DeepRec 做了哪些优化?
前言
这段时间参加了天池上的 “DeepRec CTR模型性能优化” 比赛,通过阅读 DeepRec 官方文档,可以了解 DeepRec 做了哪些优化,哪些优化可以迁移借鉴,哪些优化是针对推荐系统的。这篇文章是对 DeepRec 文档的提炼总结,不涉及代码。
图优化
DeepRec 提供的图优化可以分成两类,一类是通过 “重叠通信、访存、计算” 来提高性能,一类是通过算子融合来减少调度和访存的开销。
Auto Micro Batch
思路:利用了流水线 pipeline 的思想。在图优化阶段,复制 N 个子图出来,重叠通信、访存、计算以提升性能,多个子图计算的 micro batch 对梯度进行累加之后再更新。 如下图,原本 4 个 micro batch 需要依次完成,利用流水线就可以并行执行。
效果:单机实验数据显示,在达到相同效果的前提下,2 pipeline 吞吐提升 30%,4 pipeline 吞吐提升 17%。

Embedding Fusion 算子
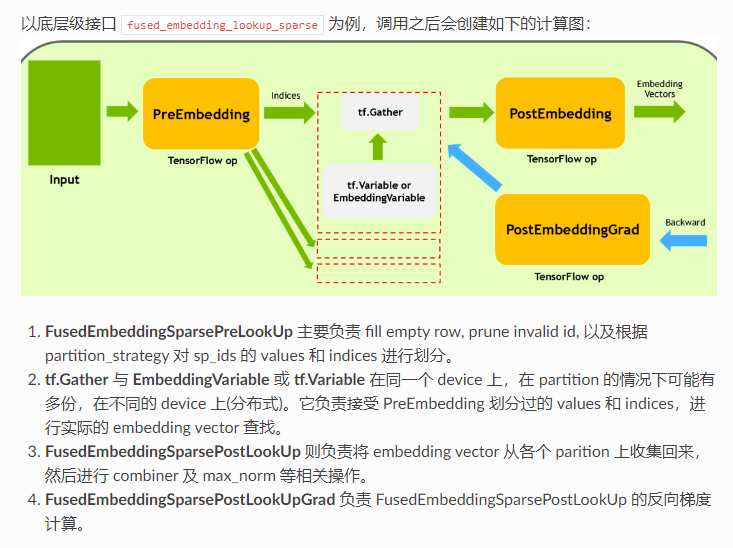
动机:“DeepRec 及 TensorFlow 原生的 embedding lookup 相关 API,如 safe_embedding_lookup_sparse,会创建比较多的 op,因此在 GPU 上执行时容易出现 kernel launch bound 的问题。” 另外,小 op 太多会增加调度的时间。
解决方法:提供 embedding fusion ops。在用户端的 embedding_column 提供一个 do_fusion 参数,判断是否要使用融合算子 fused_embedding_lookup_sparse。如果使用这个算子,那么就会像下图这样产生几个 op,分别进行前处理,收集数据,后处理,反向传播。
Stage 流水线 && Smart 自动流水线
动机:一个训练任务由数据读取和计算两部分组成,数据读取属于 IO bound 操作,不能很好利用资源,从而拖慢训练。
