一点关于深度学习实验的思考:重复实验
前言
最近做深度学习实验,时常会感叹深度学习就像炼丹一样,效果好坏似乎就像上帝在掷骰子。后面反思了一下自己的实验方法,再反思了一下做实验的目的。
什么时候我们可以自信的说出我的模型、我的方法、我的改进是有效的呢?
固定随机数种子
以往做实验的方法,是通过固定一个随机数种子,然后在这个随机数种子上做到比别人好的效果,那么我的结果既是可以复现的,又确实是比别人好。那么,我能不能说自己的模型比别人好呢?我认为还不够确信,因为有可能是因为这个随机数种子上比别人好,但是换一个随机数种子,效果不一定比别人好。
多次重复实验
为了让自己可以更加确信方法的有效性,可以通过多次重复实验,比较在不同随机数种子的情况下,实验的均值是否比别人好。这种方法可以稍微增加一些自信心,这里又有一个新的问题了,实验的重复次数应该有多少次呢?重复了多少次实验,我们才可以认为比较有信心地说出自己地改进要更加好呢?我们又有多少自信心认为自己的改进是更好的呢?
我们可以从概率论和数理统计相关的知识中,获取到相关的方法,这个方法就是假设检验。
假设检验
浙大《概率论与数理统计》 第四版中,第八章假设检验里给出了相关的判断方法。首先来学习一个基础的例子。
判断机器是否正常工作
(例子来自书上)例1:某车间用一台包装机包装葡萄糖,袋装糖的净重是一个随机变量,它服从正态分布,当机器正常时,其均值为 0.5 kg,标准差为 0.015 kg。某日开工后为检验包装机是否正常,随机地抽取它所包装的糖 9 袋,称得净重为(kg)
[0.497, 0.506, 0.518, 0.524, 0.498, 0.511, 0.520, 0.515, 0.512]
问机器是否正常?
分析
均值:0.5
标准差:0.015
样本数量:9
样本均值:0.5112
这九个样本是服从正态分布的,我们可以计算这一组样本的统计量 \(\frac{\overline{X} - \mu}{\sigma / \sqrt{n}}\)。
在此之前,可以先定义出一个假设:
原假设 \(H_0\): 机器正常工作,即 \(\mu = \mu_0 = 0.5\)
备择假设 \(H_1\):机器不正常工作,即 \(\mu \ne \mu_0\)
假设检验做的事情就是,判断多大概率原假设是对的。假设我们希望控制原假设错误的概率不要超过 \(\alpha\),那么我们就可以定义出下面的事件。
