MindSpore 开源代码评注比赛有感
前言
10月30日,参加了第五届开源创新大赛,开源代码评注赛赛道的决赛答辩。赛前用心做了 PPT,更新迭代了 5 个版本,认真准备了讲稿。决赛答辩规划是 8 分钟答辩,6 分钟问答。这篇博客将本次答辩的 PPT 和讲稿分享出来,讲稿 2400 个字,上场答辩的时候用了比较快的语速,并且选择性的跳过了一些细节,在规定的时间内完成了答辩。问答环节,在回答评委老师问题的时候,出现了网络故障等原因,没有将老师的疑惑回答好。
虽然这次结果并不好,但是我们的分享得到了来自 MindSpore 的评委老师的肯定,能把技术分享讲的比刚入职半年的同事都要好,甚至觉得我们和 MindSpore 是有合作的,我们不是啊🤣,我们只是外部贡献者而已啊,凭借自己对框架的理解,认真做事,认真准备讲稿,比赛前模拟讲了两遍。
说说这次的比赛收获吧。
- 第一,对 MindSpore 框架的理解更加深入了一些,通过跟踪算子的执行流程,对整体框架功能的分层抽象理解的更加清楚。
- 第二,关于做演讲和技术分享。这次比赛,非常认真准备,改了 5 次 PPT,改 PPT 的过程中,发现对某些细节不够理解,又返回去看代码,又加深了对代码的理解;写了一份讲稿,之前觉得自己的演讲能力还行,实际上如果只是对着 PPT 即兴讲肯定不够好,如果能准备一份讲稿,那么在做 PPT 上付出的努力会得到加倍的汇报。
