Python网络爬虫—对地铁人流量数据分析
(一)、选题的背景
为什么要选择此选题?要达到的数据分析目标是什么?从社会、经济、技术、数据来源等方面进行描述(200 字以内)(10 分)
地铁行业蓬勃发展的世纪,它不占用城市宝贵土地和空间,既不对地面构成任何环境污染,又可以为乘客躲避城市嘈杂烦躁的空间提供良好环境。乘坐过地铁的人,普遍都有这样的感觉,快捷、准时、方便、舒适。地铁要客流统计实时监控人数的变化,一旦发生大客流,就可以实行客流量限制措施。在针对客流量统计数据,科学的有效增添工作人员的调配,对乘客存在的安全隐患做安全防护措施,同时在客流多时采取限流的方式方便乘客出行。所以,对地铁客流量统计,给地铁的统预测工作提供借鉴,为日常的地铁运行和调度工作以参考。同时对地铁大客流的现状进行分析和研究,提高地铁的运营水平,管理和组织策略。而且良好的客流组织工作能够提升市民出行的舒适度和满意度。
(二)、大数据分析设计方案(10 分)
1.本数据集的数据内容与数据特征分析
2.数据分析的课程设计方案概述(包括实现思路与技术难点)
以“地铁乘客流量预测”为题,可通过分析地铁站的历史刷卡数据,预测站点未来的客流量变化,帮助实现更合理的出行路线选择,规避交通堵塞,提前部署站点安保措施等,最终实现用大数据和人工智能等技术助力未来城市安全出行。地铁车站的客流量主要取决周边人口的密集程度以及客流的流动速度,同时又受到其他公共交通的制约和影响。另外,地铁车站的接驳换乘布置,车站的集散通过能力也是影响客流量的重要因素。周边经济水平。周边土地利用性质是影响车站客流量和全天客流分布特征的关键因素,通常情况下,周边经济越繁华,越能产生客流,因此客流量越大,通常为商业区、旅游去、休闲娱乐场所,火车站点,
一定时间内的乘客人数。大客流主要影响因素是客流的多少,在一段时间内进入地铁乘客越多,大客流的现象越发严重。站台乘客多,将导致乘客误入或者被挤下轨行区概率也高。周边接驳换乘设施。为了避免市区内的交通拥堵,很多地铁线路的站点都设置了与小汽车、自行车接驳换乘设施以吸引远郊区的客流。站内设备设施。面对巨大的客流,售票工作仅靠自动售票机是不能满足大客流售票要求的,车站自动售票机效率、数量也有限。因此在大客流之前应该提前制作好满足客流要求的预制单程票,当然这个是在有预见性的大客流时提前采取的准备工作。
以某一地铁站的客流量对该地铁站进行数据分析,多方面展开了解,从数据清洗,到pandas数据分析、pandas绘图、matplotlib、seaborn等多种方法进行数据处理,找到对应数据集并编写源代码,各方位对地铁客流量进行分析,让大家显明易懂该文章所表述内容
(三)、数据分析步骤(70 分)
1.数据源
请说明数据源采用的哪一个开放的数据集?如果是采集的,请说明采集来源与方式。
数据集来源:https://tianchi.aliyun.com/dataset?spm=5176.14154004.J_3941670930.15.31fe5699RLkDXV
https://tianchi.aliyun.com/dataset/dataDetail?dataId=21904
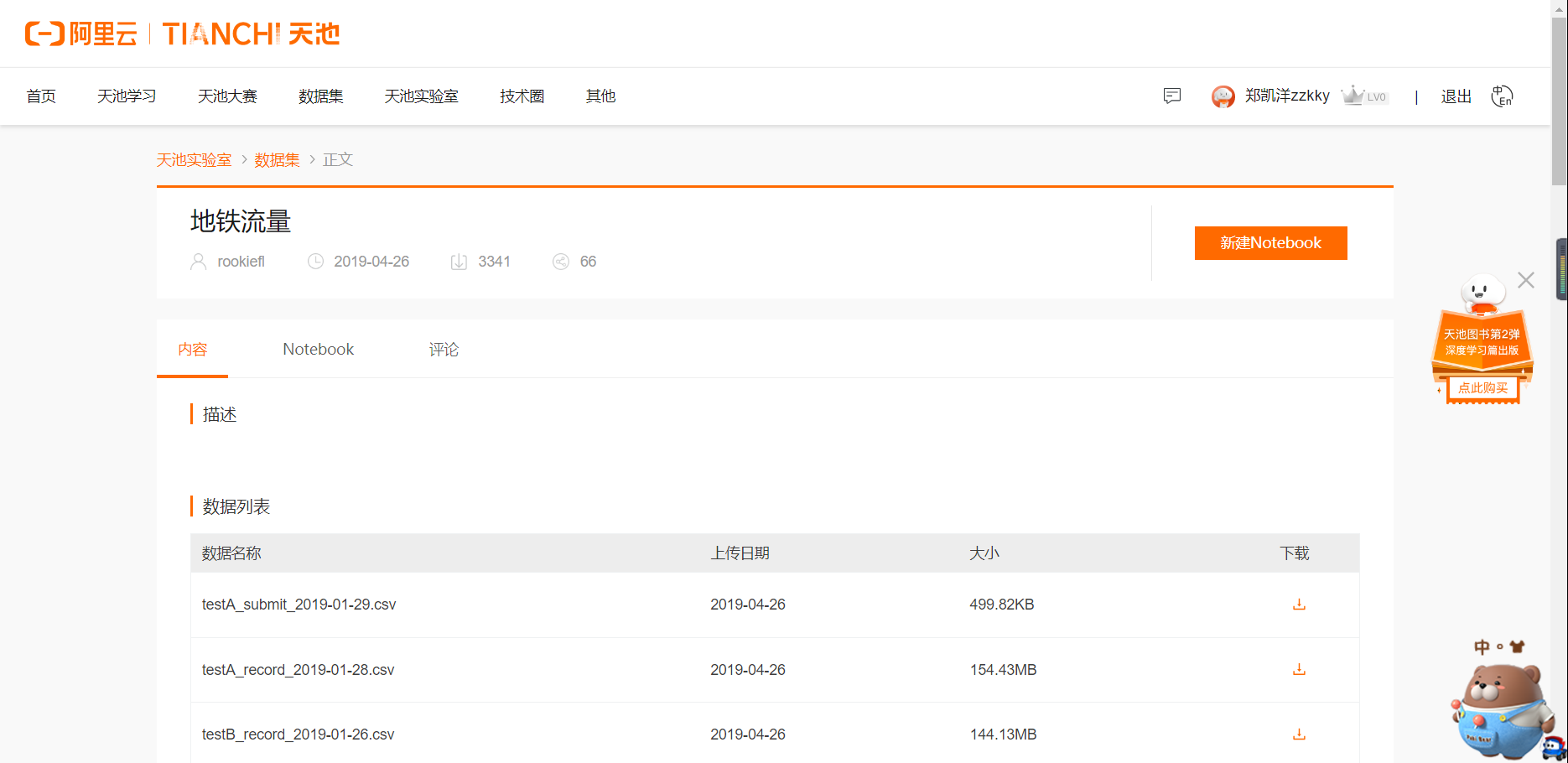
2.数据清洗
列出数据清洗的主要步骤
1 import pandas as pd
2 import numpy as up
3 file_path = open('D:\地铁1.csv')
4 file_path = open('D:\地铁2.csv')
