
DS博客作业04--图
0.PTA得分截图
1.本周学习总结
1.1 总结图内容
图存储结构
图是由顶点集(图中的所有顶点)和边集(图中的所有边)组成的数据结构,图分为有向图和无向图,有向图中的边是有方向的边,而无向图中的边是没有方向的边。
在无向图中若存在一条边(i,j),则称i,j互为邻接点
在有向图中若存在一条边<i,j>,则该条边是顶点i的一条出边,是顶点j的一条出边,也称i,j互为邻接点
在无向图中,与顶点i所有有连接的边的边数称之为顶点i的度
在有向图中,以顶点i为终点的边的边数称之为入度,以顶点i为出发点的边的边数称之为出度,入度与出度之和称之为顶点i的度
完全无向图是指每两个顶点之间都存在一条边,包含有n(n-1)/2条边(n为顶点数)
完全有向图是指每两个顶点之间都存在方向相反的两条边,包含有n(n-1)条边(n为顶点数)
当一个图的边数接近完全图的边数时,我们称之为稠密图,而当边数远小于完全图的边数时,我们称之为稀疏图
路径长度是指一条路径上所经过的边的数目
简单路径是指一条路径上除出发点和结束点之外的其他顶点均不相同的路径
回路或者叫做环,是指一条路径上开始点和结束点为同一个顶点
简单回路或者叫做简单环,是指开始点和结束点相同的简单路径
若从顶点i到顶点j有路径,则称顶点i和j是连通的
连通图是指若图中任意两个顶点都连通,否则称为非连通图
连通分量:无向图G中的极大连通子图
任何连通图的连通分量只有一个,即本身;而非连通图有多个连通分量
对有向图来说,若任意两个顶点之间都存在一条有向路径,则称此有向图为强连通图
否则,其各个强连通子图称作它的强连通分量
在一个非强连通中找强连通分量的方法:
1.在图中找有向环。
2.扩展该有向环:如果某个顶点到该环中任一顶点有路径,并且该环中任一顶点到这个顶点也有路径,则加入这个顶点
图中每一条边都可以附有一个对应的数值,这种与边相关的数值称为权。
边上带有权的图称为带权图,也称作网。
图的两种主要存储结构:
- 邻接矩阵
- 邻接表
邻接矩阵逻辑结构分为两部分:V和E集合,其中,V是顶点,E是边。因此,用一个一维数组存放图中所有顶点数据;用一个二维数组存放顶点间关系(边或弧)的数据,这个二维数组称为邻接矩阵。邻接矩阵又分为有向图邻接矩阵和无向图邻接矩阵
邻接矩阵的特点:
1.无向图的邻接矩阵一定是对称的,而有向图的邻接矩阵不一定对称。因此,用邻接矩阵来表示一个具有n个顶点的有向图时需要n^2个单元来存储邻接矩阵;对有n个顶点的无向图则只存入上(下)三角阵中剔除了左上右下对角线上的0元素后剩余的元素,故只需1+2+...+(n-1)=n(n-1)/2个单元。
2.无向图邻接矩阵的第i行(或第i列)非零元素的个数正好是第i个顶点的度。
3.有向图邻接矩阵中第i行非零元素的个数为第i个顶点的出度,第i列非零元素的个数为第i个顶点的入度,第i个顶点的度为第i行与第i列非零元素个数之和。
4.用邻接矩阵表示图,很容易确定图中任意两个顶点是否有边相连。
邻接表,存储方法跟树的孩子链表示法相类似,是一种顺序分配和链式分配相结合的存储结构。如这个表头结点所对应的顶点存在相邻顶点,则把相邻顶点依次存放于表头结点所指向的单向链表中。对于无向图来说,使用邻接表进行存储也会出现数据冗余,表头结点A所指链表中存在一个指向C的表结点的同时,表头结点C所指链表也会存在一个指向A的表结点
邻接表存储图的实现方式是,给图中的各个顶点独自建立一个链表,用节点存储该顶点,用链表中其他节点存储各自的临界点。
与此同时,为了便于管理这些链表,通常会将所有链表的头节点存储到数组中(也可以用链表存储)。也正因为各个链表的头节点存储的是各个顶点,因此各链表在存储临界点数据时,仅需存储该邻接顶点位于数组中的位置下标即可。
图遍历及应用
图的遍历:从给定图中任意指定的顶点(称为初始点)出发,按照某种搜索方法沿着图的边访问图中的所有顶点,使每个顶点仅被访问一次
图最普遍使用的遍历有深度优先遍历(DFS)和广度优先遍历(BFS)
事实上,深度优先搜索属于图算法的一种,英文缩写为DFS即Depth First Search.其过程简要来说是对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次
深度优先遍历图的方法是,从图中某顶点v出发:
(1)访问顶点v;
(2)依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;