- 第三,和师弟合作参加比赛。这次比赛过程,和师弟一起结对编程,写代码评注,一起阅读分析代码,过程挺愉快的。最后提交作品,不小心进入了决赛。在决赛前,一起认真做 PPT,师弟主动承担并按时完成相应的任务,靠谱。在比赛前模拟了两次,师弟帮我计时,帮我指出问题,提出的建议中肯,对提高演讲结果有帮助。期待再次合作。
- 第四,认真做事,全身心投入。在做 PPT 的过程中,非常专注认真,努力把一件事情做好、做完善的过程是非常快乐的。这一点,需要我在其他方面持续践行。
题目
(开场白)各位评委老师、参赛选手,各位听众,大家下午好。首先简单介绍一下我们的队伍,我们是 “你的代码写的真棒” 队,成员有 MindSpore Contributor,贡献过一些算子,用MindSpore写过深度学习模型(复现 vgg,文本分类,deepfm)。因此,在我们写博客分享的时候,非常希望我们的博客是可以帮助到开发者理解 MindSpore,帮助新手快速上手构建代码,进行算子开发和算子优化。
(题目)今天我们队给大家分享的题目是 “MindSpore 算子之旅,从 Python 前端到 Op Kernel”。

问题
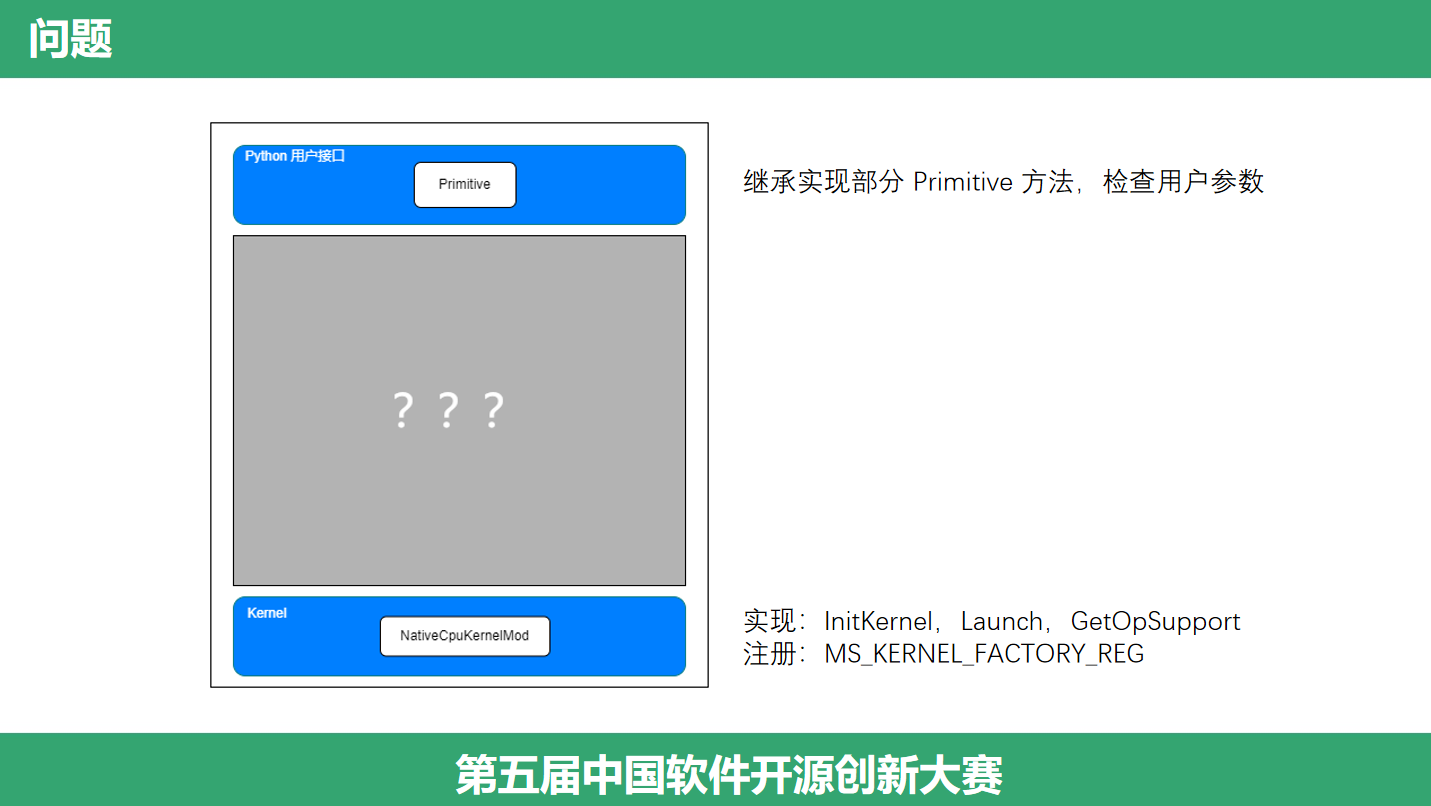
(提出问题)我们在开发算子的时候,深深体会到了框架抽象带来的方便,作为算子开发人员,我们往往只需要写出最核心的逻辑即可,上层我们关心Python接口,底层我们关心算子实现。可是,每次写算子的时候,其他部分对我们来说都是一个黑箱子,于是我们想要打开这个黑箱子,这是我们阅读 MindSpore 源码的动机,接下来我们一起跟随一个算子的执行流程,开启今天的 MindSpore 算子之旅吧。
目录
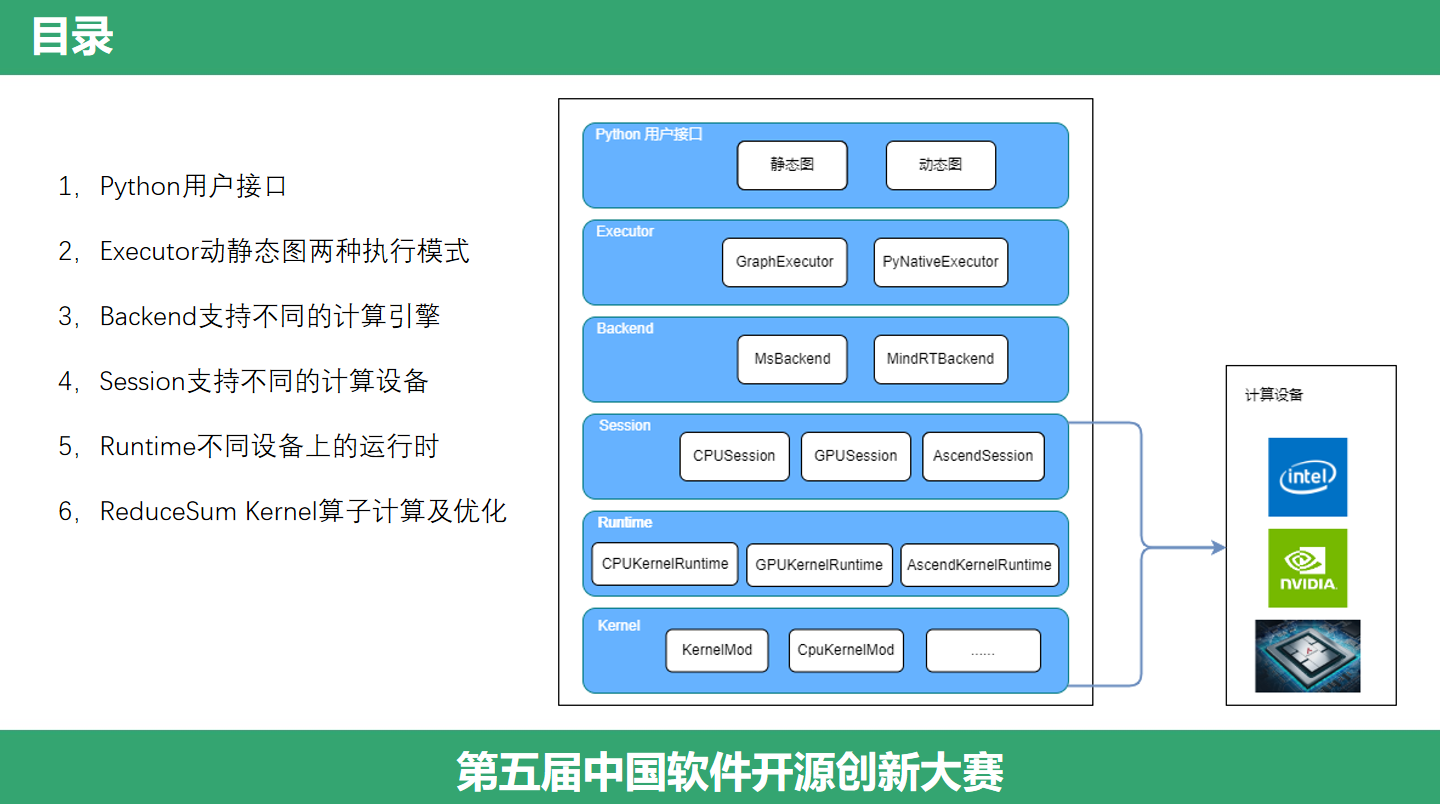
(层级)首先,看一下目录。我们采用自顶向下的方式分析一个算子在 MindSpore 中的执行流程,从最前端的 Python 接口,到中间的执行调度 Executor、Backend,再往下是设备关联的 Session、Runtime,最后到算子是如何执行、如何优化的。
Python 前端
(Python 接口)在训练神经网络的时候,有时候我们需要对一个向量进行求和,或者对向量的某一个维度进行求和,此时 ReduceSum 算子可以很好的帮助我们完成任务。