python logging之初步学习(一)
描述
PEP 282 – A Logging System | peps.python.org
PEP 282 是一个关于 Python 日志系统的提案,它描述了一个提议加入 Python 标准库的日志记录包。
这个提案受到了 Java 的 java.util.logging 包、log4j、Protomatter 项目的 Syslog 包和 MAL 的 mx.Log 包等日志系统的启发。
PEP 282 最终被接受,并成为 Python 标准库的一部分,从 Python 2.3 版本开始提供 logging 模块。
使用教程 Logging HOWTO — Python 3.12.6 documentation
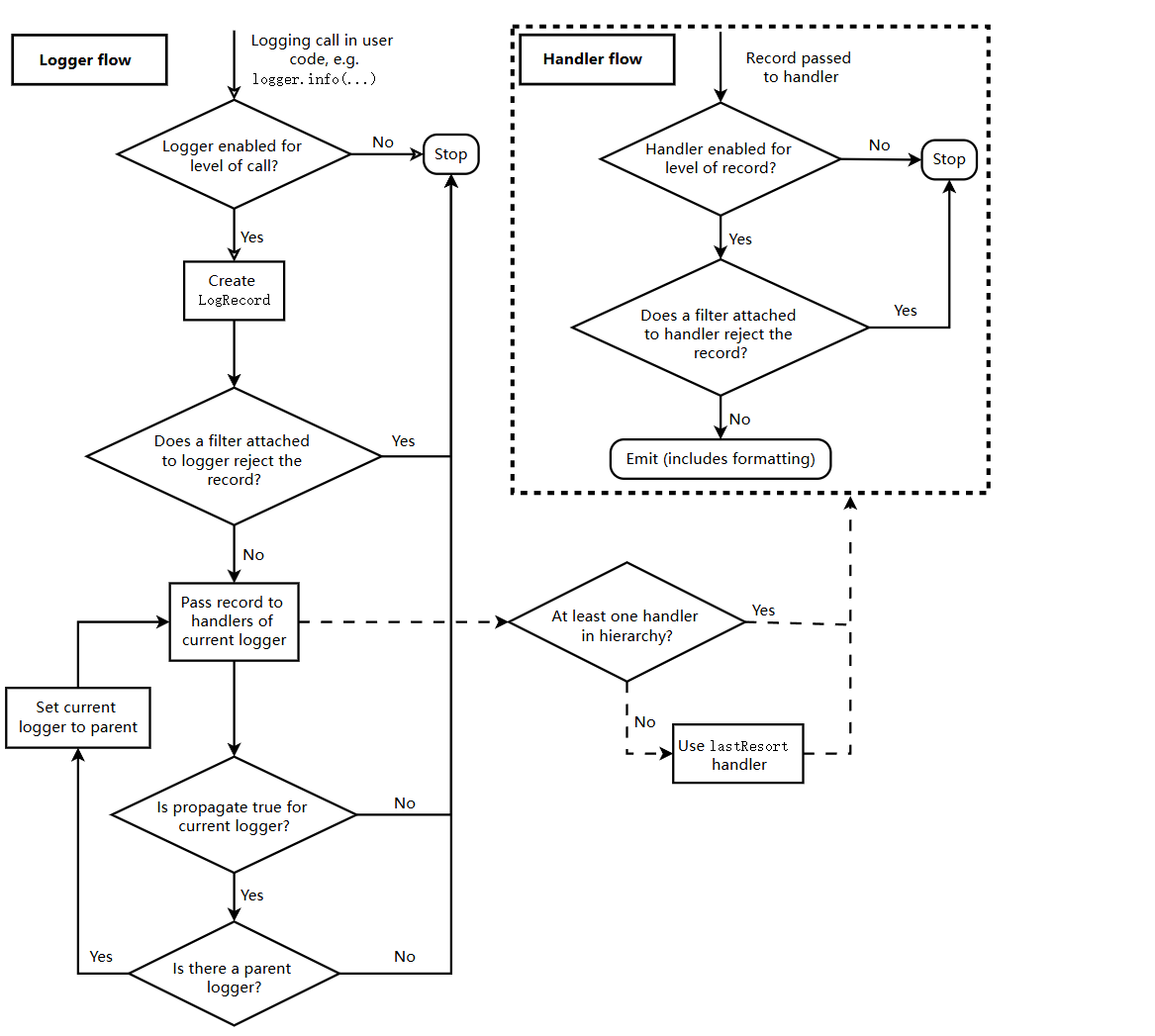
日志控制流
日志事件信息在记录器(loggers)和处理器(handlers)中的流动如下所示的图表所描绘。
日志记录器流程(Logger Flow):
1. 查看logger启用调用日志事件的级别。(不启用则结束)
2.创建logrecord对象,记录log信息。
3.如果有附加到 logger 的过滤器,检查过滤器是否拒绝该日志记录。(拒绝则退出)
4.传递日志记录传递给current logger 的处理器handler。
传递给handler的过程中:
1. 查看是否向上层logger 传递(不向上级传递-- 传递给handler,结束)
2. 记录器的 propagate 属性为 True,则日志事件会向上传递到父记录器。
3. 设置父记录器,为current logger ,
4. 重复上述循环,直到不存在父级logger。
日志处理器流程(Handler Flow):
- 检查处理器:确定在层级结构中是否存在至少一个 handler。(没有的话,使用lastResort handler)
- 检查 handler 是否启用:确定 handler 是否启用了日志记录的级别。(不启用,结束)
- 检查 handler 附带的过滤器:检查过滤器是否拒绝该日志记录。(拒绝则退出)
- 没有被过滤器拒绝,执行
Emit操作,这通常包括格式化日志消息。
用户代码中的日志调用,例如 logger.info(...),会触发图例流程。
应用程序使用 Logger 对象进行日志记录调用 logging。
Loggers 以层次化的命名空间组织,子 Logger 从其父 Logger 继承一些日志记录属性。
Logger 名称采用“点分名称”命名空间,点(句号)表示子命名空间。因此,Logger 对象的命名空间对应于一个树状数据结构。
"" 是命名空间的根
"Zope" 是根的子节点
"Zope.ZODB" 是 "Zope" 的子节点
这些 Logger 对象创建 LogRecord 对象, LogRecord 会传递给 Handler 对象以输出。
Logger 和 Handler 都可以使用 日志级别 和(可选的)过滤器 来决定是否对特定的 LogRecord 进行输出。
