


Hive
一、hive概述
1、hive前提:hdsf、MapReduce
hive简介:hive是一个构建在hadoop上的数据仓库平台,其设计目的是使hadoop上的数据操作与传统sql结合(HQL),让熟悉sql编程的开发人员能够轻松向hadoop平台转移
http://hive.apache.org
2、数据仓库
数据仓库是一个面向主题的、集成的、不可更新的、随时间不变化的数据集合,它用户支持企业或组织的决策分析处理
数据仓库的结构和建立:
数据源:来源数据库,文档或者其他数据信息
数据存储及管理(ETL过程):按一定的方式抽取、转换、装载
数据仓库引擎:数据服务器
前端展示:查询、报表、分析及应用
3、什么是hive
hive允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作
hive是sql解析引擎,他将sql语句转移成MapReduce job然后在hadoop执行
hive的表其实就是hdfs的目录/文件
二、hive的体系结构
1、hive的元数据
hive将元数据存储在数据库中(metastore),支持mysql、derby等
hive中的元数据包括标的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
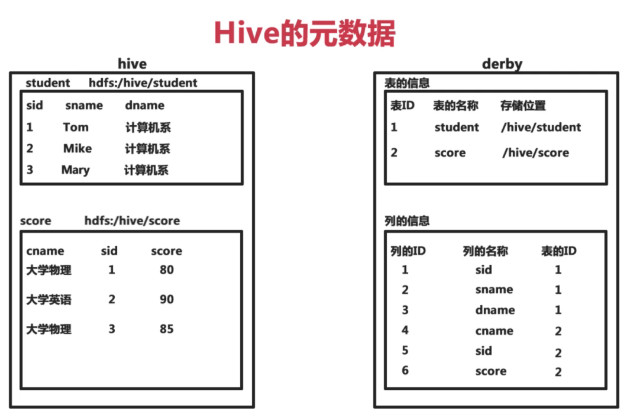
左边为存储在hive中的表,右上即把表的元信息存储在默认的derby中,右下为列的元信息
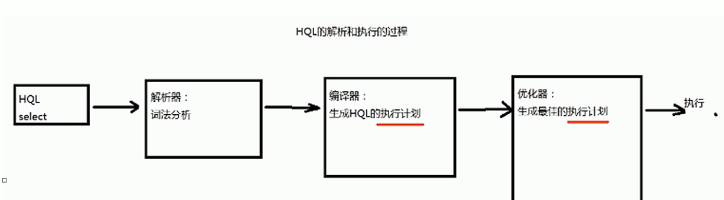
2、HQL的执行过程
解释器、编译器、优化器完成hql查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在hdfs中,并在随后有MapReduce调用执行(类似于oracle的执行计划)
3、hive的体系结构
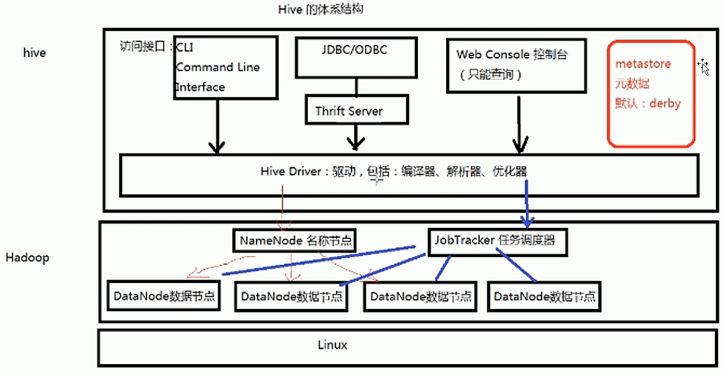
最底层linux操作系统。hadoop集群架构于Linux上,hive的数据就存储于hadoop的datanode中,hive执行一条语句,实际就是分成若干mapreduce作业,由jobtracker调度。hive的底层由hive驱动来执行查询,有了hive驱动就可以提供各种不同的访问接口来执行hive语句。hive中的元数据用来保存元信息
三、hive的安装
hive基于hadoop,因此需要先安装hadoop
。。。。
四、hive的管理
1、CLI方式
直接输入#HIVE_HOME/bin/hive或者输入#hive --service cli
常用命令
desc <table>
dfs -ls 目录
!命令 --执行linux命令
select xxx from xxx
hive -S --静默模式
2、web界面方式
默认端口:9999
启动:#hive --service hwi(需要war包)
访问:http://<IP>:9999/hwi/
3、hive的远程服务
端口:10000
启动:#hive --service hiveserver
若需要JDBK等远程连接必须开启
五、hive的数据类型
1、基本数据类型
整数类型:tinyint/smallint/int/bigint
浮点数类型:float/double
布尔类型:boolean
字符串类型:string
2、复杂数据类型
array:数组,由一系列相同数据类型的元素组成
map:集合,键值对,可通过key访问元素
struct:结构类型,可以包含不同数据类型的元素
3、时间类型
data:yyyyMMdd
timestamp:时间戳
六、hive的数据模型
1、hive的数据存储
基于hdfs
没有专门的数据存储格式
存储结构主要包括:数据库、文件、表、视图
可以直接加载文本文件(.txt文件等)
2、内部表与外部表
内部表直接hive创建,删除时数据与元数据一同删除
create table t1
(id int,name string)
row format delimted fields terminated by ','
location '/xxx';
外部表先HDFS存在文件,创建表时指定路径,删除时只删除链接,数据任然存储于hdfs上。若hdfs多个文件删除一个或多个,存在于该文件的数据也会删除。