解决办法:DeepRec 提供数据 prefetch 功能,提供 staged 接口,使数据读取和计算异步执行。SmartStage 可以自动化的寻找最大可以 stage 的范围,减少用户显式操作,并且可以将寻找更小粒度的算子来异步执行。
效果:CPU 下 DLRM 每秒训练 steps 可以提升 212 步,GPU 场景需要使用专门针对 GPU 优化的选项,否则性能会降低。
Embedding Lookup 异步化
动机:在分布式训练的场景下,模型的特征增多,worker 在 ps 节点进行大量的 Embedding Lookup 操作,在整个端到端的耗时不断增长,成为模型训练速度的瓶颈,导致不能高效地利用计算资源。
解决办法:将 Embedding Lookup 部分子图划分出来,与计算主图异步执行,实现通信和计算重叠。使用需要开启 Stage,并且有一个 IO Stage,但是和 SmartStage 不能同时开启。
正面影响:在分布式场景下,通过通信和计算重叠,提高训练速度。
负面影响:可能影响收敛速度和模型精度。因为 Embedding Lookup 和梯度反向传播更新参数是异步执行的,所以可能不能获取到最新的参数。收敛速度如果减慢了,那么即使是训练吞吐量上去了,整体效果还是降低的。
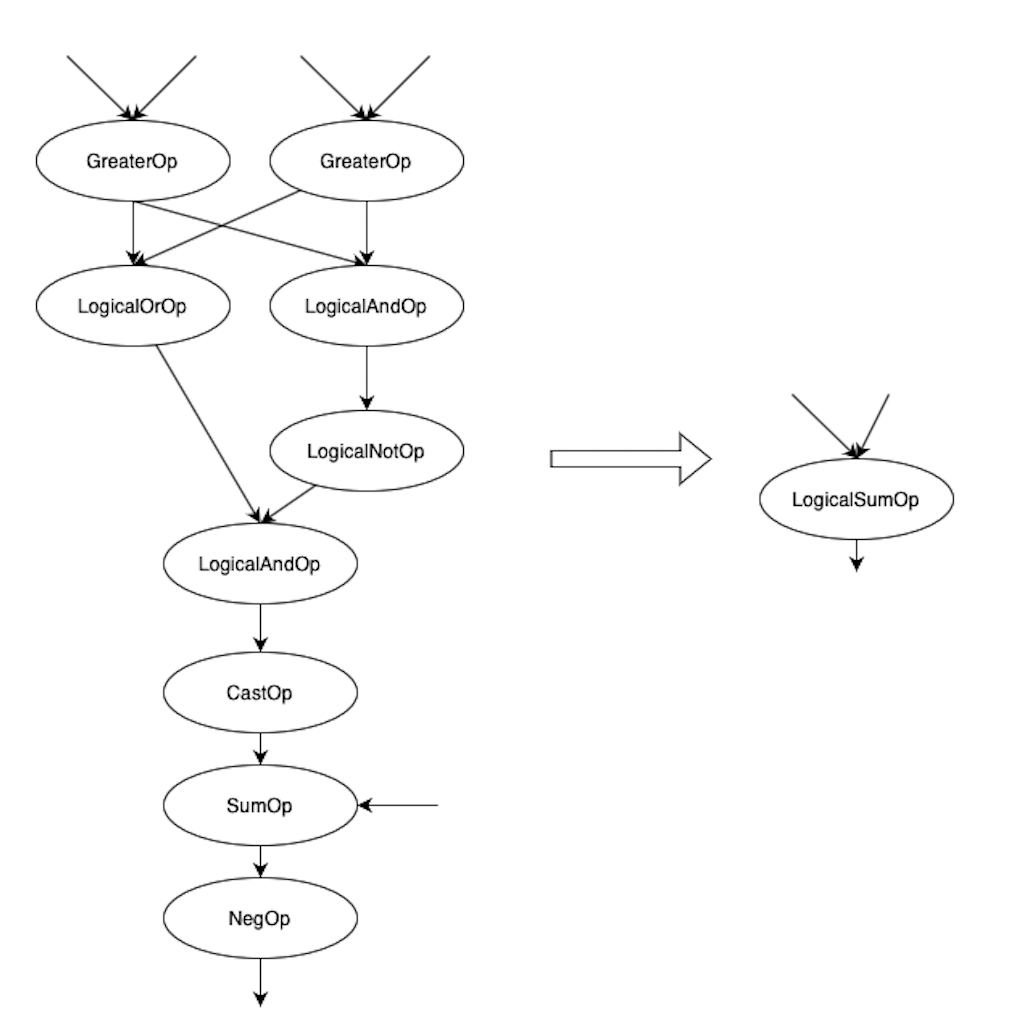
Auto Graph Fusion 算子融合
问题:“大量小 Op 执行中调度开销占比高,导致整个图执行效率低”
思路:自动匹配计算子图,使用一个 Macro Op 替换计算子图,使用更大粒度的 Op 好处是减少调度和访存的开销。
文档中的例子:
Runtime 优化
DeepRec 提供的 Runtime 优化主要是内存/显存优化,调度优化。
CPU Memory Optimization
动机:“在 CPU 端,高性能 malloc 库存在大内存分配时带来的 minor page fault 严重导致的性能问题”
补充:page fault 有几个类型,major,minor,invalid。major page fault,指访问的内存不在虚拟空间里面,也不在物理空间,需要从慢速设备载入。minor page fault,指访问的内存不在虚拟空间里面,但在物理空间,只需要建立 MMU 物理内存和虚拟内存的映射,当调用 malloc 获取虚拟空间地址后,首次访问该地址会发生一次 soft page fault,或者进程访问共享内存中的数据,但是还没有建立映射。invalid page fault,访问的地址不在合理的范围内。