(3)若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。
宽度优先搜索算法(又称广度优先搜索)是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。Dijkstra单源最短路径算法和Prim最小生成树算法都采用了和宽度优先搜索类似的思想。其别名又叫BFS,属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。换句话说,它并不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为止。
广度优先搜索遍历的过程是:
(1)访问初始点v,接着访问v的所有未被访问过的邻接点
(2)按照次序访问每一个顶点的所有未被访问过的邻接点
(3)依次类推,直到图中所有顶点都被访问过为止
判断图是否联通的方法如下:
- 初始化visited数组,然后执行一次DFS或者BFS
- 之后检查visited数组,若所有顶点均访问过,则连通,否则不连通
查找路径可以用DFS:
设x是当前被访问顶点,在对x做过访问标记后,选择一条从x出发的未检测过的边(x,y)。若发现顶点y已访问过,则重新选择另一条从x出发的未检测过的边,否则沿边(x,y)到达未曾访问过的y,对y访问并将其标记为已访问过;然后从y开始搜索,直到搜索完从y出发的所有路径,即访问完所有从y出发可达的顶点之后,才回溯到顶点x,并且再选择一条从x出发的未检测过的边。上述过程直至从x出发的所有边都已检测过为止。此时,若x不是源点,则回溯到在x之前被访问过的顶点;否则图中所有和源点有路径相通的顶点(即从源点可达的所有顶点)都已被访问过,若图G是连通图,则遍历过程结束,否则继续选择一个尚未被访问的顶点作为新源点,进行新的搜索过程。
查找最短路径可以用BFS:
- 从顶点u出发一层一层地向外扩展
- 利用队列记录访问的顺序
- 当第一次找到顶点v时队列中便包含了最短路径,同时在搜索过程中利用队列存储最短路径(这是一个普通队列,而非之前所说的环形队列)
- 然后再利用队列输出最短路径(逆路径)
最小生成树相关算法及应用
最小生成树是指:
- 对于带权连通图G ,n个顶点,n-1条边
- 根据深度遍历或广度遍历生成生成树,树不唯一
- 其中权值之和最小的生成树称为图的最小生成树
求最小生成树主要有两种方法:Prim算法和Kruskal算法
普里姆算法(Prim算法),图论中的一种算法,可在加权连通图里搜索最小生成树。意即由此算法搜索到的边子集所构成的树中,不但包括了连通图里的所有顶点(英语:Vertex (graph theory)),且其所有边的权值之和亦为最小。该算法于1930年由捷克数学家沃伊捷赫·亚尔尼克(英语:Vojtěch Jarník)发现;并在1957年由美国计算机科学家罗伯特·普里姆(英语:Robert C. Prim)独立发现;1959年,艾兹格·迪科斯彻再次发现了该算法。因此,在某些场合,普里姆算法又被称为DJP算法、亚尔尼克算法或普里姆-亚尔尼克算法。
具体算法步骤如下:
1).输入:一个加权连通图,其中顶点集合为V,边集合为E;
2).初始化:Vnew = {x},其中x为集合V中的任一节点(起始点),Enew = {},为空;
3).重复下列操作,直到Vnew = V:
a.在集合E中选取权值最小的边<u, v>,其中u为集合Vnew中的元素,而v不在Vnew集合当中,并且v∈V(如果存在有多条满足前述条件即具有相同权值的边,则可任意选取其中之一);
b.将v加入集合Vnew中,将<u, v>边加入集合Enew中;
4).输出:使用集合Vnew和Enew来描述所得到的最小生成树。
Prim算法需要借助:
1.closest[i]:最小生成树的边依附在U中顶点编号。
2.lowcost[i]表示顶点i(i ∈ V-U)到U中顶点的边权重,取最小权重的顶点k加入U。并规定lowcost[k]=0表示这个顶点在U中
Kruskal算法是一种用来查找最小生成树的算法,由Joseph Kruskal在1956年发表。用来解决同样问题的还有Prim算法和Boruvka算法等。三种算法都是贪心算法的应用。和Boruvka算法不同的地方是,Kruskal算法在图中存在相同权值的边时也有效。
