安装Spark与Python练习
一、安装Spark
1.检查基础环境hadoop,jdk
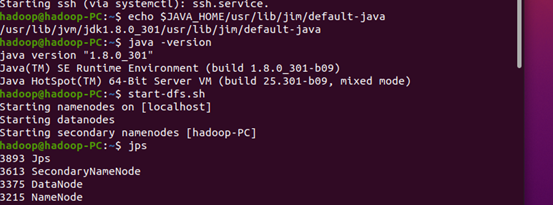
2.下载spark
由于上学期已经下载好了Spark,这里没有下载过程的截图
3.配置文件
4.配置环境变量
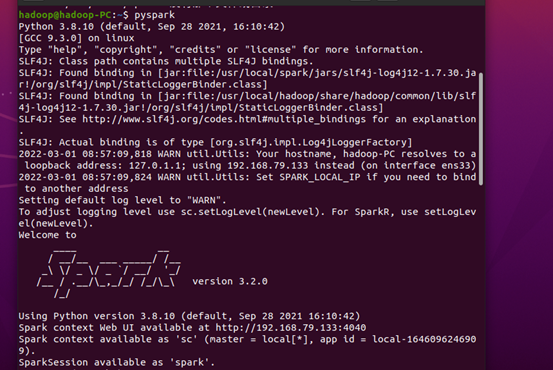
5.运行

二、Python编程练习:英文文本的词频统计
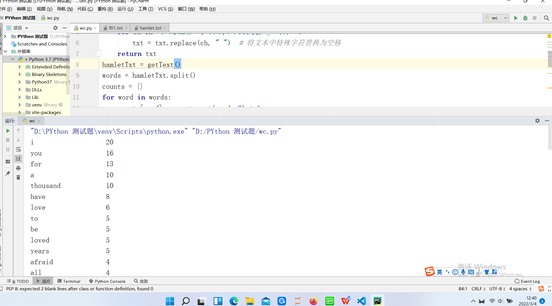
# CalHamletV1.py def getText(): txt = open("hamlet.TXT", "r", encoding='UTF-8').read() # 打开文件 txt = txt.lower() # 全部转成小写 for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~': txt = txt.replace(ch, " ") # 将文本中特殊字符替换为空格 return txt hamletTxt = getText() words = hamletTxt.split() counts = {} for word in words: counts[word] = counts.get(word, 0) + 1 items = list(counts.items()) items.sort(key=lambda x: x[1], reverse=True) # 排序 i=1 while i <= len(items): word, count = items[i - 1] print("{0:<20}{1}".format(word, count)) i = i + 1 txt = open("f01.txt", "w", encoding='UTF-8') txt.write(str(items)) print("文件写入成功")
运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号