解决办法:收集内存分配信息,指定内存分配策略。提供两个参数,一个参数为收集内存信息的步数,一个参数为策略稳定运行达到的步数。
GPU Memory Optimization
动机:“在 GPU 端,TensorFlow 原生 BFCAllocator 存在显存碎片过多的问题,导致显存浪费。”
解决办法:“该功能在开始运行的前 K 个 step 收集运行信息并使用 cudaMalloc 分配显存,所以会造成性能下降,在收集信息结束后,开启优化,这时的性能会有所提升。”
影响:推荐模型 DBMTL-MMOE 的性能会微小下降 1%,显存占用大大减少 23%
GPU 虚拟显存
动机:显存不足的问题。
解决办法:“在显存不足时使用 cuda 的统一内存地址的 cuMemAllocManaged API 来分配显存,可以使用 CPU 内存来增加显存使用”
影响:可以用利用 CPU 内存,但是性能下降。
Executor 优化
思路:调度优化,优化 TensorFlow 原生的 executor 策略。DeepRec 提供了两种策略。第一,Inline Executor。支持 Session Run 在同一个线程上执行,减少线程切换,减少框架的 overhead,适用于 serving 高并发场景下以及部分 PS 场景。第二,基于 CostModel 的 Executor。统计与计算多组指标,通过 CostModel 计算出一个较优的调度策略。该功能中包含了基于关键路径的调度策略和根据 CostModel 批量执行耗时短的算子的调度策略。
影响:个人实测,在训练场景下,后两种策略都会变慢。Inline Executor 变慢是因为场景不适用。基于 CostModel 的 Executor 变慢的原因不详。
算子优化
DeepRec 中算子优化主要是:一,老老实实优化,这对开发人员的能力要求高,而且存在重复劳动的可能;二,对接硬件厂商的高性能计算库,比如 oneDNN,cudnn 等;三,充分利用新硬件及新特性,比如 PMEM 和 NVIDIA TF32。