5 file_path = open('D:\地铁3.csv')
6 file_path = open('D:\地铁4.csv')
7 file_path = open('D:\地铁5.csv')
8 file_path = open('D:\地铁6.csv')
9 file_path = open('D:\地铁7.csv')
10 file_path = open('D:\地铁8.csv')
11 file_path = open('D:\地铁9.csv')
12 file_path = open('D:\地铁10.csv')
13 file_data = pd.read_csv(file_path)
14 #查看空值,缺失值
15 file_data.isnull()
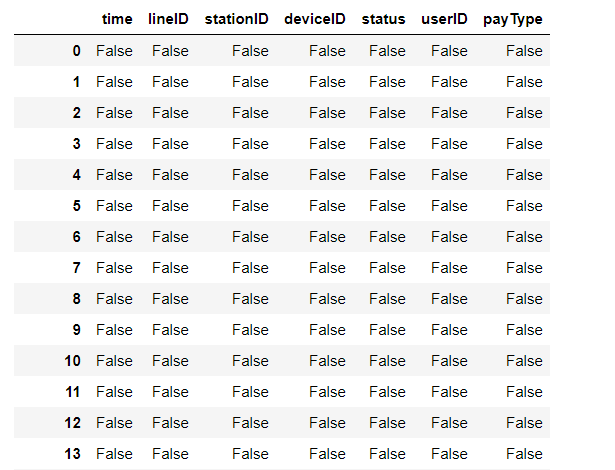
1 import pandas as pd
2 import numpy as up
3 file_path = open('D:\地铁1.csv')
4 file_path = open('D:\地铁2.csv')
5 file_path = open('D:\地铁3.csv')
6 file_path = open('D:\地铁4.csv')
7 file_path = open('D:\地铁5.csv')
8 file_path = open('D:\地铁6.csv')
9 file_path = open('D:\地铁7.csv')
10 file_path = open('D:\地铁8.csv')
11 file_path = open('D:\地铁9.csv')
12 file_path = open('D:\地铁10.csv')
13 file_data = pd.read_csv(file_path)
14 #查看缺失值,缺失值
15 file_data.notnull()
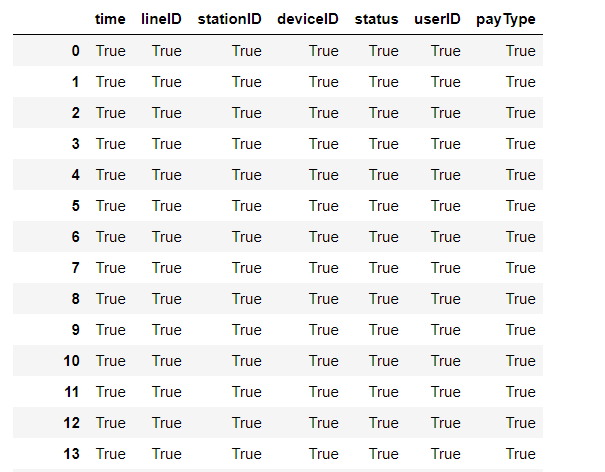
1 import pandas as np
2 import numpy as np
3 file_path = open('D:\地铁1.csv')
4 file_path = open('D:\地铁2.csv')
5 file_path = open('D:\地铁3.csv')
6 file_path = open('D:\地铁4.csv')
7 file_path = open('D:\地铁5.csv')
8 file_path = open('D:\地铁6.csv')
9 file_path = open('D:\地铁7.csv')
10 file_path = open('D:\地铁8.csv')
11 file_path = open('D:\地铁9.csv')
12 file_path = open('D:\地铁10.csv')
13 file_data = pd.read_csv(file_path)
14 #标记重复值
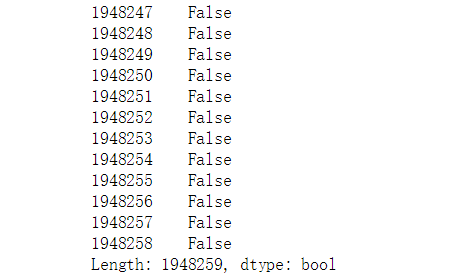
15 file_data.duplicated()

全为false,说明没有一个空值或缺失值,全为true,说明没有一个空值或缺失值,说明天池挑战赛提供的数据很干净如果出现缺失值的话,可以使用dropna()和fillna()方法对缺失值进行填充;
所有的标记都显示为false。说明没有重复值,不需要再处理,提供的数据没有问题,记录系统没有出错.