当需要将 LogRecord 输出到外部时,Handler 可以(可选地)使用 Formatter 来本地化和格式化消息,然后将其发送到 I/O 流。
每个 Logger 都跟踪一组输出 Handler。
默认情况下,所有 Logger 还会将其输出发送到其祖先 Logger 的所有 Handler。然而,Logger 也可以被配置为忽略更高层次的 Handler。
当日志记录被禁用时,对Logger API的调用可以是低成本的。如果给定的日志级别被禁用了日志记录,那么Logger可以进行一个简单的比较测试然后返回。
如果给定的日志级别启用了日志记录,Logger在将LogRecord传递给Handlers之前仍然会注意最小化成本。
特别是,本地化和格式化(相对来说较昂贵的操作)会被推迟,直到Handler请求它们。
整体的记录器(Logger)层级也可以有一个与之关联的级别,这个级别优先于个别记录器(Logger)的级别。
如果一个Logger的级别被设置为某个特定的级别(比如DEBUG),它理论上应该能够处理该级别及其以上所有级别的日志消息。
但是,如果这个Logger的父Logger(在这个层级链中一直向上追溯,直到Root Logger)有一个更高的日志级别设置(比如INFO),
那么即使子Logger被配置为接收低级别的日志(如DEBUG),来自这些子Logger的低级别日志消息也会被父Logger的级别设置所拦截,因为它们不会被传递到更高层级的Logger中进行处理。
日志级别
日志级别按重要性递增的顺序是:
DEBUG INFO WARN ERROR CRITICAL
在术语上选择使用 CRITICAL 而不是 log4j 中使用的 FATAL。这两个级别在概念上是相同的 - 都表示严重或非常严重的错误。然而,FATAL 暗示了“死亡”,
在 Python 中这意味着引发并捕获不到的异常、回溯和退出。由于日志模块不会从 FATAL 级别的日志条目强制执行这样的结果,因此优先使用 CRITICAL 而不是 FATAL 是有道理的。
尽管强烈推荐上述级别,但日志系统不应过于规定性。用户可以定义自己的级别,以及任何级别的文本表示。
然而,用户定义的级别必须遵守它们都是正整数,并且按严重性递增的顺序排列的约束。
logger对象
每个 Logger 对象跟踪一个感兴趣的日志级别(或阈值),并丢弃低于该级别的日志请求。
Manager 类实例维护一个命名的 Logger 对象的层次结构。层级由点分隔的名称表示:Logger “foo” 是 Logger “foo.bar” 和 “foo.baz” 的父级。
Manager 类实例是单例模式,不直接暴露给用户,用户通过各种模块级函数与其交互。
一般的日志记录方法如下:
class Logger:
def log(self, lvl, msg, *args, **kwargs):
"""在日志级别 'lvl' 上记录 'str(msg) % args'。"""
...