默认情况下,不指定规约维度,这个算子将会对向量的所有元素规约求和,将所有的元素加起来。我们还可以指定维度进行规约,比如按行规约、按列规约,可以得到某行或者某列规约的结果。那么在 MindSpore 中如何写这个操作呢?这里我们提供了两个例子,一个例子是直接使用这个 Op,创建对象,然后调用它,另一个例子通过搭建网络结构的方式来计算。注意到,这两个例子的开头部分,我们写了一行,ms.set_context,设置了执行的模式,执行的设备。

Executor
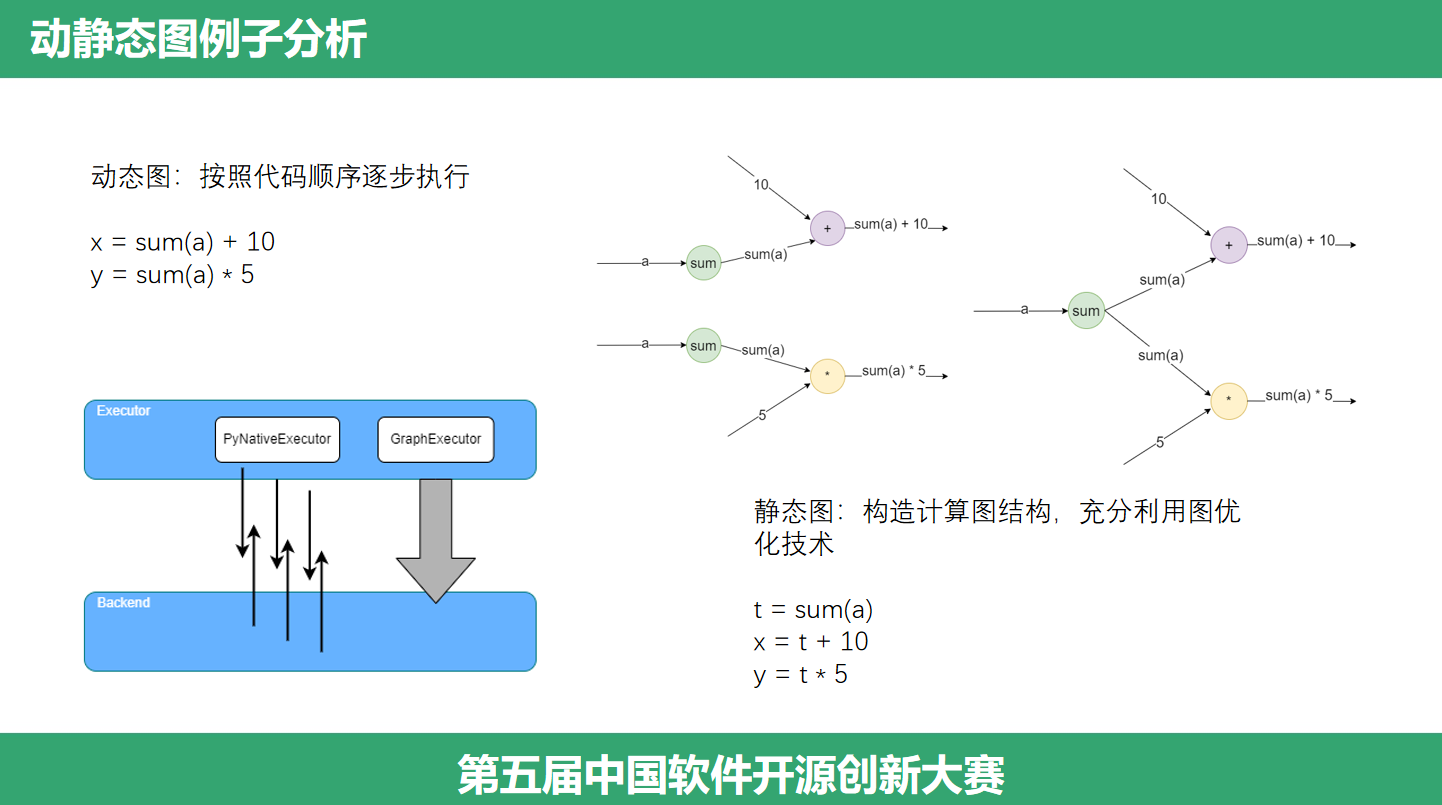
(Executor)例子1使用的是 PYNATIVE 模式,也就是常说的动态图模式,常用的 Pytorch 就是动态图的;例子2使用的是GRAPH模式,即静态图模式,过去的tensorflow1就是静态图的。而mindspore,同时支持静态图和动态图两种模式,并且我们可以使用一行代码实现动静态转换,开发者可以同时享受到动态图和静态图的优点。为了同时支持两种计算图模式,引入了Executor层,来分别处理动静态模式。静态图模式使用 GraphExecutor 来实现,它先构造神经网络结构,充分利用图优化技术减少调度和访存开销,高性能执行计算图。动态图模式使用 PyNativeExecutor 模式来实现,它按照代码编写顺序逐步执行,计算操作将下发到设备上执行并获取计算结果,方便编写和调试。