对接 oneDNN
方案:oneDNN 是 Intel 提供的深度学习性能加速库,在图优化阶段,可以将自己实现的算子,替换成 oneDNN 内支持的原语,从而将 oneDNN 的算子用起来。oneDNN 可以充分利用 CPU 提供的指令集加速算子计算,比如 AVX512。
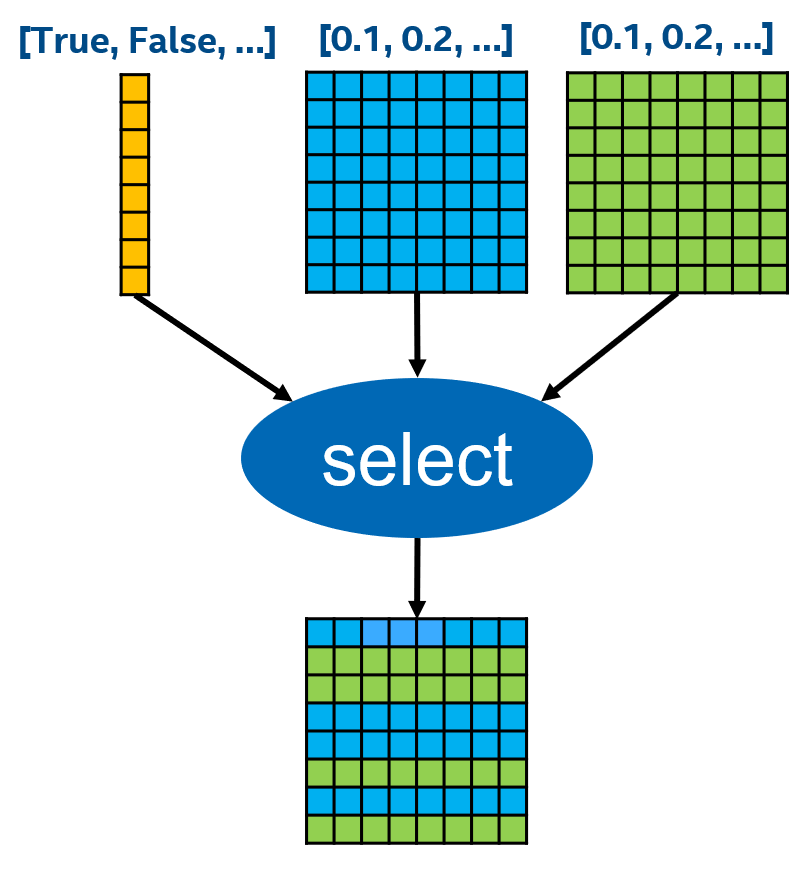
算子优化
例子:DeepRec 文档中给出了一个具体的算子优化实例。Select 算子在 TensorFlow 中默认的实现是使用 Eigen 库提供的原语拼出来,Broadcast + ElementWise Select。DeepRec 的优化是,直接在数据上操作,既然是 Select,那么直接 Row Select 即可,并且可以利用 AVX 512 指令来优化。
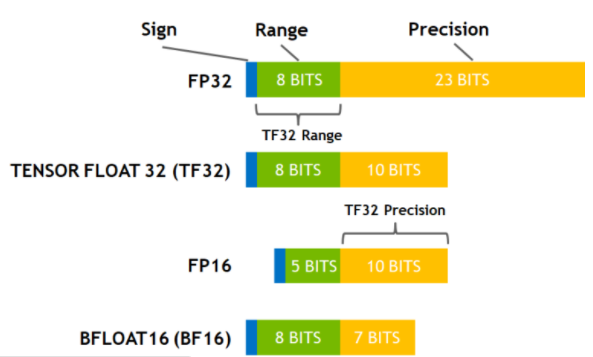
NVIDIA TensorFloat-32
方案:“TensorFloat-32,是 Nvidia 在 Ampere 架构的 GPU 上推出的专门运用于 TensorCore 的一种计算格式。” “请注意,TF32 仅仅是在使用 TensorCore 时的一种中间计算格式,它并不是一个完全的数据类型。”
影响:使用 TF32 可以大大提升速度,但是对精度基本无影响。
持久内存
简介:持久内存在内存层级中位于内存和存储器之间,速度比内存慢,容量比内存大;速度比存储器快,容量比存储器小。内存访问延迟是几十纳秒,PMEM 是几百纳秒,SSD 是几十微秒,HDD 是几毫秒。
使用方法:
- 内存模式。将 PMEM 放在内存和存储器中间,作为存储器的缓存,对程序完全透明。
- 应用直接访问模式,存在两种用法。将 PMEM 配置为块设备,当存储器使用;将 PMEM 当内存使用,可视为一个 NUMA 节点。
DeepRec 中的用处:Embedding 表通常是非常大的,Embedding 可以简单理解为用户-特征矩阵,用户很多,算法人员不断扩展新特征,这样 Embedding 会随着时间不断变大,直到放不进内存,内存容量成为了瓶颈。所以引入 PMEM,可以提高大规模分布式训练的内存存储能力,降低总体拥有成本 TCO(Total Cost of Ownership)。