create external table t2
(id int,name string)
row format delimted fields terminated by ','
location '/xxx';
3、桶表
类似于hash表,根据字段相同的哈希值放入到一起
create table t3
(id int,name string)
clustered by(name) into 5 buckets;
一、hive数据的导入
1、load语句导入
(1)导入的文件在操作系统上
load data local inpath '路径/文件' into table t1;
t1表创建的时候需要指定列分割符,并且与文件分隔符一致
load data local inpath '路径' overwrite into table t2;
将路径下所有文件导入到t2,并覆盖
load data local inpath '路径/文件' into table t3 partition(xxx='x');
导入到分区表
(2)导入的文件在hdfs中
load data inpath '路径/文件' overwrite into table t4;
2、sqoop数据导入
(1)sqoop安装
下载解压sqoop安装包
设置HADOOP_COMMON_HOME、HADOOP_MAPRED_HOME(hadoop安装目录)
(2)sqoop使用
oracle的驱动jar需要保存到sqoop的lib目录下
使用Sqoop导入Oracle到HDFS
./sqoop import --connect jdbc:oracle:thin:@ip:端口:SID --username xxx --password xxx --table xxx --columns 'xx1,xx2,xx3,xx4' --m 1 --target-dir '/路径'
使用Sqoop导入Oracle到hive
./sqoop import --hive-import --connect jdbc:oracle:thin:@ip:端口:SID --username xxx --password xxx --table xxx --columns 'xx1,xx2,xx3,xx4' --m 1
使用Sqoop导入Oracle到hive,并指定表名
./sqoop import --hive-import --connect jdbc:oracle:thin:@ip:端口:SID --username xxx --password xxx --table xxx --columns 'xx1,xx2,xx3,xx4' --m 1 --hive-table t1
使用Sqoop导入Oracle到hive,并指定表名和条件
./sqoop import --hive-import --connect jdbc:oracle:thin:@ip:端口:SID --username xxx --password xxx --table xxx --columns 'xx1,xx2,xx3,xx4' --m 1 --hive-table t2 --where 'id=1'
使用Sqoop导入Oracle到hive,并使用查询语句
./sqoop import --hive-import --connect jdbc:oracle:thin:@ip:端口:SID --username xxx --password xxx --table xxx --m 1 --query 'select * from table where id<10 and $CONDITIONS' --target-dit '/hdfs路径' --hive-table t3
使用Sqoop将hive数据导出到oracle
./sqoop export --connect jdbc:oracle:thin:@ip:端口:SID --username xxx --password xxx -m 1 --table test1 --export-dir 'hdfs文件路径'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号