基本思想:先构造一个只含 n 个顶点、而边集为空的子图,把子图中各个顶点看成各棵树上的根结点,之后,从网的边集 E 中选取一条权值最小的边,若该条边的两个顶点分属不同的树,则将其加入子图,即把两棵树合成一棵树,反之,若该条边的两个顶点已落在同一棵树上,则不可取,而应该取下一条权值最小的边再试之。依次类推,直到森林中只有一棵树,也即子图中含有 n-1 条边为止。
步骤:
1.新建图G,G中拥有原图中相同的节点,但没有边;
2.将原图中所有的边按权值从小到大排序;
3.从权值最小的边开始,如果这条边连接的两个节点于图G中不在同一个连通分量中,则添加这条边到图G中;
4.重复3,直至图G中所有的节点都在同一个连通分量中。
Kruskal算法结合快排函数和并查集实现效率更高
两种算法的应用:
假设要在n个城市之间建立通信联络网,则连接n个城市只需要n-1条线路。这时,自然会考虑这样一个问题,如何在节省费用的前提下建立这个通信网?自然在每两个城市之间都可以设置一条线路,而这相应的就要付出较高的经济代价。n个城市之间最多可以设置n(n-1)/2条线路,使用最小生成树算法就可以在线路中选择出一条总的代价最小的路线。
最短路径相关算法及应用
迪杰斯特拉算法(Dijkstra)是由荷兰计算机科学家狄克斯特拉于1959 年提出的,因此又叫狄克斯特拉算法。是从一个顶点到其余各顶点的最短路径算法,解决的是有权图中最短路径问题。迪杰斯特拉算法主要特点是从起始点开始,采用贪心算法的策略,每次遍历到始点距离最近且未访问过的顶点的邻接节点,直到扩展到终点为止。
迪杰斯特拉算法步骤如下:
0.初始化
S={入选顶点集合,初值V0},T={未选顶点集合}。
若存在<V0,Vi>,距离值为<V0,Vi>弧上的权值
若不存在<V0,Vi>,距离值为∞
1.从T中选取一个其距离值为最小的顶点W, 加入S
2.S中加入顶点w后,对T中顶点的距离值进行修改:
若加进W作中间顶点,从V0到Vj的距离值比不加W的路径要短,则修改此距离值;
3.重复上述步骤1,直到S中包含所有顶点,即S=V为止
迪杰斯特拉算法使用dist数组存放最短路径长度,使用path来存放路径,使用s数组来标记选中的顶点
Floyd算法又称为插点法,是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法,与Dijkstra算法类似。该算法名称以创始人之一、1978年图灵奖获得者、斯坦福大学计算机科学系教授罗伯特·弗洛伊德命名。
在计算机科学中,Floyd算法是一种在具有正或负边缘权重(但没有负周期)的加权图中找到最短路径的算法。算法的单个执行将找到所有顶点对之间的最短路径的长度(加权)。 虽然它不返回路径本身的细节,但是可以通过对算法的简单修改来重建路径。
Floyd算法步骤如下:
1,从任意一条单边路径开始。所有两点之间的距离是边的权,如果两点之间没有边相连,则权为无穷大。
2,对于每一对顶点 u 和 v,看看是否存在一个顶点 w 使得从 u 到 w 再到 v 比已知的路径更短。如果是更新它。
把图用邻接矩阵G表示出来,如果从Vi到Vj有路可达,则G[i][j]=d,d表示该路的长度;否则G[i][j]=无穷大。定义一个矩阵D用来记录所插入点的信息,D[i][j]表示从Vi到Vj需要经过的点,初始化D[i][j]=j。把各个顶点插入图中,比较插点后的距离与原来的距离,G[i][j] = min( G[i][j], G[i][k]+G[k][j] ),如果G[i][j]的值变小,则D[i][j]=k。在G中包含有两点之间最短道路的信息,而在D中则包含了最短通路径的信息。
时间复杂度:O(n^3)
空间复杂度:O(n^2)
Floyd算法适用于APSP(All Pairs Shortest Paths,多源最短路径),是一种动态规划算法,稠密图效果最佳,边权可正可负。此算法简单有效,由于三重循环结构紧凑,对于稠密图,效率要高于执行|V|次Dijkstra算法,也要高于执行|V|次SPFA算法。
优点:容易理解,可以算出任意两个节点之间的最短距离,代码编写简单。
缺点:时间复杂度比较高,不适合计算大量数据。
拓扑排序、关键路径
在一个有向图中找一个拓扑序列的过程称为拓扑排序。序列必须满足条件:
1.每个顶点出现且只出现一次。
2.若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面
由AOV网构造拓扑序列的拓扑排序算法主要是循环执行以下两步,直到不存在入度为0的顶点为止。
(1) 选择一个入度为0的顶点并输出之;
(2) 从网中删除此顶点及所有出边。