于是,我们可以将假设量代入其中,这意味着这组样本的统计量如果落在了正态分布的两端,则这组样本显示出了有些不对劲,我们可以有 \(1 - \alpha\) 的自信心说 \(H_0\) 是不对的。
带进一个具体的数值,比如 \(\alpha = 0.05\),我们需要计算出 0.05 对应的左右分位点。使用 python 的 scipy stats 模块,可以计算出来。
from scipy import stats
a = 0.05
left = stats.norm.ppf(a) # -1.6448536269514729
right = stats.norm.isf(a) # 1.6448536269514729
k = stats.norm.interval(1-a) # (-1.959963984540054, 1.959963984540054)
# 正态分布:stats.norm
# t 分布:stats.t
# 卡方分布:stats.chi2
# F 分布:stats.f
# cdf 积分函数:stats.norm.cdf
取 k = 1.96。
然后我们计算出统计量的值。
于是我们可以知道这个 2.23 是落在了正态分布中高于 k 的位置,也就是小概率的事情发生了,而我们认为这是不太可能的,因此我们拒绝接受 \(H_0\)。
使用这个网站 我们可以看到可视化效果。
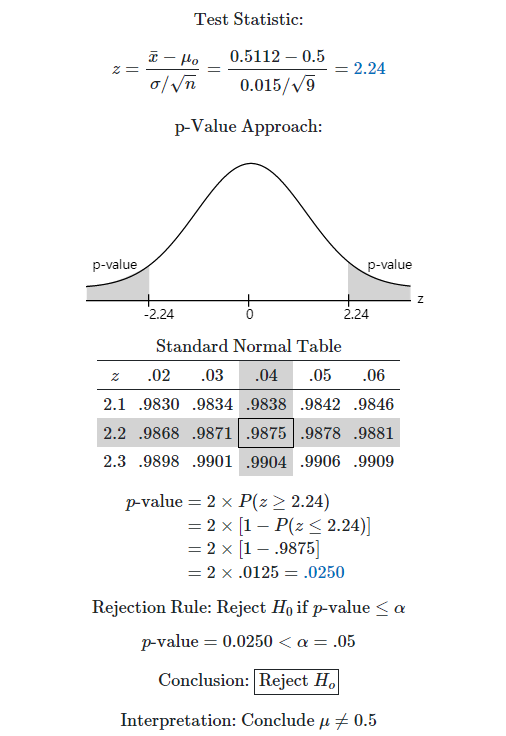
这个网站给出了一个 p-value 的方法,p-value 就是拒绝域的面积大小,比如上图中,拒绝域的面积大小是 0.025,比显著性水平 0.05 要小,所以要拒绝原假设。如果拒绝域的面积足够大,那么我们就可以说非常显著。\(\alpha\) 越小越好,那么 p-value 越大越好,p-value 越大,那么犯错的概率越小。p-value 的直观是,一个事件发生的概率,我们往往将这个事件定义为比较困难的事情,如果从采样的数据发生的概率非常小,即 p-value 非常小,概率很小都发生了,我们就应该认为这组数据其实是有问题的。假设检验就是基于这样一个朴素的思想:小概率的事件几乎不可能发生,当然还是有犯错的概率的,但是概率不大。p-value 的定义是:“由检验统计量的样本观察值得出的原假设可被拒绝的最小显著水平。”。