3.大数据分析过程及采用的算法
利用统计分析、数据挖掘和机器学习方法,对数据进行分析处理,获得分析结果,是数据分析处理流程的重要步骤。
1 import pandas as pd
2 import numpy as np
3 #读取表数据
4 file_path = ('D:\地铁5.csv')
5 file_data1 = pd.read_csv(file_path)
6 file_path = ('D:\地铁6.csv')
7 file_data2 = pd.read_csv(file_path)
8 file_path = ('D:\地铁7.csv')
9 file_data3 = pd.read_csv(file_path)
10 file_path = ('D:\地铁8.csv')
11 file_data4 = pd.read_csv(file_path)
12 file_path = ('D:\地铁9.csv')
13 file_data5 = pd.read_csv(file_path)
14 file_path = ('D:\地铁10.csv')
15 file_data6 = pd.read_csv(file_path)
16 frame=[file_datal,file_data2,file_data3,file_data4,file_data5,file_data6]
17 #相同字段的表首位相接,合并表
18 result=pd.concat(frame)
19 result

开始读取地铁站三条线路所有站点的刷卡数据记录
1 import pandas as pd
2 import numpy as np
3 #读取地铁站三条线路所有站点的刷卡数据记录
4 #读取地铁站三条线路所有站点的刷卡数据记录
5 file_path = open('D:\地铁5.csv')
6 file_path = open('D:\地铁6.csv')
7 file_path = open('D:\地铁7.csv')
8 file_path = open('D:\地铁8.csv')
9 file_path = open('D:\地铁9.csv')
10 file_path = open('D:\地铁10.csv')
11 file_data = pd.read_csv(file_path)
12 file_data
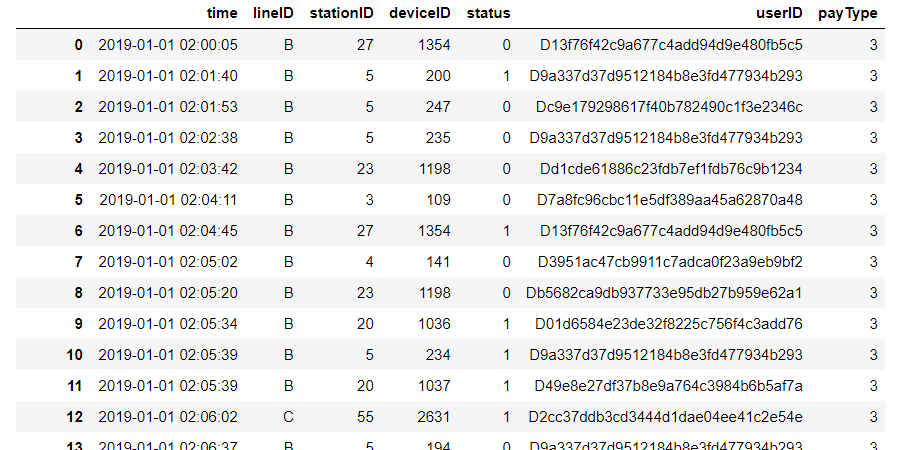
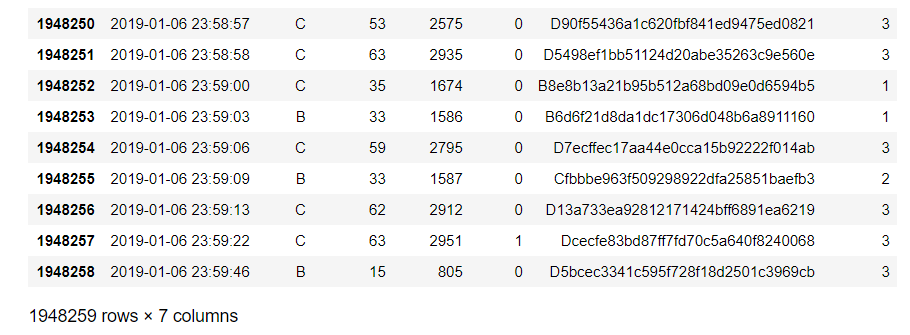
从读取到的数据可以看出,刷卡数据记录包括刷卡时间,乘客所在线路,搭车站点,刷卡设备号,刷卡状态:有或没有刷卡,客户ID:一列字符串,支付类型有三种.
1 #所有站点的刷卡数据记录
2 import pandas as pd
3 import numpy as np
4
5 #读取所有站点的刷卡数据记录
6 file_path = open('D:\地铁5.csv')
7 file_path = open('D:\地铁6.csv')
8 file_path = open('D:\地铁7.csv')
9 file_path = open('D:\地铁8.csv')
10 file_path = open('D:\地铁9.csv')
11 file_path = open('D:\地铁10.csv')
12 file_data = pd.read_csv(file_path)
13 file_data
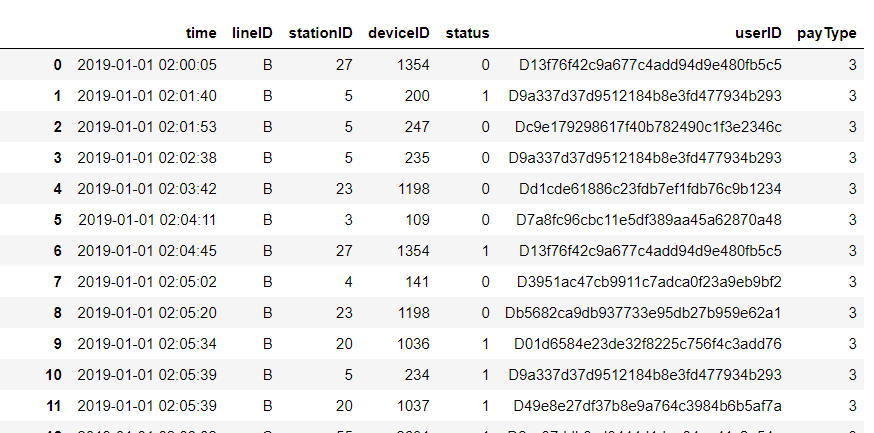
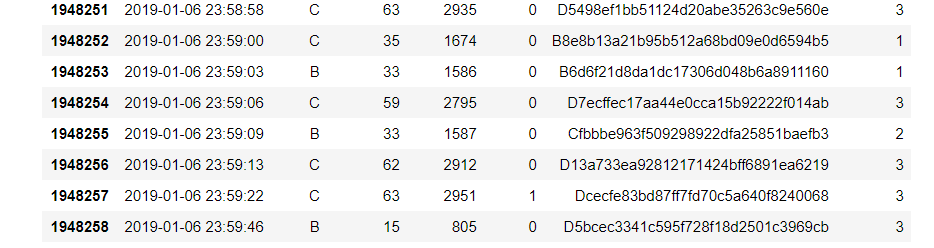
接下来用“地铁5”文档为例进行客流量分析
1 import pandas as pd
2 import numpy as np
3 file_path = open('D:\地铁5.csv')
4 file_data = pd.read_csv(file_path)
5 #创建一个DataFrame对象,该对象只有一列列数据:lineID[线路ID]
6 new_df = pd.DataFrame({'lineID':file_data['lineID'].unique()})
7 new_df

读取lineID一列的唯一值可以看出有三条地铁线路读取的时候和数据库读表有些类似,也可以根据要求读表,也可以将记录分组,排序等等
按lineID这一列将数据进行分组,并统计每个分组的数量
1 import math
2 import pandas as pd
3 import numpy as np
4 file_path = open('D:\地铁5.csv')
5 file_data = pd.read_csv(file_path)
6 #按“lineID”列将file_data进行分组,并统计每个分组的数量
7 groupy_area = file_data.groupby(by='lineID').count()
8 groupy_area
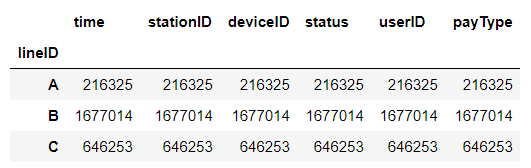
按“userID”一列从大到小排列
1 import math
2 import pandas as pd
3 import numpy as np
4 file_path = open('D:\地铁5.csv')
5 file_data = pd.read_csv(file_path)
6 #按“lineID”列将file_data进行分组,并统计每个分组的数量
7 groupy_area = file_data.groupby(by='lineID').count()
8 groupy_area
9 #按“userID”一列从大到小排列
10 groupy_area.sort_values(by=['userID'], ascending=False)
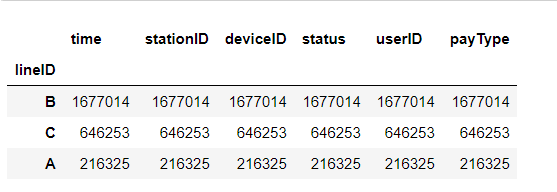
可以从图表中看出,B站点的人流量最大,A站点最小,B站点越容易发生人流拥堵问题
#
1 import math
2 import pandas as pd
3 import numpy as np
4 file_path = open('D:\地铁5.csv')
5 file_data = pd.read_csv(file_path)
6 #按“lineID”列将file_data进行分组,并统计每个分组的数量
7 groupy_area = file_data.groupby(by='stationID').count()