此外,还定义了每个日志级别的便捷函数。
class Logger:
def debug(self, msg, *args, **kwargs): ...
def info(self, msg, *args, **kwargs): ...
def warn(self, msg, *args, **kwargs): ...
def error(self, msg, *args, **kwargs): ...
def critical(self, msg, *args, **kwargs): ...
“msg” 参数通常是一个格式化字符串;但它可以是任何对象 x,只要 str(x) 返回格式化字符串。
当创建新的日志记录器时,它们会初始化为一个表示“无级别”的级别。可以通过 setLevel() 方法显式设置级别:
class Logger:
def setLevel(self, lvl): ...
如果日志记录器的级别没有设置,系统会咨询它所有的祖先,沿层次结构向上查找直到找到一个显式设置的级别。
这个级别被视为日志记录器的“有效级别”,可以通过 getEffectiveLevel() 方法查询。
最高级的logger对象为 RootLogger 在所有目录层级之上 , 使用logging.getLogger()来获取此对象。
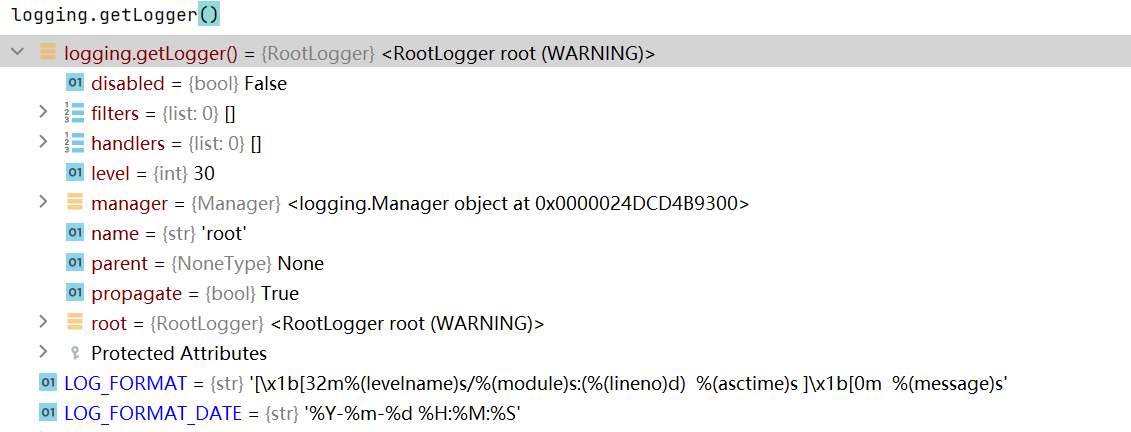
设置此对象的属性可以用如下函数,
logging.basicConfig(level=level,
format=LOG_FORMAT,
datefmt=LOG_FORMAT_DATE,
handlers=handlers)
Handlers
处理器(Handlers)负责对给定的日志记录(LogRecord)进行有用的处理。以下是将实现的核心处理器:
- StreamHandler:用于写入文件类对象的处理器。
- FileHandler:用于写入单个文件或一组轮转文件的处理器。
- SocketHandler:用于写入远程TCP端口的处理器。
- DatagramHandler:用于写入UDP套接字的处理器,用于低成本日志记录。Jeff Bauer已经有这样的系统[5]。
- MemoryHandler:一个在内存中缓冲日志记录的处理器,直到缓冲区满或发生特定条件[1]。
- SMTPHandler:通过SMTP发送到电子邮件地址的处理器。
- SysLogHandler:通过UDP写入Unix syslog的处理器。
- NTEventLogHandler:用于在Windows NT、2000和XP上写入事件日志的处理器。
- HTTPHandler:用于使用GET或POST语义写入Web服务器的处理器。
处理器也可以使用setLevel()方法为它们设置级别:
def setLevel(self, lvl):
# ...FileHandler可以设置为创建一组轮转日志文件。在这种情况下,传递给构造函数的文件名被视为“基础”文件名。轮转的额外文件名通过在基础文件名后追加.1、.2等来创建,轮转的最大数量在请求rollover时指定。
setRollover方法用于指定日志文件的最大大小和轮转中的备份文件的最大数量。
def setRollover(maxBytes, backupCount):
# ...如果将maxBytes指定为零,则永远不会发生轮转,日志文件会无限增长。如果指定了非零大小,则当即将超出该大小时,会发生轮转。
rollover方法确保基础文件名始终是最新的,.1是次新的,.2是次次新的,以此类推。
Formatters
格式化器(Formatter)负责将日志记录(LogRecord)转换为字符串表示。处理器(Handler)在写入记录之前可能会调用其格式化器。以下是将实现的核心格式化器:
Formatter:提供类似 printf 的格式化,使用 % 操作符。 BufferingFormatter:提供对多条消息的格式化,支持标题和尾随格式化。 可以通过在处理器上调用 setFormatter() 来将格式化器与处理器关联:
def setFormatter(self, form):
# ...格式化器使用 % 操作符来格式化日志消息。格式字符串应包含 %(name)x,使用 LogRecord 的属性字典来获取特定于消息的数据。提供以下属性:
%(name)s - 日志记录器(日志通道)的名称
%(levelno)s - 消息的数字日志级别(DEBUG, INFO, WARN, ERROR, CRITICAL)
%(levelname)s - 消息的文本日志级别(“DEBUG”,“INFO”,“WARN”,“ERROR”,“CRITICAL”)
%(pathname)s - 发出日志调用的源文件的完整路径名(如果可用)
%(filename)s - 路径名的文件名部分