一般认为
- \(p \le 0.01\) 拒绝 \(H_0\) 是高度显著。
- \(0.01 < p \le 0.05\) 拒绝 \(H_0\) 是显著的,拒绝的依据足够强
- \(0.05 < p \le 0.1\) 接受 \(H_0\) 是弱的,不够显著的
- \(p > 0.1\),没有理由拒绝 \(H_0\)
p-value 这个方法在实验性的科学中更加的常见,一开始搜索怎么做实验比较科学,给出的方法就是 p-value,而它的背后是假设检验相关的知识。
附上 python 代码
import math
from scipy import stats
def mean(data):
return sum(data) / len(data)
def variance(data):
data_mean = mean(data)
acc = 0
for x in data:
acc += (x - data_mean) ** 2
return acc / (len(data) - 1)
alpha = 0.05
data = [0.497, 0.506, 0.518, 0.524, 0.498, 0.511, 0.520, 0.515, 0.512]
z = (mean(data) - 0.5) / (0.015 / math.sqrt(10))
interval = stats.norm.interval(1 - alpha)
pvalue = 2 * (1 - stats.norm.cdf(z))
print('mean: ', mean(data))
print('variance: ', variance(data))
print('Accept: ', interval[0] < z < interval[1])
print('p-value: ', pvalue)
新模型的假设检验
在书上 P189 页,给出了一个表,讲的是在不同的条件下,应该如何选择检验统计量。我们可以根据已知信息,选择一个统计量。
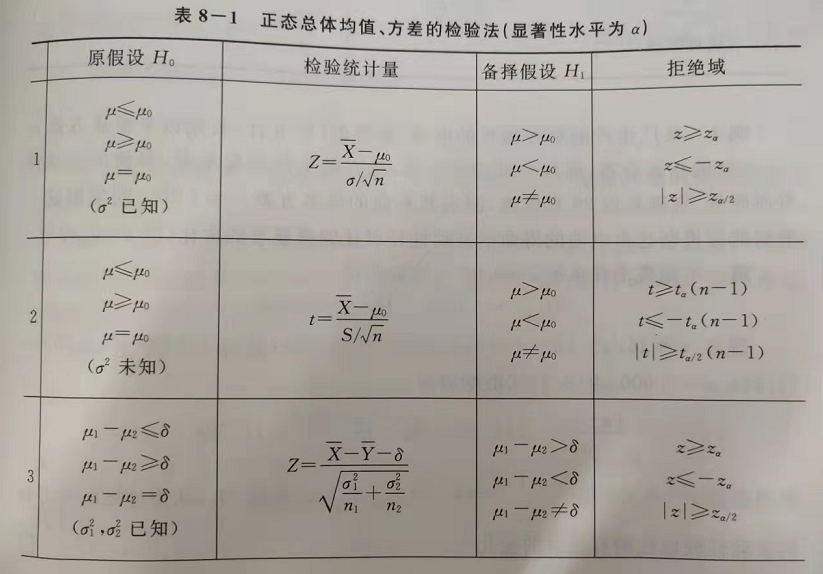
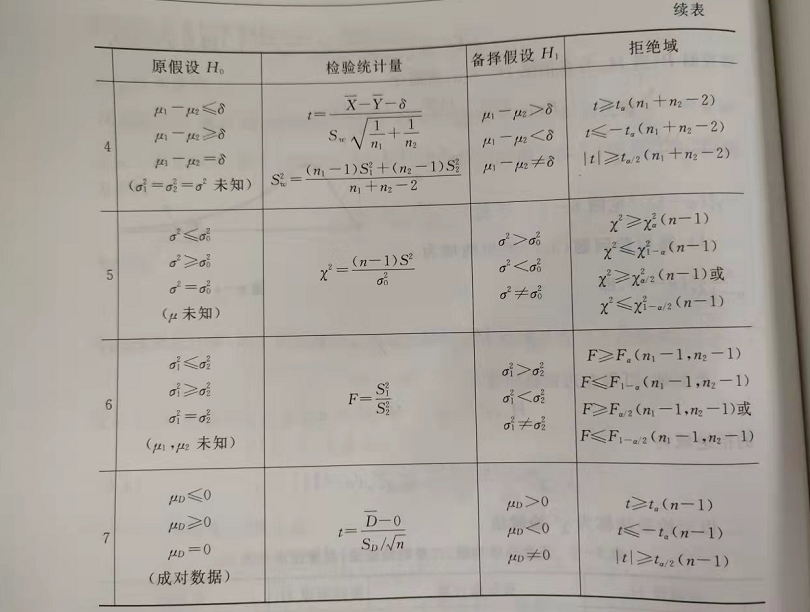
现在回到我们一开始的问题上来:
什么时候我们可以自信的说出我的模型、我的方法、我的改进是有效的呢?
