数组扩容
扩容, map.size()> 容量*负载因子;或者初始化
// 扩容兼初始化
final Node<K, V>[] resize() {
Node<K, V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;// 数组长度
int oldThr = threshold;// 临界值
int newCap, newThr = 0;
if (oldCap > 0) {
// 扩容
if (oldCap >= MAXIMUM_CAPACITY) {
// 原数组长度大于最大容量(1073741824) 则将threshold设为Integer.MAX_VALUE=2147483647
// 接近MAXIMUM_CAPACITY的两倍
threshold = Integer.MAX_VALUE;
return oldTab;
} else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) {
// 新数组长度 是原来的2倍,
// 临界值也扩大为原来2倍
newThr = oldThr << 1;
}
} else if (oldThr > 0) {
// 如果原来的thredshold大于0则将容量设为原来的thredshold
// 在第一次带参数初始化时候会有这种情况
newCap = oldThr;
} else {
// 在默认无参数初始化会有这种情况
newCap = DEFAULT_INITIAL_CAPACITY;// 16
newThr = (int) (DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);// 0.75*16=12
}
if (newThr == 0) {
// 如果新 的容量 ==0
float ft = (float) newCap * loadFactor;// loadFactor 哈希加载因子 默认0.75,可在初始化时传入,16*0.75=12 可以放12个键值对
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float) MAXIMUM_CAPACITY ? (int) ft : Integer.MAX_VALUE);
}
threshold = newThr;// 将临界值设置为新临界值
@SuppressWarnings({ "rawtypes", "unchecked" })
// 扩容
Node<K, V>[] newTab = (Node<K, V>[]) new Node[newCap];
table = newTab;
// 如果原来的table有数据,则将数据复制到新的table中
if (oldTab != null) {
// 根据容量进行循环整个数组,将非空元素进行复制
for (int j = 0; j < oldCap; ++j) {
Node<K, V> e;
// 获取数组的第j个元素
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 如果链表只有一个,则进行直接赋值
if (e.next == null)
// e.hash & (newCap - 1) 确定元素存放位置
newTab[e.hash & (newCap - 1)] = e;
// 此处省略红黑树
else {
// 进行链表复制