8 groupy_area
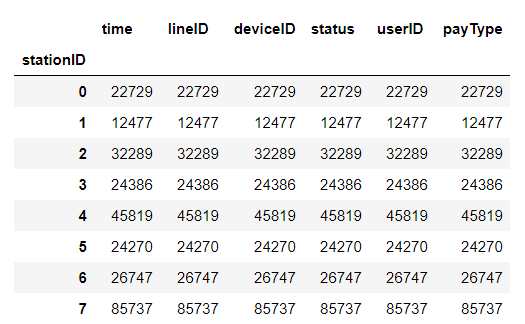
按“userID”一列从大到小排列
1 import math
2 import pandas as pd
3 import numpy as np
4 file_path = open('D:\地铁5.csv')
5 file_data = pd.read_csv(file_path)
6 #按“lineID”列将file_data进行分组,并统计每个分组的数量
7 groupy_area = file_data.groupby(by='stationID').count()
8 groupy_area
9 #按“userID”一列从大到小排列
10 groupy_area.sort_values(by=['userID'], ascending=False)
11 #new=_df['数量']
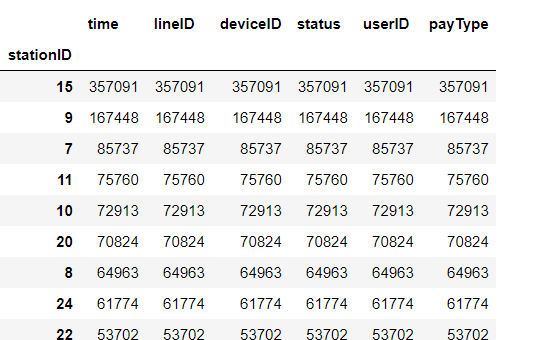
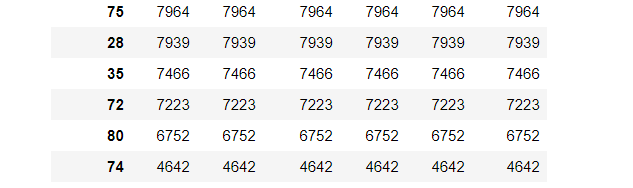
从上图数据可以看出,15号站点人流量最大,容易发生交通人流拥堵问题,74号站点人流量最少
按deviceID这一列将数据进行分组,并统计每个分组的数量
1 import math
2 import pandas as pd
3 import numpy as np
4 file_path = open('D:\地铁5.csv')
5 file_data = pd.read_csv(file_path)
6 #按“lineID”列将file_data进行分组,并统计每个分组的数量
7 groupy_area = file_data.groupby(by='deviceID').count()
8 groupy_area
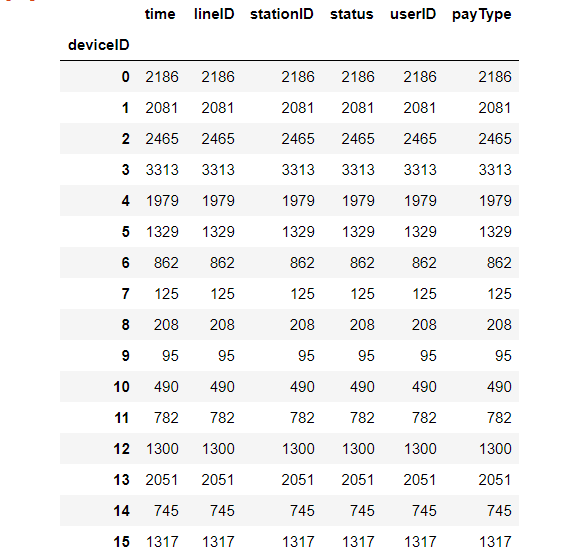
按“userID”一列从大到小排列
1 import math
2 import pandas as pd
3 import numpy as np
4 file_path = open('D:\地铁5.csv')
5 file_data = pd.read_csv(file_path)
6 #按“lineID”列将file_data进行分组,并统计每个分组的数量
7 groupy_area = file_data.groupby(by='deviceID').count()
8 groupy_area
9 #按“userID”一列从大到小排列
10 groupy_area.sort_values(by=['userID'], ascending=False)
11 #new=_df['数量']
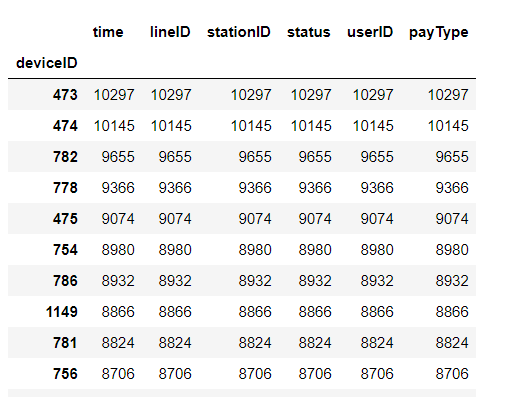
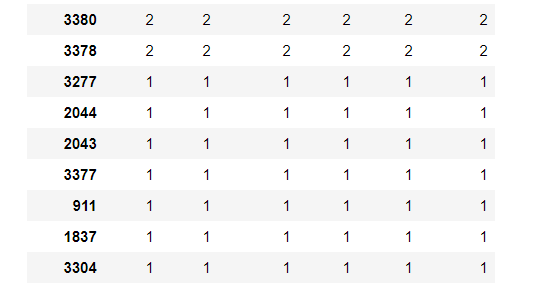
可以看出,474号设备的刷卡数最多,3130号设备的刷卡数最少
按照lineID分组,求每个分组的平均值
1 import pandas as np
2 import numpy as np
3 file_path = open('D:\地铁5.csv')
4 file_data = pd.read_csv(file_path)
5 #求平均值
6 groupy_area = file_data.groupby(by='lineID').mean()
7 groupy_area

按照stationID分组,求每个分组的平均值
1 import pandas as np
2 import numpy as np
3 file_path = open('D:\地铁5.csv')
4 file_data = pd.read_csv(file_path)
5 #求平均值
6 groupy_area = file_data.groupby(by='stationID').mean()
7 groupy_area
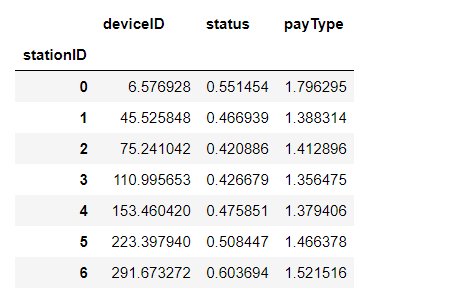
按照deviceID分组,求每个分组的平均值
1 import pandas as np
2 import numpy as np
3 file_path = open('D:\地铁5.csv')
4 file_data = pd.read_csv(file_path)
5 #求平均值
6 groupy_area = file_data.groupby(by='deviceID').mean()
7 groupy_area
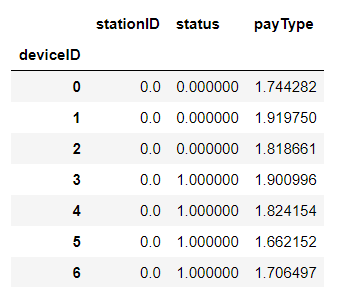
按照lineID分组,求每个分组的最大,最小值
1 import math
2 import pandas as pd
3 import numpy as np
4 file_path = open('D:\地铁5.csv')
5 file_data = pd.read_csv(file_path)
6 #求分组最大值
7 groupy_area = file_data.groupby(by='deviceID').max()
8 groupy_area
9 #求最小值
10 groupy_area = file_data.groupby(by='deviceID').min()
11 groupy_area
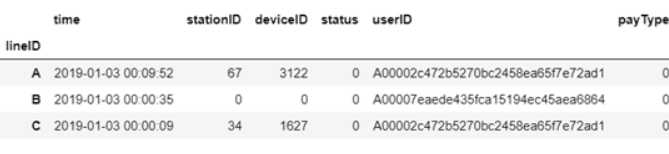
由此可以看出最大值和最小值
4.数据可视化
数据可视化借助于图形化手段,将数据分析结果直观、清晰、有效地展现出来。使得用户可以从不同的维度观察数据,对数据有更深入地理解。说明每个可视化图形表示的意义
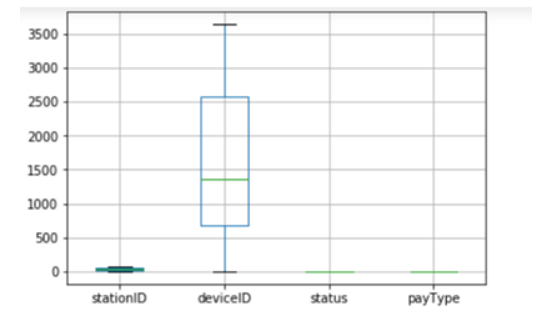
箱型图可以看出没有没有出现离散点,说明该数据集提供的数据很规范干净,没有出现异常值 。
1 #conding:utf8
2 #引入模块
3 import matplotlib.pyplot as plt
4 import pandas as pd
5 import numpy as np
6 pd.set_option('mpl_style','default')
7 #配置画板
8 fig = plt.figure()
9 fig.ax=plt.subplots()
10 #绘制箱型图
11 file_path = open('D:\地铁5.csv')