动静态图例子分析
(具体例子)接下来,我们结合一个例子分析动静态图各自的特点。动态图模式代码将逐行执行,用户可以看到中间的计算结果,方便调试,注意到这里 sum(a) 将会被执行两次;在静态图模式,可以充分利用图优化技术,提取公共的子表达式,减少冗余的计算,比如我们使用一个临时变量 t = sum(a),然后替换重复计算。动态图每一步执行将会通过 PyNativeExecutor 和 Backend 进行交互,静态图则通过 GraphExecutor 和 Backend 交互,构建整个计算图然后优化。
Backend
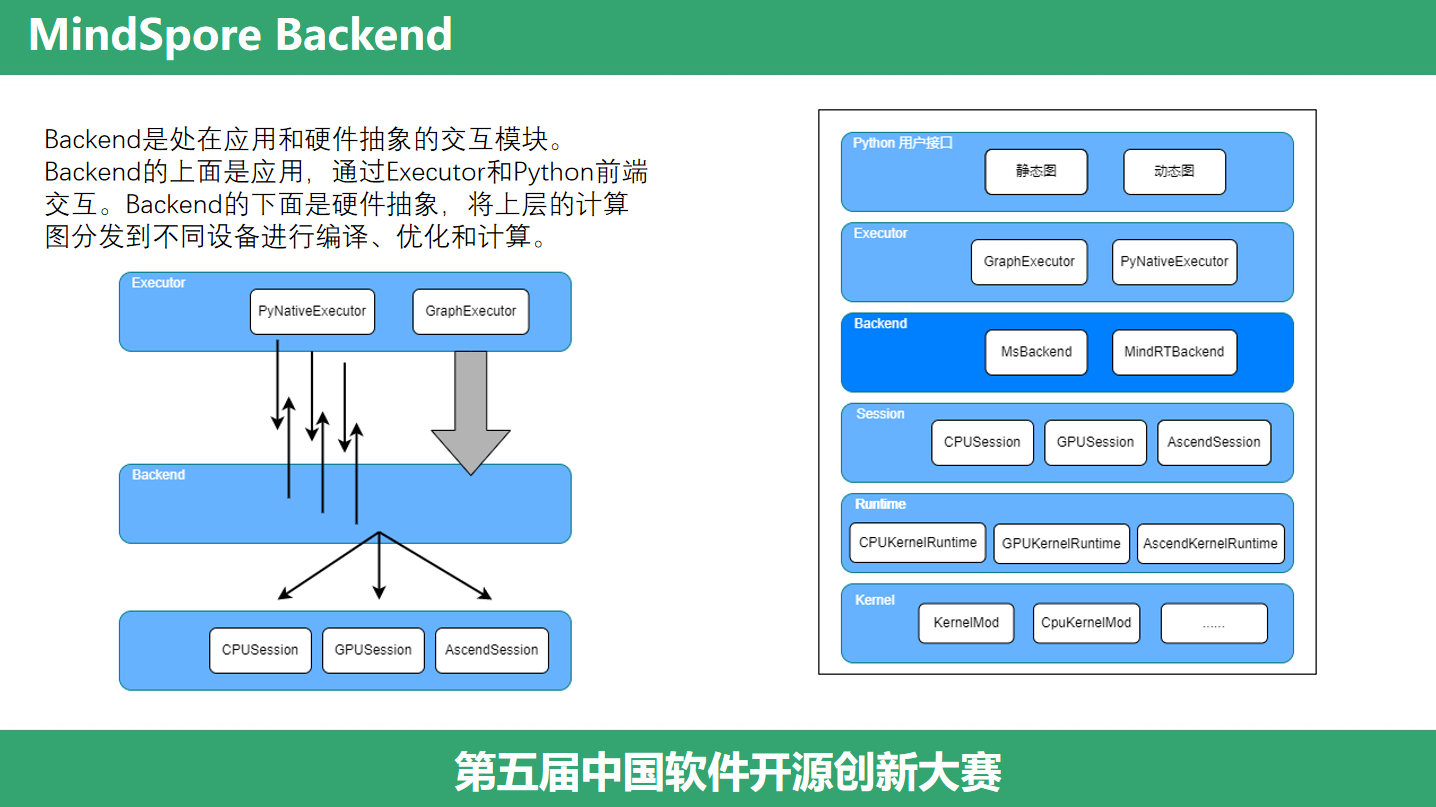
(Backend)那么 Executor 下层的 Backend 做了什么事情呢?Backend是处在应用和硬件抽象的交互模块。Backend的上面是应用,通过Executor和Python前端交互。Backend的下面是硬件抽象,将上层的计算图分发到不同设备进行编译、优化和计算。
Session 和 Runtime