原方法和新方法的总体均值和总体方差是未知的,但是原方法和新方法的样本均值和样本方差是已知的。我们可以参考这个方法看看:https://zhidao.baidu.com/question/514551513.html ,也可以参考这个看看 https://courses.lumenlearning.com/introstats1/chapter/two-population-means-with-unknown-standard-deviations/
使用 t 检验,估计量类似总体方差知道的公式。
t 检验的参数为
具体算一个例子吧
x_data = [0.8186842105263158, 0.8510526315789474, 0.8357894736842105, 0.8323684210526315, 0.8603947368421052, 0.8101315789473684]
y_data = [0.8163157894736842, 0.8475, 0.8060526315789474, 0.8305263157894737, 0.8330263157894737, 0.7835526315789474]
alpha: 0.05
PS: 样本方差的计算方法和总体方差计算方差是有差别的,样本方差是除以 \(\frac{1}{n-1}\),而不是 \(\frac{1}{n}\)。
import math
from scipy import stats
def mean(data):
return sum(data) / len(data)
def variance(data):
data_mean = mean(data)
acc = 0
for x in data:
acc += (x - data_mean) ** 2
return acc / (len(data) - 1)
alpha = 0.05
x_data = [0.8186842105263158, 0.8510526315789474, 0.8357894736842105, 0.8323684210526315, 0.8603947368421052, 0.8101315789473684]
y_data = [0.8163157894736842, 0.8475, 0.8060526315789474, 0.8305263157894737, 0.8330263157894737, 0.7835526315789474]
m = len(x_data)
x = mean(x_data)
s1 = variance(x_data)
n = len(y_data)
y = mean(y_data)
s2 = variance(y_data)
s0 = s1 / m + s2 / n
t = (x - y) / math.sqrt(s0)
l = (s0 ** 2) / ((s1 ** 2) / (m * m * (m - 1)) + (s2 ** 2) / (n * n * (n - 1)))
right = stats.t.isf(alpha, l)
pvalue = 1 - stats.t.cdf(t, l)
print('mean: ', x, y)
print('var: ', s1, s2)
print('t: ', t)
print('percent point: ', right)
print('Reject: ', t < -right)
print('p-value:', pvalue)
输出如下信息:
mean: 0.8347368421052632 0.8194956140350879
var: 0.0003588711911357336 0.0005143449907663901
t: 1.263382042237795
percent point: 1.8183089273595996
Reject: False
p-value: 0.11799684300051694
可以看到估计量 \(T\) 是落在上述范围的,因此新的方法是有提升的。
基于成对数据的检验(t 检验)
除了使用两个未知总体均值和总体方差的正态总体,我们还可以使用基于成对数据的检验,这种方法可以用来检查两种方法、两种设备的差异。
实验的时候,除了改进的地方,保持其他配置不变,比如随机数种子、超参数等,然后记录每一次实验,两种方法的差值。这个差值的样本估计量是服从 t 检验的。
算例
x_data = [0.8186842105263158, 0.8510526315789474, 0.8357894736842105, 0.8323684210526315, 0.8603947368421052, 0.8101315789473684]
y_data = [0.8163157894736842, 0.8475, 0.8060526315789474, 0.8305263157894737, 0.8330263157894737, 0.7835526315789474]
d_data = [x_data[i] - y_data[i] for i in range(len(x_data))]
alpha: 0.05
自由度是 n - 1,alpha 是 0.05。
原假设 \(H_0\):改进有效,即 \(\mu_D \ge 0\)
备择假设 \(H_1\):改进不显著,即 \(\mu_D < 0\)
因此,我们需要计算 t 分布的上半部分的分位点。
>>> stats.t.isf(0.05, 5)
2.0150483726691575
拒绝域是:\(t \le -t_{\alpha}(n-1)\)
可以看到,我们算出来的 t 是不落在这个范围内的,因此我们接受原假设,即改进是有效的。
附上代码
import math
from scipy import stats
def mean(data):
return sum(data) / len(data)
def variance(data):
data_mean = mean(data)
acc = 0
for x in data:
acc += (x - data_mean) ** 2
return acc / (len(data) - 1)
alpha = 0.05
x_data = [0.8186842105263158, 0.8510526315789474, 0.8357894736842105, 0.8323684210526315, 0.8603947368421052, 0.8101315789473684]
y_data = [0.8163157894736842, 0.8475, 0.8060526315789474, 0.8305263157894737, 0.8330263157894737, 0.7835526315789474]
d_data = [x_data[i] - y_data[i] for i in range(len(x_data))]
d = mean(d_data)
sd = variance(d_data)
n = len(d_data)
t = d / (math.sqrt(sd) / math.sqrt(n))
# t = (d - 0.02) / (math.sqrt(sd) / math.sqrt(n))
# 如果我们想验证我们的犯法可以提升 2 个百分点
right = stats.t.isf(alpha, n - 1)
pvalue = stats.t.cdf(t, n - 1)
print(d, sd)
print('t: ', t)
print('right: ', right)
print('Reject: ', t < -right)
print('p-value: ', pvalue)
输出:
0.015241228070175417 0.00019352089104339773
t: 2.683685746701147
right: 2.0150483726691575
Reject: False
p-value: 0.9781864318696657 # 此处的输出非常大,是没问题的
# 在这种情况下,p-value 是观察值左边形成的面积
实验次数
实验次数多少次比较合理呢?