拓扑排序可以用来判断图中是否存在回路:利用循环结束后,若输出的顶点数小于网中的顶点数,则输出“有回路”信息,否则输出的顶点序列就是一种拓扑序列。
关键路径是指设计中从输入到输出经过的延时最长的逻辑路径。优化关键路径是一种提高设计工作速度的有效方法。一般地,从输入到输出的延时取决于信号所经过的延时最大路径,而与其他延时小的路径无关。在优化设计过程中关键路径法可以反复使用,直到不可能减少关键路径延时为止。EDA工具中综合器及设计分析器通常都提供关键路径的信息以便设计者改进设计,提高速度。
求取关键路径的步骤如下:
A、从开始顶点 v1 出发,令 ve(1)=0,按拓扑有序序列求其余各顶点的可能最早发生时间。 [3]
Ve(k)=max{ve(j)+dut(<j,k>)} , j ∈ T 。其中T是以顶点vk为尾的所有弧的头顶点的集合(2 ≤ k ≤ n)。
如果得到的拓朴有序序列中顶点的个数小于网中顶点个数n,则说明网中有环,不能求出关键路径,算法结束。
B、从完成顶点 出发,令 ,按逆拓扑有序求其余各顶点的允许的最晚发生时间:
vl(j)=min{vl(k)-dut(<j,k>)} ,k ∈ S 。其中 S 是以顶点vj是头的所有弧的尾顶点集合(1 ≤ j ≤ n-1)。
C、求每一项活动ai(1 ≤ i ≤ m)的最早开始时间e(i)=ve(j),最晚开始时间l(i)=vl(k)-dut(<j,k>) 。
若某条弧满足 e(i)=l(i) ,则它是关键活动。关键活动连接起来就是关键路径
1.2.谈谈你对图的认识及学习体会
图是一种多对多的数据结构,在实际的生产活动中有着广泛的应用,利用图的遍历可以寻找路径,基于图之上的最小生成树相关算法可以计算出建设道路或者通信网络的最低预算成本,大大降低了人力财力,还有最短路径相关算法,便于规划好出行的路径,用最少的花费和最短的时间去看最多的风景,而关键路径则为生产中的投入提供了重要的方向,从而让资源得到最大利用。总之,图的应用十分广泛,也是最切合实际生活的一种数据结构。
2.阅读代码
2.1 题目及解题代码
题目
题解
class Solution {
public:
//static const int MAXV=10000;
//int G[MAXV][MAXV]={0};
vector<int> gardenNoAdj(int N, vector<vector<int>>& paths) {
vector<int> G[N];
for (int i=0; i<paths.size(); i++){//建立邻接表
G[paths[i][0]-1].push_back(paths[i][1]-1);
G[paths[i][1]-1].push_back(paths[i][0]-1);
}
vector<int> answer(N,0);//初始化全部未染色
for(int i=0; i<N; i++){
set<int> color{1,2,3,4};
for (int j=0; j<G[i].size(); j++){
color.erase(answer[G[i][j]]);//把已染过色的去除
}
answer[i]=*(color.begin());//染色
}
return answer;
}
};
2.1.1 该题的设计思路
设计思路
1、根据paths建立邻接表;
2、默认所有的花园先不染色,即染0;
3、从第一个花园开始走,把与它邻接的花园的颜色从color{1,2,3,4}这个颜色集中删除;
4、删完了所有与它相邻的颜色,就可以把集合中剩下的颜色随机选一个给它了,为了简单,将集合中的第一个颜色赋给当前花园;
5、循环3和4到最后一个花园
- 时间复杂度:O(n²)。染色n个花园且每次染色前需要除去已染色的颜色,两层for循环
- 空间复杂度:O(n)。开辟G数组存储路径,开辟answer数组存储染色方案
2.1.2 该题的伪代码
伪代码
定义vector int型数组G记录路径
定义vector int型数组answer数组记录染色方案
建立邻接表(矩阵形式)
for i=0 to N (染色n次)
for j=0 to G[i].size()
除去已使用的颜色
end for
将answer[i]染色为color数组中的第一种颜色
end for
返回染色方案
2.1.3 运行结果

2.1.4分析该题目解题优势及难点