(Session和Runtime)Backend向下是硬件抽象,为了支持扩展多种计算设备,MindSpore对计算设备进行了抽象,提供了多个Session以及配套的Runtime。这几年国产芯片的不断涌现,通过对硬件设备进行抽象,我们可以很方便的将新的国产芯片,新的计算设备接入系统。它做了哪些抽象呢?一个是Session,它是神经网络计算图的核心模块,它主要工作是计算图编译、优化、执行。另一个是Runtime,它负责管理计算设备,主要工作有设备初始化和释放、计算流、管理内存空间、设备通信等。

Kernel
(Kernel)Runtime 向下提供了关于计算的抽象,即算子开发人员关心的 Kernel,Kernel 是算子执行体。在 Runtime 执行的时候会依次调用 KernelMod 中若干接口:初始化、启动算子等等。算子开发人员仅需要关注并扩展这些接口即可。比如算子计算的接口,就是一个 Launch,提供输入、输出、一个临时的工作区即可。后面我们将结合一个具体的例子ReduceSum来分析,一个算子怎么写,怎么优化。

ReduceSum 功能
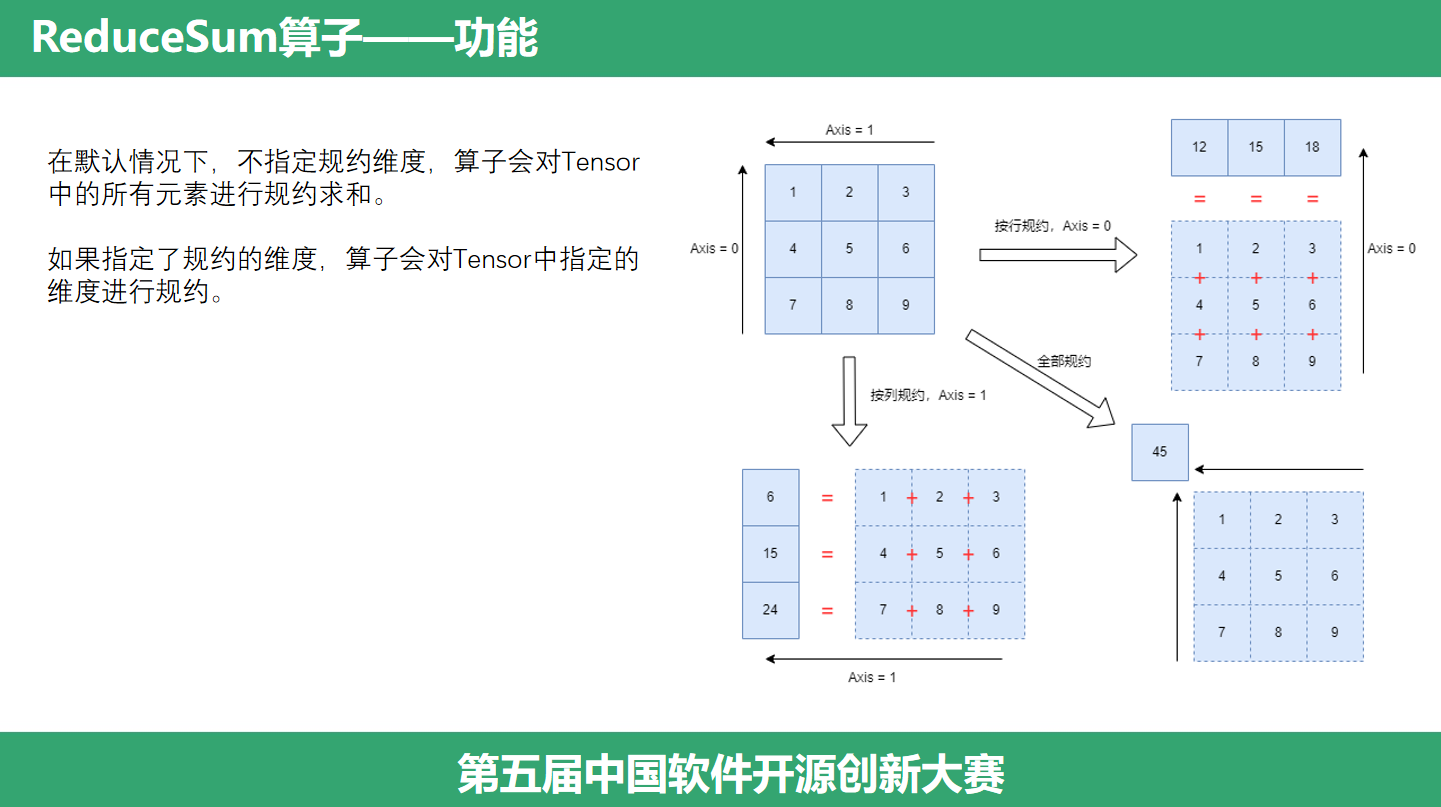