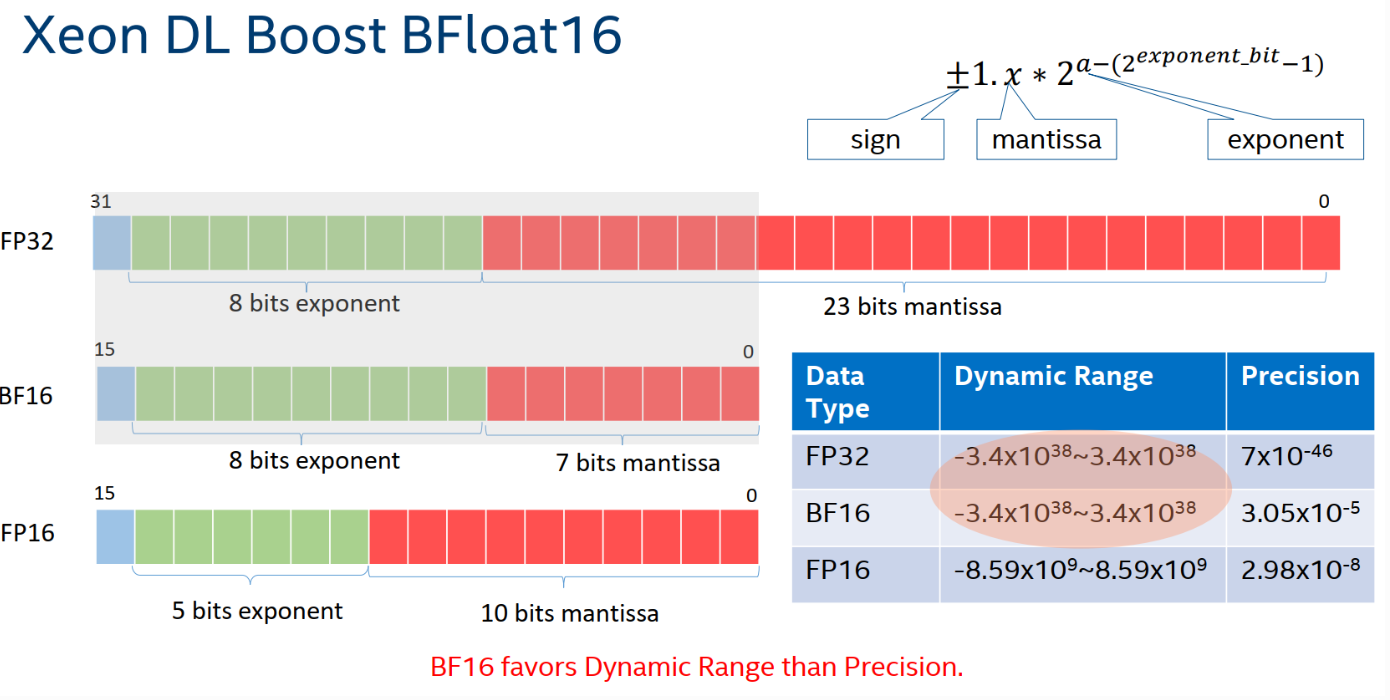
BFloat16
方案:Intel 处理器 Cooper Lake 架构支持 BFloat16(BF16),可以使用低精度来进行推理。使用方法是,将输入数据从 float32 转为 BFloat16,模型参数会在算子调用的时候,自动被转为 BFloat16,并且缓存在算子中。“为了减小这部分开销,DeepRec 会自动将 cast 算子和就近的算子进行融合,提高运行速度。” 比如将矩阵乘法 Matmul 和 Cast 融合。
影响:对 AUC 影响小,WDL 速度可以提升达到 1.42 倍。
(正在更新中......)
其他优化
稀疏功能
分布式训练
GRPC++
问题:TensorFlow 使用 GRPC 作为通信协议,在大规模训练场景下,通信和数据拷贝有额外的开销。
解决:DeepRec 在通信上做了若干优化:“Sharing Nothing 架构、BusyPolling 机制、用户态零拷贝、Send/Recv 融合等多种优化实现。”
StarServer
问题:“在超大规模任务场景下(几百甚至上千 worker),原生 tensorflow 框架中的一些问题被暴露出来,譬如低效的线程池调度,多处关键路径上的锁开销,低效的执行引擎,频繁的 rpc 带来的开销以及内存使用效率低等等。”
解决:第一,通信使用新的模型,将 send/recv 修改为 pull/push,支持子图划分;第二,图执行过程 lock free,提高并发执行子图的效率。
SOK
SparseOperationKit 是支持稀疏训练和推理的工具集,适用于大规模推荐系统,可以将推荐系统的 Embedding 切分到多个 GPU 上,即支持模型并行。SOK 还可以和常见的数据并行框架一同工作,比如 Horovod。因此可以通过 SOK 和 Horovod 实现混合并行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号