数据处理
这些天做目标检测,模型用到yolov3,做关于阿里天池街景字符检测,关于数据处理这一块遇到了些问题,比如从json,xml这些标签文件里如何提取需要的信息,归纳到指定文件夹并对python里的文件操作很生疏,就这几天的两个项目做一个总结。
1.数据集
/data目录下

/data/mchar_train/

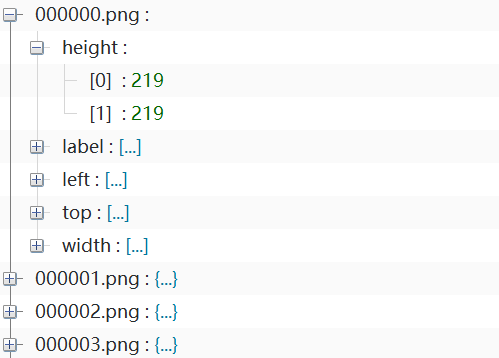
目录如下,我的目的是把标签取出来,重新创建/data/lanels/目录,并在labels目录下创建/data/lanels/train和/data/lanels/val,
打开json文件,/data/mchar_train.json目录如下:
2.程序操作
1 import os 2 import cv2 3 import json 4 #图片的目录 5 train_image_path = '/data/mchar_train/' 6 val_image_path = '/data/mchar_val/' 7 #json的目录 8 train_annotation_path = '/data/mchar_train.json' 9 val_annotation_path = '/data/mchar_val.json' 10 #读取json文件 11 train_data = json.load(open(train_annotation_path)) 12 val_data = json.load(open(val_annotation_path)) 13 #存储train的目标目录 14 label_path = '/data/labels/train/' 15 #遍历图片 16 for key in train_data: 17 f = open(label_path+key.replace('.png', '.txt'), 'w') 18 #读取图片拿到宽和高,为了归一化,符合yolo格式xywh 19 img = cv2.imread(train_image_path+key) 20 shape = img.shape 21 #取标签 22 label = train_data[key]['label'] 23 left = train_data[key]['left'] 24 top = train_data[key]['top'] 25 height = train_data[key]['height'] 26 width = train_data[key]['width'] 27 #遍历标签,每张图片不止有一个目标 28 for i in range(len(label)): 29 x_center = 1.0 * (left[i]+width[i]/2) / shape[1] 30 y_center = 1.0 * (top[i]+height[i]/2) / shape[0] 31 w = 1.0 * width[i] / shape[1] 32 h = 1.0 * height[i] / shape[0] 33 # label, x_center, y_center, w, h 34 f.write(str(label[i]) + ' ' + str(x_center) + ' ' + str(y_center) + ' ' + str(w) + ' ' + str(h) + '\n') 35 f.close() 36 37 #与上面相同的思路 38 for key in val_data: 39 f = open(label_path+'val_'+key.replace('.png', '.txt'), 'w') 40 img = cv2.imread(val_image_path+key) 41 shape = img.shape 42 label = val_data[key]['label'] 43 left = val_data[key]['left'] 44 top = val_data[key]['top'] 45 height = val_data[key]['height'] 46 width = val_data[key]['width'] 47 for i in range(len(label)): 48 x_center = 1.0 * (left[i]+width[i]/2) / shape[1] 49 y_center = 1.0 * (top[i]+height[i]/2) / shape[0] 50 w = 1.0 * width[i] / shape[1] 51 h = 1.0 * height[i] / shape[0] 52 # label, x_center, y_center, w, h 53 f.write(str(label[i]) + ' ' + str(x_center) + ' ' + str(y_center) + ' ' + str(w) + ' ' + str(h) + '\n') 54 f.close()
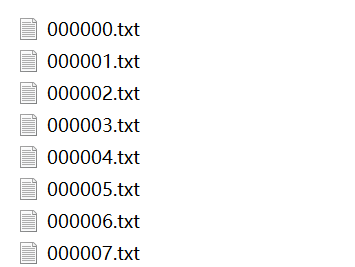
最后得到的目录:
/data/labels/train/

3.第二个数据集
关于口罩检测,也是用于yolo,整理为yolo格式的x y w h,不过这个标签文件并不是json,而是xml。对于xml会用到一个BeautifulSoup库。并且该数据集没有给我们训练集,验证集和测试集,它只给了一个整合,故需要我们自己划分按照7:2:1划分训练集,验证集测试集。
数据集目录:/data/face_mask
/data/face_mask/JPEGImages

/data/face_mask/Annotations

我的目的是把xml文件里的bndbox取出来
4.程序
import os import shutil import glob import cv2 from tqdm import tqdm from bs4 import BeautifulSoup import pandas as pd # 所有xml文件 label_path = '/face_mask/Annotations/*.xml' face_list = glob.glob(label_path) train_image_path = '/face_msk/JPEGImages/' #定义一个处理xml的函数 def process_xml(file_list, img_path): total_label = [] for file in file_list: #将文件名改为txt file_name = file.split('\\')[-1].split('.')[0] + '.txt' #将文件改为 img_name = file.split('\\')[-1].split('.')[0] + '.jpg' img = cv2.imread(img_path + img_name) shape = img.shape label_list = [] #打开每个xml文件 with open(file, 'r', encoding='utf-8') as f: data = f.read() #用BeautifulSoup库处理xml soup = BeautifulSoup(data, 'html.parser') objects = soup.find_all('object') for obj in objects: name = obj.find('name').text xmin = int(obj.find('xmin').text) ymin = int(obj.find('ymin').text) xmax = int(obj.find('xmax').text) ymax = int(obj.find('ymax').text) # 转成yolo代码里的bbox格式 x_center = ((xmin + xmax)/2)/shape[1] y_center = ((ymin + ymax)/2)/shape[0] w = (xmax - xmin)/shape[1] h = (ymax - ymin)/shape[0] # 给分类标号 if name == 'face': c_id = 0 elif name == 'face_mask': c_id = 1 else: c_id = 2 label = c_id, x_center, y_center, w, h label_txt = ' '.join(list(map(str, label))) label_list.append(label_txt) label_dict = {'file_name':file_name, 'label': label_list} total_label.append(label_dict) return total_label
然后通过用这个函数对整个图像数据处理,再用pandas划分数据集,分别写入./face_mask/labels/train和./face_mask/labels/val和./face_mask/labels/test
即,
至此标签处理完毕
然后就是图片,由于划分的数据集标签要和图片对应,也要把图片移动到相应的目录里,即./face_mask/image/train/和./face_mask/image/val/和./face_mask/image/test/
程序如下:
#其中source为图片原始的位置,target为要移动的目标位置,txt_path为标签目录
def move_img(source_path, target_path, txt_path): txt_path = txt_path + '/' + '*.txt' txt_list = glob.glob(txt_path) for t in tqdm(txt_list): img_name = t.split('\\')[-1].split('.')[0] + '.jpg' src = source_path + img_name dst = target_path + '/' + img_name shutil.copyfile(src, dst)
分别执行三个这样的函数就把图片移动到相应得文件目录下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号