(ReduceSum功能)前面提到,ReduceSum 的作用是对向量求和,并且可以指定维度进行求和。在默认情况下,不指定规约维度,算子会对Tensor中的所有元素进行规约求和,这里会将这个二维矩阵中的每个元素加起来。而如果指定了规约的维度,算子会对Tensor中指定的维度进行规约,比如按行规约,那么会将每一行的元素加起来,或者按列规约,将每列的元素加起来。
算子执行流程
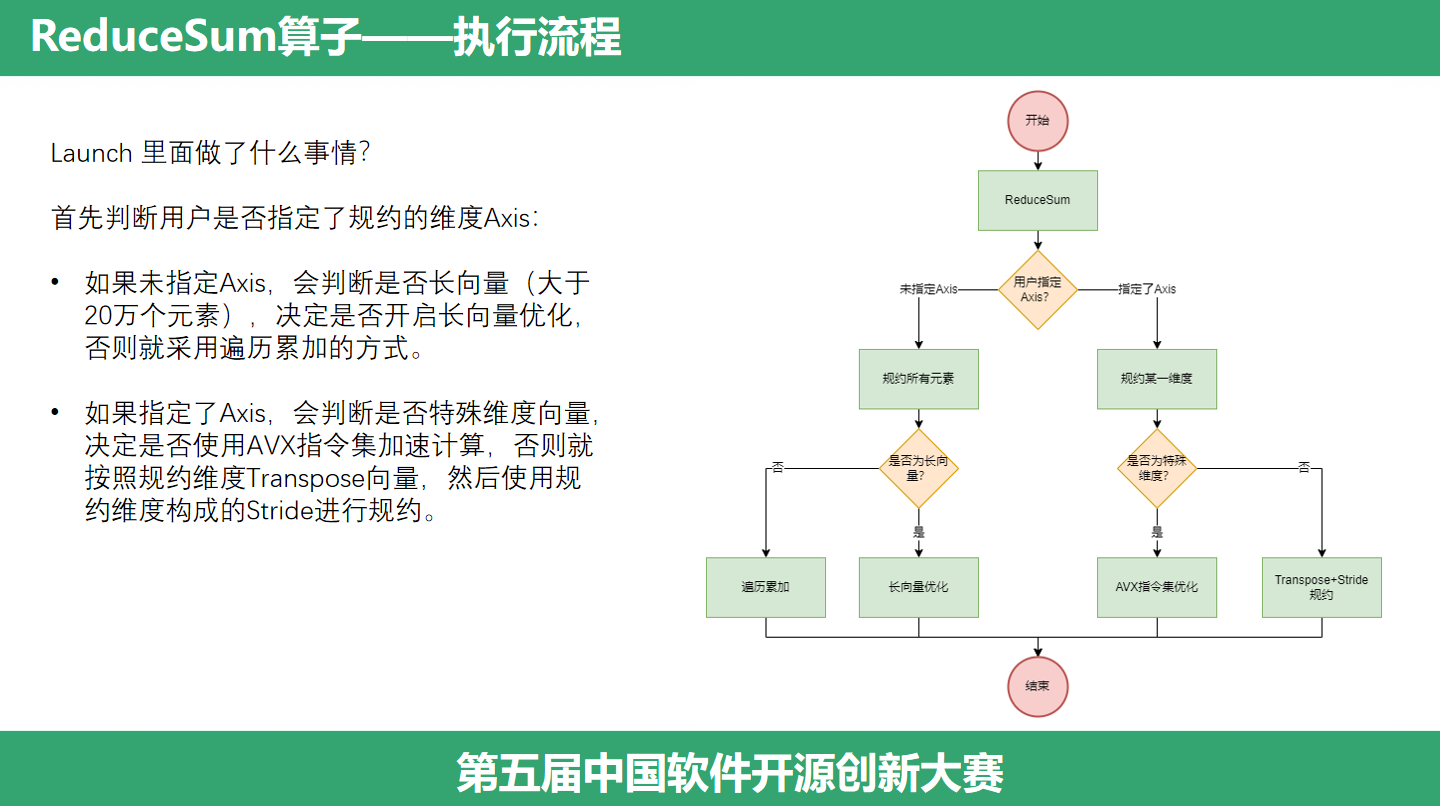
(ReduceSum执行流程)那么这个算子是怎么实现的呢?Launch 里面做了什么事情呢?首先判断用户是否指定了规约的维度Axis,分成两种情况:未指定Axis和指定了Axis。第一种情况,如果未指定Axis,会判断是否长向量,决定是否开启长向量优化,否则就采用遍历累加的方式,也就是拿到一个指针,然后逐个逐个元素取出来,加起来。如果指定了Axis,会判断是否特殊维度向量,决定是否使用AVX指令集加速计算,否则就按照规约维度Transpose向量,然后使用规约维度构成的Stride进行规约。
算子优化
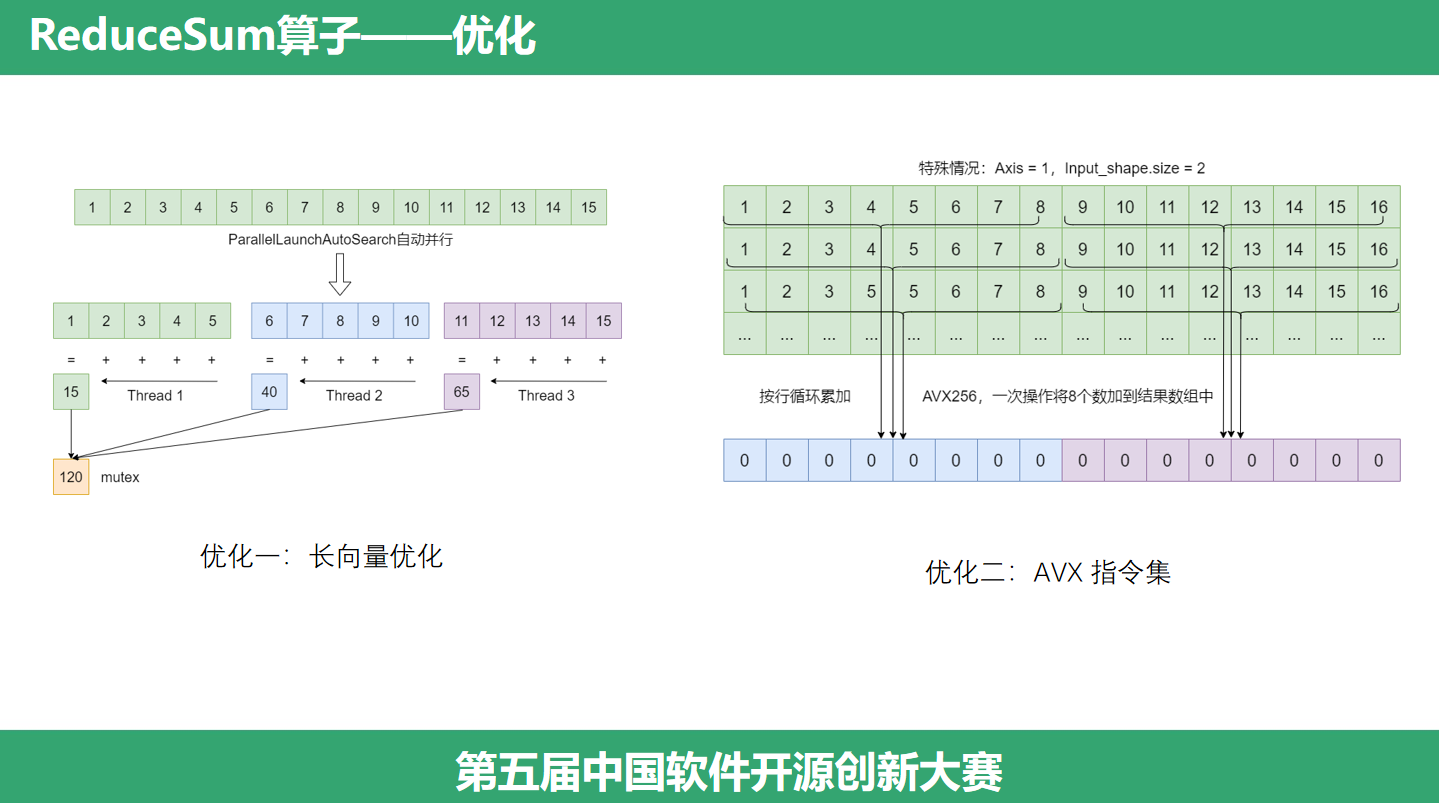