先进行一个简单实验探索一下。
import math
from scipy import stats
def mean(data):
return sum(data) / len(data)
def variance(data):
data_mean = mean(data)
acc = 0
for x in data:
acc += (x - data_mean) ** 2
return acc / (len(data) - 1)
alpha = 0.05
x_data = [0.8186842105263158, 0.8510526315789474, 0.8357894736842105, 0.8323684210526315, 0.8603947368421052, 0.8101315789473684]
y_data = [0.8163157894736842, 0.8475, 0.8060526315789474, 0.8305263157894737, 0.8330263157894737, 0.7835526315789474]
d_data = [x_data[i] - y_data[i] for i in range(len(x_data))]
d = mean(d_data)
sd = variance(d_data)
n = 10 # len(d_data)
t = (d - 0.02) / (math.sqrt(sd) / math.sqrt(n))
right = stats.t.isf(alpha, n - 1)
pvalue = stats.t.cdf(t, n - 1)
print(d, sd)
print('t: ', t)
print('right: ', right)
print('Reject: ', t < -right)
print('p-value: ', pvalue)
假设我们想要验证新方法比就旧方法提升了 2%,修改上述的 t 值计算公式。然后通过修改上述代码中的 \(n\) 的值,比如修改成不同的数值,有如下 p-value。
均值:0.015241228070175417
方差:0.00019352089104339773
n = 10: 0.15374531380079653
n = 20: 0.07126780824989196
n = 30: 0.0355430266450179
我们可以看到,随着实验次数的增多,p-value 越来越小。因为均值实际上是 0.01524,所以随着实验次数的增多,我们就越来越难说提升可以达到 2%。
给出显著性水平以控制犯第一类错误的概率,而犯第二类错误的概率则依赖于样本容量的选择。
第一类错误是原假设为真却拒绝,第二类错误是原假设为假却没拒绝第一类错误和第二类错误的关系是什么? - 小河的回答 - 知乎
https://www.zhihu.com/question/20993864/answer/958223021上面的回答中,举了一个例子。
犯第一类错误的概率,一般是我们设置的显著性水平,可以设置的很小,0.05。
而犯第二类错误的概率,取决于假设的内容和实际情况,和第一类错误并没有直接关系。
比如一批产品中次品有 10%,但是我们假设次品率是 5%,然后进行一次抽样,发现没有次品,于是我们接受了次品率是 5% 的假设。然后抽样一次得到正品的概率是 90%,也就是说我们犯第一类错误的概率是 90%。
书上关于这一部分的讨论也是关于如何控制第二类错误的犯错概率的,而且已经有点过于高深,看不太懂了。
在深度学习实验中,实验的代价是比较高的,每做一次实验事件都很长。另外,我们往往是希望控制第一类错误的犯错概率。
基于此,可以尝试几个经验值:3、5、10 次,通过多次实验,计算 p-value,判断一个方法是否足够好。
总结
这篇文章尝试思考深度学习实验,如何将实验做的更加科学。通过重复多次实验和假设检验,我们可以检验一个新的算法是否足够好,我们可以计算出我们有多少自信心(显著性水平)说出新的方法有多好。
future work:关于实验次数,最终还是没有思考太清楚,建议是使用几个常见的经验值,重复实验 3、5、10 次,然后计算 p-value 看看是否效果是否足够显著。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号