// 方法比较特殊: 它并没有重新计算元素在数组中的位置
// 而是采用了 原始位置加原数组长度的方法计算得到位置
Node<K, V> loHead = null, loTail = null;
Node<K, V> hiHead = null, hiTail = null;
Node<K, V> next;
do {
/*********************************************/
/**
* 注: e本身就是一个链表的节点,它有 自身的值和next(链表的值),但是因为next值对节点扩容没有帮助,
* 所有在下面讨论中,我近似认为 e是一个只有自身值,而没有next值的元素。
*/
/*********************************************/
next = e.next;
// 注意:不是(e.hash & (oldCap-1));而是(e.hash & oldCap)
// (e.hash & oldCap) 得到的是 元素的在数组中的位置是否需要移动,示例如下
// 示例1:
// e.hash=10 0000 1010
// oldCap=16 0001 0000
// & =0 0000 0000 比较高位的第一位 0
//结论:元素位置在扩容后数组中的位置没有发生改变
// 示例2:
// e.hash=17 0001 0001
// oldCap=16 0001 0000
// & =1 0001 0000 比较高位的第一位 1
//结论:元素位置在扩容后数组中的位置发生了改变,新的下标位置是原下标位置+原数组长度
// (e.hash & (oldCap-1)) 得到的是下标位置,示例如下
// e.hash=10 0000 1010
// oldCap-1=15 0000 1111
// & =10 0000 1010
// e.hash=17 0001 0001
// oldCap-1=15 0000 1111
// & =1 0000 0001
//新下标位置
// e.hash=17 0001 0001
// newCap-1=31 0001 1111 newCap=32
// & =17 0001 0001 1+oldCap = 1+16
//元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
//参考博文:[Java8的HashMap详解](https://blog.csdn.net/login_sonata/article/details/76598675)
// 0000 0001->0001 0001
if ((e.hash & oldCap) == 0) {
// 如果原元素位置没有发生变化
if (loTail == null)
loHead = e;// 确定首元素
// 第一次进入时 e -> aa ; loHead-> aa
else
loTail.next = e;
//第二次进入时 loTail-> aa ; e -> bb ; loTail.next -> bb;而loHead和loTail是指向同一块内存的,所以loHead.next 地址为 bb
//第三次进入时 loTail-> bb ; e -> cc ; loTail.next 地址为 cc;loHead.next.next = cc
loTail = e;
// 第一次进入时 e -> aa ; loTail-> aa loTail指向了和 loHead相同的内存空间