%(module)s - 发出日志调用的模块
%(lineno)d - 发出日志调用的源代码行号(如果可用)
%(created)f - 创建 LogRecord 时的时间(time.time() 返回值)
%(asctime)s - 创建 LogRecord 时的文本时间
%(msecs)d - 创建时间的毫秒部分
%(relativeCreated)d - 创建 LogRecord 时的时间,相对于日志模块加载的时间(通常在应用程序启动时)
%(thread)d - 线程 ID(如果可用)
%(message)s - record.getMessage() 的结果,恰好在记录发出时计算
如果格式化器发现格式字符串包含 “(asctime)s”,则创建时间被格式化为 LogRecord 的 asctime 属性。
为了在格式化日期时提供灵活性,格式化器使用整体消息的格式字符串进行初始化,并且使用单独的日期/时间格式字符串。
日期/时间格式字符串应该是 time.strftime 格式。消息格式的默认值是 “%(message)s”。默认的日期/时间格式是 ISO8601。
格式化器使用类属性 “converter” 来指示如何将时间从秒转换为元组。
默认情况下,“converter” 的值是 “time.localtime”。如果需要,可以在单个格式化器实例上设置不同的转换器(例如 “time.gmtime”),或者更改类属性以影响所有格式化器实例。
filter
当基于级别的过滤不够时,可以通过 Filter 类来决定是否输出 LogRecord。Logger 或 Handler 可以调用 Filter 来进行判断
日志记录器和处理器可以安装多个过滤器,任何一个过滤器都可以否决输出日志记录。
class Filter:
def filter(self, record):
"""
返回一个值,如果该值为真,则处理记录。
如果过滤器认为适当,可能会修改记录。
"""默认行为允许使用日志记录器名称初始化过滤器。这只允许通过使用指定名称的日志记录器或其任何子记录器生成的事件。
例如,使用 “A.B” 初始化的过滤器将允许 “A.B”,“A.B.C”,“A.B.C.D”,“A.B.D” 等日志记录器记录的事件通过,但不会允许 “A.BB”,“B.A.B” 等通过。
如果用空字符串初始化,则过滤器会通过所有事件。
当需要集中关注应用程序的某个特定区域时,这种过滤器行为很有用;
只需更改根日志记录器上附加的过滤器即可改变关注焦点。
配置
使用这样的日志系统的主要好处是,可以在不改变应用程序源代码的情况下控制从应用程序获得多少和什么类型的日志输出。
因此,虽然可以通过日志 API 进行配置,但也必须能够在不改变应用程序的情况下更改日志配置。对于像 Zope 这样的长期运行的程序,应该能够在程序运行时更改日志配置。
配置包括以下内容:
- 日志记录器或处理器应关注的日志级别。
- 应将哪些处理器附加到哪些日志记录器。
- 应将哪些过滤器附加到哪些处理器和日志记录器。
- 指定特定处理器和过滤器的特定属性。
通常,每个应用程序都有自己配置日志输出的要求。然而,每个应用程序将通过标准机制向日志系统指定所需的配置。
最简单的配置是将一个写入 stderr 的单个处理器附加到根日志记录器。这个配置通过在导入日志模块后调用 basicConfig() 函数来设置。
def basicConfig(): ...
一个简单示例
示例显示了默认输出格式。输出格式的各个方面应该是可配置的。

使用案例2
想将日志同时输出到控制台和文件,你可以添加一个StreamHandler。下面是一个示例代码:
import logging
# 配置日志的基本设置
logging.basicConfig(filename='app.log', level=logging.DEBUG)
# 创建一个logger
logger = logging.getLogger(__name__)
# 创建一个handler,用于将日志输出到控制台
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.DEBUG)
# 定义handler的输出格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
console_handler.setFormatter(formatter)
# 给logger添加handler
logger.addHandler(console_handler)
# 记录一条信息
logger.info('This message will go to both the log file and the console')
 浙公网安备 33010602011771号
浙公网安备 33010602011771号