12 file_data = pd.read_csv(file_path)
13 #用ax参数指定在哪里绘制图片
14 file_data.boxplot(ax=ax)
15 plt.savefig('d:\plot.png')
16 plt.show()
分组显示箱形图,比如数据中有的来自1号站点、有的来自于2号站点,有的来自3号站点,而后以stationID进行分组,然后绘制箱形图;
1 #conding:utf8
2 #引入模块
3 import matplotlib.pyplot as plt
4 import pandas as pd
5 import numpy as np
6 pd.set_option('mpl_style','default')
7 #配置画板
8 fig = plt.figure()
9 fig.ax=plt.subplots()
10 #绘制箱型图
11 file_path = open('D:\地铁5.csv')
12 file_data = pd.read_csv(file_path)
13 #用ax参数指定在哪里绘制图片
14 file_data.boxplot(ax=ax,by='stastionID')
15 plt.savefig('d:\plottow.png')
16 plt.show()

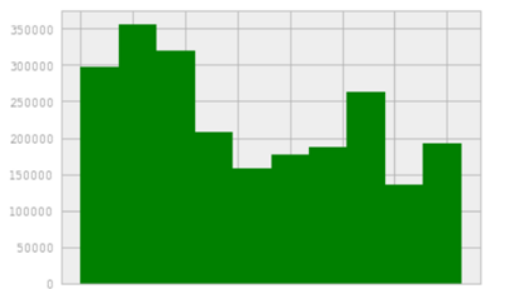
用函数绘制直方图
1 #直方图 2 import pandas as pd 3 import numpy as np 4 import matplotlib.pyplot as plt 5 import pandas as pd 6 import warnings 7 plt.rcParams['font.sans-serif'] = ['SimHei'] 8 plt.rcParams['axes.unicode_minus'] = False 9 10 filename = "地铁5.csv" 11 colnames=["time","lineID","stationID","deviceID","status","userID","payType"] 12 #skiprows用于指定跳过csv文件的头部的前几行(标题等无效数据,否则程序会报错) 13 df = pd.read_csv(filename,skiprows=1,names=colnames) 14 15 data=np.array(df['deviceID'][:30]) 16 index=df['stationID'][:30] 17 s = pd.Series(data,index) 18 s.name='地铁5' 19 20 s.plot(kind='bar',title='地铁五') 21 plt.grid() 22 plt.s 23 24 #2 25 plt.rcParams['font.sans-serif'] = ['SimHei'] 26 plt.rcParams['axes.unicode_minus'] = False 27 28 filename = "地铁5.csv" 29 colnames=["time","lineID","stationID","deviceID","status","userID","payType"] 30 #skiprows用于指定跳过csv文件的头部的前几行(标题等无效数据,否则程序会报错) 31 df = pd.read_csv(filename,skiprows=1,names=colnames) 32 33 data=np.array(df['deviceID'][1:30]) 34 index=df['stationID'][1:30] 35 s = pd.Series(data,index) 36 s.name='地铁5' 37 38 s.plot(kind='bar',title='地铁5') 39 plt.grid() 40 plt.show()
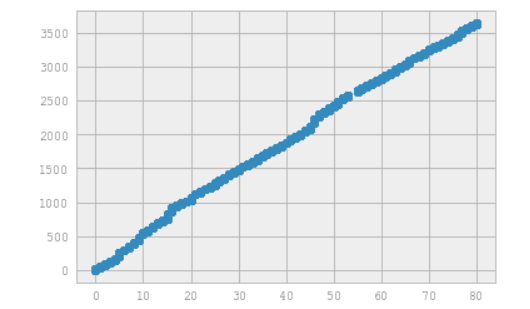
散点图
1 #散点图
2 import matplotlib.pyplot as plt
3 import pandas as pd
4 import numpy as np
5 #绘制散点图
6 file_path = open('D:\地铁5.csv')
7 file_data = pd.read_csv(file_path)
8 file_data
9 x=file_data.stationID
10 y=file_data.deviceID
11 plt.scatter(x,y)
12 plt.show()
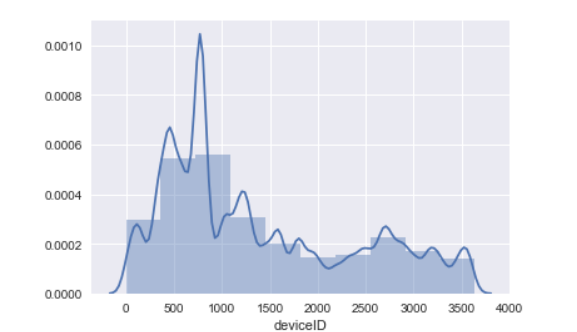
绘制带有核密度估计曲线的直方图
1 #曲线直方图
2 import matplotlib.pyplot as plt
3 import pandas as pd
4 import numpy as np
5 import seaborn as sns
6 #绘制核密度曲线直方图
7 file_path = open('D:\地铁5.csv')
8 file_data = pd.read_csv(file_path)
9 file_data
10 #用set()获取默认绘图
11 sns.set()
12 ax=sns.distplot(file_data.deviceID,bins=10)
13 ax
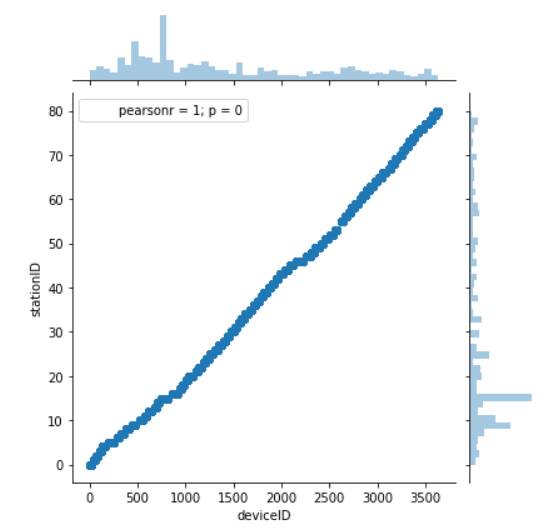
通过jointplot()创建多面板图形
1 #绘制多面板图形 2 import matplotlib.pyplot as plt 3 import pandas as pd 4 import numpy as np 5 import seaborn as sns 6 file_path = open('D:\地铁5.csv') 7 file_data = pd.read_csv(file_path) 8 file_data 9 #绘制直方图 10 #one=file_data.deviceID 11 ax=sns.jointplot(file_data.deviceID,file_data.stationID) 12 ax 13 plt.show()
5.附完整程序源代码(以及输出结果)