// 第二次进入时 e -> bb ; loTail-> bb loTail指向了和 loTail.next(loHead.next)相同的内存空间 loTail=loTail.next
// 第三次进入时 e -> cc ; loTail-> cc loTail指向了和 loTail.next(loHead.next.next)相同的内存
} else {
//与上面同理
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);//这一块就是 旧链表迁移新链表
//总结:1.8中 旧链表迁移新链表 链表元素相对位置没有变化; 实际是对对象的内存地址进行操作
//在1.7中 旧链表迁移新链表 如果在新表的数组索引位置相同,则链表元素会倒置
if (loTail != null) {
loTail.next = null;// 将链表的尾节点 的next 设置为空
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;// 将链表的尾节点 的next 设置为空
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
JDK1.7以前 多线程插入会有死循环问题:

单线程过程
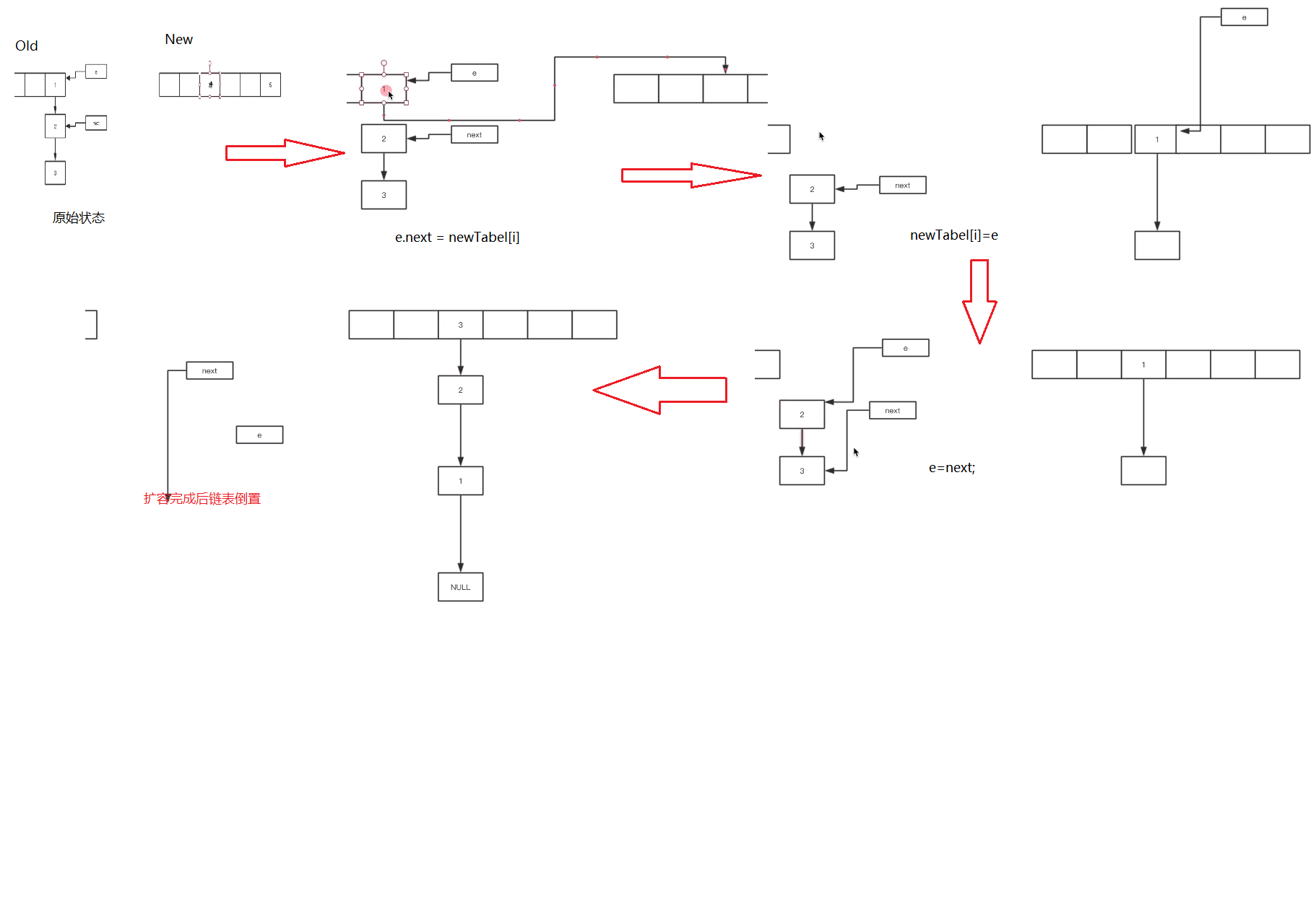
两个线程操作
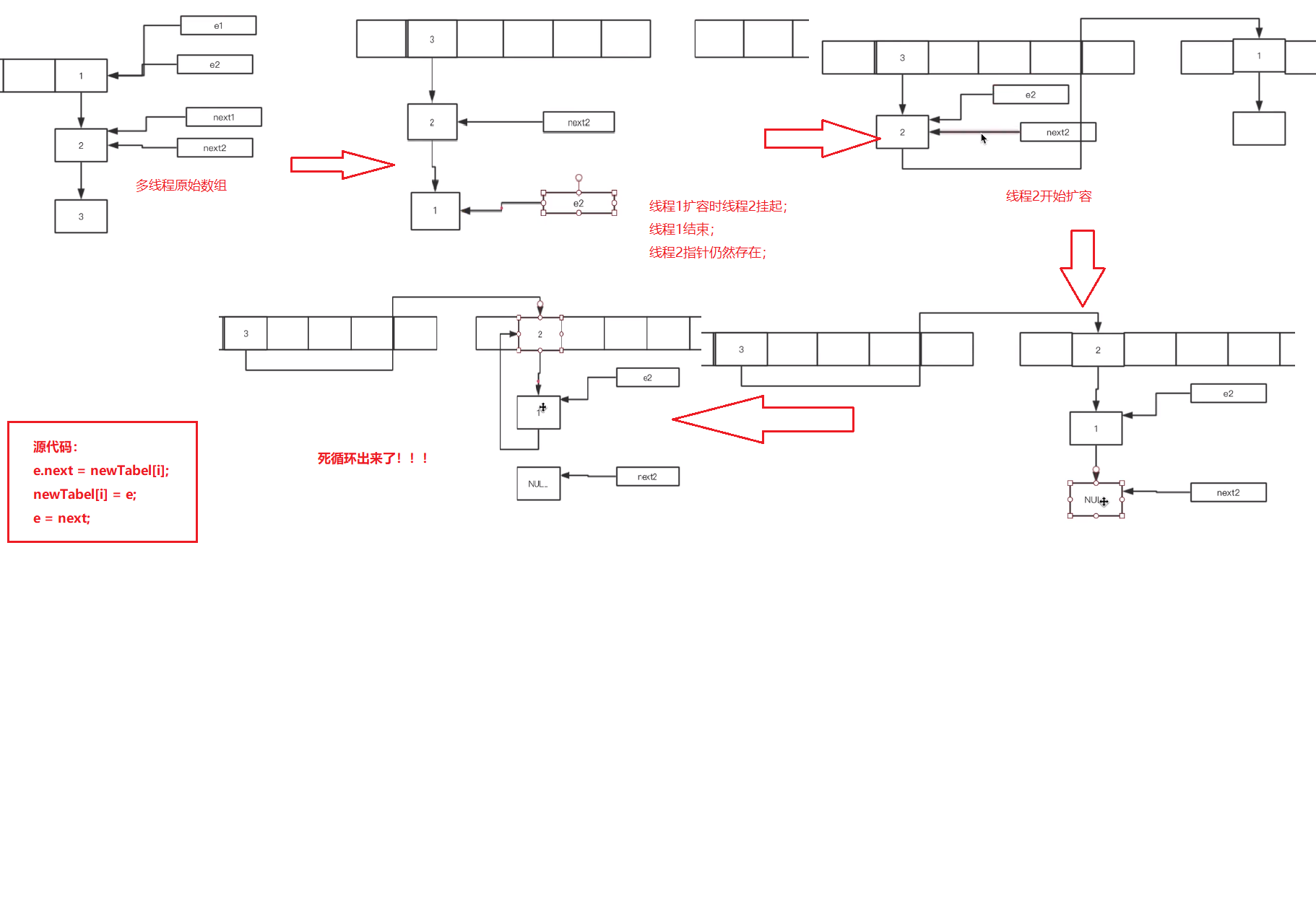
JDK1.8以后没有死循环问题,但是会有数据丢失:
比如有两个线程A和B,首先A希望插入一个key-value对到HashMap中,首先计算记录所要落到的 hash桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的 hash桶索引和线程B要插入的记录计算出来的 hash桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。
链表转红黑树
被树化的要求是 当数组的某一个索引位置上的元素以链表形式存在的数据个数 > 8 且当前数组的长度 > 64时
/**
* Replaces all linked nodes in bin at index for given hash unless
* table is too small, in which case resizes instead.
*/
final void treeifyBin(Node<K, V>[] tab, int hash) {
int n, index;
Node<K, V> e;
//MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量:64
//即被树化的要求是 当数组的某一个索引位置上的元素以链表形式存在的数据个数 > 8 且当前数组的长度 > 64时
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K, V> hd = null, tl = null;
do {
TreeNode<K, V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
参考:
https://www.cnblogs.com/yucfeng/p/9035308.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号