(ReduceSum优化)接下来,我们来具体看看这两个分支的优化技巧。第一个优化技巧是长向量优化,针对大于20万元素的情况,我们会将这个向量切分成多份,利用并行计算技术计算每一份规约的结果,每一份规约的结果算出来之后,我们还要汇总这个结果,将它放到目的地址,因为使用了多线程,所以还需要使用锁来避免访问冲突。第二个优化技巧是使用AVX指令集,它是针对特殊情况的,针对一个二维矩阵,并且是按列规约的情况。AVX 指令集是一个 SIMD 指令集,一条指令,多条数据同时操作,在这里我们可以同时按行,每次取出8个元素,累加到结果数组中。至此,这个算子的实现和优化也讲完了。
总结
(总结)总结一下,我们的这次分享,自顶向下分析了一个算子在MindSpore中的执行流程,从Python用户接口到底层的Kernel执行。其次,我们结合了一个具体的ReduceSum算子,分析了计算流程,提炼优化技巧。最后,本次参赛,我们通过阅读代码,写代码评注,让更多人可以看到中间层做了什么,打开了黑盒子,给开发者更多的确定性和安全感。对算子接口执行流程更加清晰,为进一步优化算子性能提供了可行的思路。
(致谢)最后,谢谢各位的聆听,谢谢!恳请各位老师批评指正。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号