1 import pandas as pd 2 import numpy as up 3 file_path = open('D:\地铁1.csv') 4 file_path = open('D:\地铁2.csv') 5 file_path = open('D:\地铁3.csv') 6 file_path = open('D:\地铁4.csv') 7 file_path = open('D:\地铁5.csv') 8 file_path = open('D:\地铁6.csv') 9 file_path = open('D:\地铁7.csv') 10 file_path = open('D:\地铁8.csv') 11 file_path = open('D:\地铁9.csv') 12 file_path = open('D:\地铁10.csv') 13 file_data = pd.read_csv(file_path) 14 #查看空值,缺失值 15 file_data.isnull() 16 17 import pandas as pd 18 import numpy as up 19 file_path = open('D:\地铁1.csv') 20 file_path = open('D:\地铁2.csv') 21 file_path = open('D:\地铁3.csv') 22 file_path = open('D:\地铁4.csv') 23 file_path = open('D:\地铁5.csv') 24 file_path = open('D:\地铁6.csv') 25 file_path = open('D:\地铁7.csv') 26 file_path = open('D:\地铁8.csv') 27 file_path = open('D:\地铁9.csv') 28 file_path = open('D:\地铁10.csv') 29 file_data = pd.read_csv(file_path) 30 #查看缺失值,缺失值 31 file_data.notnull() 32 33 import pandas as np 34 import numpy as np 35 file_path = open('D:\地铁1.csv') 36 file_path = open('D:\地铁2.csv') 37 file_path = open('D:\地铁3.csv') 38 file_path = open('D:\地铁4.csv') 39 file_path = open('D:\地铁5.csv') 40 file_path = open('D:\地铁6.csv') 41 file_path = open('D:\地铁7.csv') 42 file_path = open('D:\地铁8.csv') 43 file_path = open('D:\地铁9.csv') 44 file_path = open('D:\地铁10.csv') 45 file_data = pd.read_csv(file_path) 46 #标记重复值 47 file_data.duplicated() 48 49 import pandas as pd 50 import numpy as np 51 #读取表数据 52 file_path = ('D:\地铁5.csv') 53 file_data1 = pd.read_csv(file_path) 54 file_path = ('D:\地铁6.csv') 55 file_data2 = pd.read_csv(file_path) 56 file_path = ('D:\地铁7.csv') 57 file_data3 = pd.read_csv(file_path) 58 file_path = ('D:\地铁8.csv') 59 file_data4 = pd.read_csv(file_path) 60 file_path = ('D:\地铁9.csv') 61 file_data5 = pd.read_csv(file_path) 62 file_path = ('D:\地铁10.csv') 63 file_data6 = pd.read_csv(file_path) 64 frame=[file_datal,file_data2,file_data3,file_data4,file_data5,file_data6] 65 #相同字段的表首位相接,合并表 66 result=pd.concat(frame) 67 result 68 69 import pandas as pd 70 import numpy as np 71 #读取地铁站三条线路所有站点的刷卡数据记录 72 #读取地铁站三条线路所有站点的刷卡数据记录 73 file_path = open('D:\地铁5.csv') 74 file_path = open('D:\地铁6.csv') 75 file_path = open('D:\地铁7.csv') 76 file_path = open('D:\地铁8.csv') 77 file_path = open('D:\地铁9.csv') 78 file_path = open('D:\地铁10.csv') 79 file_data = pd.read_csv(file_path) 80 file_data 81 82 #所有站点的刷卡数据记录 83 import pandas as pd 84 import numpy as np 85 86 #读取所有站点的刷卡数据记录 87 file_path = open('D:\地铁5.csv') 88 file_path = open('D:\地铁6.csv') 89 file_path = open('D:\地铁7.csv') 90 file_path = open('D:\地铁8.csv') 91 file_path = open('D:\地铁9.csv') 92 file_path = open('D:\地铁10.csv') 93 file_data = pd.read_csv(file_path) 94 file_data 95 96 import pandas as pd 97 import numpy as np 98 file_path = open('D:\地铁5.csv') 99 file_data = pd.read_csv(file_path) 100 #创建一个DataFrame对象,该对象只有一列列数据:lineID[线路ID] 101 new_df = pd.DataFrame({'lineID':file_data['lineID'].unique()}) 102 new_df 103 104 import math 105 import pandas as pd 106 import numpy as np 107 file_path = open('D:\地铁5.csv') 108 file_data = pd.read_csv(file_path) 109 #按“lineID”列将file_data进行分组,并统计每个分组的数量 110 groupy_area = file_data.groupby(by='lineID').count() 111 groupy_area 112 113 import math 114 import pandas as pd 115 import numpy as np 116 file_path = open('D:\地铁5.csv') 117 file_data = pd.read_csv(file_path) 118 #按“lineID”列将file_data进行分组,并统计每个分组的数量 119 groupy_area = file_data.groupby(by='lineID').count() 120 groupy_area 121 #按“userID”一列从大到小排列 122 groupy_area.sort_values(by=['userID'], ascending=False) 123 124 import math 125 import pandas as pd 126 import numpy as np 127 file_path = open('D:\地铁5.csv') 128 file_data = pd.read_csv(file_path) 129 #按“lineID”列将file_data进行分组,并统计每个分组的数量 130 groupy_area = file_data.groupby(by='stationID').count() 131 groupy_area 132 133 import math 134 import pandas as pd 135 import numpy as np 136 file_path = open('D:\地铁5.csv') 137 file_data = pd.read_csv(file_path) 138 #按“lineID”列将file_data进行分组,并统计每个分组的数量 139 groupy_area = file_data.groupby(by='stationID').count() 140 groupy_area 141 #按“userID”一列从大到小排列 142 groupy_area.sort_values(by=['userID'], ascending=False) 143 #new=_df['数量'] 144 145 import math 146 import pandas as pd 147 import numpy as np 148 file_path = open('D:\地铁5.csv') 149 file_data = pd.read_csv(file_path) 150 #按“lineID”列将file_data进行分组,并统计每个分组的数量 151 groupy_area = file_data.groupby(by='deviceID').count() 152 groupy_area 153 154 import math 155 import pandas as pd 156 import numpy as np 157 file_path = open('D:\地铁5.csv') 158 file_data = pd.read_csv(file_path) 159 #按“lineID”列将file_data进行分组,并统计每个分组的数量 160 groupy_area = file_data.groupby(by='deviceID').count() 161 groupy_area 162 #按“userID”一列从大到小排列 163 groupy_area.sort_values(by=['userID'], ascending=False) 164 #new=_df['数量'] 165 166 import pandas as np 167 import numpy as np 168 file_path = open('D:\地铁5.csv') 169 file_data = pd.read_csv(file_path) 170 #求平均值 171 groupy_area = file_data.groupby(by='lineID').mean() 172 groupy_area 173 174 import pandas as np 175 import numpy as np 176 file_path = open('D:\地铁5.csv') 177 file_data = pd.read_csv(file_path) 178 #求平均值 179 groupy_area = file_data.groupby(by='stationID').mean() 180 groupy_area 181 182 import pandas as np 183 import numpy as np 184 file_path = open('D:\地铁5.csv') 185 file_data = pd.read_csv(file_path) 186 #求平均值 187 groupy_area = file_data.groupby(by='deviceID').mean() 188 groupy_area 189 190 import math 191 import pandas as pd 192 import numpy as np 193 file_path = open('D:\地铁5.csv') 194 file_data = pd.read_csv(file_path) 195 #求分组最大值 196 groupy_area = file_data.groupby(by='deviceID').max() 197 groupy_area 198 #求最小值 199 groupy_area = file_data.groupby(by='deviceID').min() 200 groupy_area 201 202 #conding:utf8 203 #引入模块 204 import matplotlib.pyplot as plt 205 import pandas as pd 206 import numpy as np 207 pd.set_option('mpl_style','default') 208 #配置画板 209 fig = plt.figure() 210 fig.ax=plt.subplots() 211 #绘制箱型图 212 file_path = open('D:\地铁5.csv') 213 file_data = pd.read_csv(file_path) 214 #用ax参数指定在哪里绘制图片 215 file_data.boxplot(ax=ax) 216 plt.savefig('d:\plot.png') 217 plt.show() 218 219 #conding:utf8 220 #引入模块 221 import matplotlib.pyplot as plt 222 import pandas as pd 223 import numpy as np 224 pd.set_option('mpl_style','default') 225 #配置画板 226 fig = plt.figure() 227 fig.ax=plt.subplots() 228 #绘制箱型图 229 file_path = open('D:\地铁5.csv') 230 file_data = pd.read_csv(file_path) 231 #用ax参数指定在哪里绘制图片 232 file_data.boxplot(ax=ax,by='stastionID') 233 plt.savefig('d:\plottow.png') 234 plt.show() 235 236 #直方图 237 import pandas as pd 238 import numpy as np 239 import matplotlib.pyplot as plt 240 import pandas as pd 241 import warnings 242 plt.rcParams['font.sans-serif'] = ['SimHei'] 243 plt.rcParams['axes.unicode_minus'] = False 244 filename = "地铁5.csv" 245 colnames=["time","lineID","stationID","deviceID","status","userID","payType"] 246 #skiprows用于指定跳过csv文件的头部的前几行(标题等无效数据,否则程序会报错) 247 df = pd.read_csv(filename,skiprows=1,names=colnames) 248 data=np.array(df['deviceID'][:30]) 249 index=df['stationID'][:30] 250 s = pd.Series(data,index) 251 s.name='地铁5' 252 s.plot(kind='bar',title='地铁五') 253 plt.grid() 254 plt.s 255 #2 256 plt.rcParams['font.sans-serif'] = ['SimHei'] 257 plt.rcParams['axes.unicode_minus'] = False 258 filename = "地铁5.csv" 259 colnames=["time","lineID","stationID","deviceID","status","userID","payType"] 260 #skiprows用于指定跳过csv文件的头部的前几行(标题等无效数据,否则程序会报错) 261 df = pd.read_csv(filename,skiprows=1,names=colnames) 262 data=np.array(df['deviceID'][1:30]) 263 index=df['stationID'][1:30] 264 s = pd.Series(data,index) 265 s.name='地铁5' 266 s.plot(kind='bar',title='地铁5') 267 plt.grid() 268 plt.show() 269 270 #散点图 271 import matplotlib.pyplot as plt 272 import pandas as pd 273 import numpy as np 274 #绘制散点图 275 file_path = open('D:\地铁5.csv') 276 file_data = pd.read_csv(file_path) 277 file_data 278 x=file_data.stationID 279 y=file_data.deviceID 280 plt.scatter(x,y) 281 plt.show() 282 283 #曲线直方图 284 import matplotlib.pyplot as plt 285 import pandas as pd 286 import numpy as np 287 import seaborn as sns 288 #绘制核密度曲线直方图 289 file_path = open('D:\地铁5.csv') 290 file_data = pd.read_csv(file_path) 291 file_data 292 #用set()获取默认绘图 293 sns.set() 294 ax=sns.distplot(file_data.deviceID,bins=10) 295 ax
(四)、总结(10 分)
对本课程设计的整体完成情况做一个总结,包括:
1.通过对数据分析和挖掘,得到哪些有益的结论?是否达到预期的目标?
2.自己在完成此设计过程中,得到哪些收获?以及要改进的建议
通过这次利用Pandas数据分析工具地铁站乘客人流量数据,让我掌握了最基础的数据分析知识,体验了数据分析的乐趣,包括数据预处理,数据清洗,异常值的查找等,数据的合并和分组及聚合,还有数据可视化来直观的观察.分析数据。虽然学的知识比较简单,但是激发了我对数据分析的学习热情,相信只要继续持续学习下去,我的数据分析知识储备和数据分析能力也会更近一步,同时也让我明白了在当今大数据,云计算,物联网,人工智能迅速发展的新时代,人们每天产生的数据蕴藏着巨大的价值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号