这个问题就是一种图染色的问题,这次图pta题集中有一题是判断染色方案,而这题需要我们给出染色方案。题解中的邻接表建法与课上所说的不同,题解中是用矩阵的形式来建立邻接表,而课上是以数组结合链表的形式来建立邻接表,这样子以后建立邻接表的方式就多了一种。题解中解题的巧妙之处就在于先把邻接的颜色先从color数组中除去,然后对该花园染色剩下的其中任意一种颜色即可。
2.2 题目及解题代码
题目
题解
class Solution {
public:
int maxDistance(vector<vector<int>>& grid) {
int N = grid.size();
int count_land = 0;
int count_turn = 0;
int count_last_space;
for(int i=0;i<N;i++){
for(int j =0;j<N;j++){
if(grid[i][j]==1){
count_land++;
}
}
}
if(count_land==N*N||count_land==0){
return -1;
}
count_last_space = N*N-count_land;
while(count_last_space!=0){
count_turn++;
for(int i=0;i<N;i++){
for(int j=0;j<N;j++){
if(grid[i][j]==count_turn){
if(i>0&&grid[i-1][j]==0){
grid[i-1][j]=count_turn+1;
count_last_space--;
}
if(i<N-1&&grid[i+1][j]==0){
grid[i+1][j]=count_turn+1;
count_last_space--;
}
if(j>0&&grid[i][j-1]==0){
grid[i][j-1]=count_turn+1;
count_last_space--;
}
if(j<N-1&&grid[i][j+1]==0){
grid[i][j+1]=count_turn+1;
count_last_space--;
}
}
}
}
}
return count_turn;
}
};//题意是对每个海洋区域,计算到每个陆地的距离并取最短的,在这些最短的区域里找最大的那个;只有陆地或海洋的情况单独拿出来看
2.2.1 该题的设计思路
设计思路
如标题所示,将陆地一轮又一轮地扩大,直到覆盖完全,计算扩大了多少轮,输出轮数即可,扩大的地方进行赋值,并根据具体轮数做区分
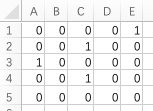
(这是初始状况)
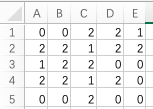
(进行第1轮操作,对值为1的陆地判断它上下左右的四个点,如果值为0就进行“长大”,赋值为2)(同时还记录剩余的为0的点数,直到地图上没有0)
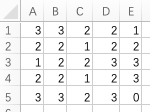
(第2轮操作,对值为2的陆地做“长大”,同上,并赋值为3)
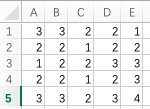
(第3轮操作,地图填满了,结束,跳出)(输出轮数3,就是答案,坐标(4,4)值为4的那个点就是要找的最优海域)
- 时间复杂度:O(n³)。两层for循环计算陆地数量,在每次还有未访问地区时,需遍历一次地图。
- 空间复杂度:O(1)。只需要记录地区数量,扩张轮数和剩余未访问的地区
2.2.2 该题的伪代码
伪代码
定义count_turn记录扩张的轮数
for i=0 to N
for j=0 to N
统计陆地数量
end for
end for
if 都是海洋或者都是陆地 then 返回-1
记录未访问地区的数量
while 还有未访问地区
for i=0 to N
for j=0 to N
遍历四个方向
如果是未访问地区,则赋值为轮数+1同时未访问地区-1
end for
end for
end while
返回扩张轮数
2.2.3 运行结果

2.2.4分析该题目解题优势及难点
本题难点在于受制于多块陆地的存在,要寻找一块距离最远的海洋区域显得很困难。题解先是处理了全是海洋和全是陆地的情况,然后每一轮对已访问的地区进行上下左右的扩张使得未访问地区逐渐减少,当所有的地区均已访问,则扩张的轮数就是距离最远的海洋区域距离所有陆地的最大距离了。题解很巧妙地通过一次次地向上下左右四个方向扩张,将最远距离转化为扩张的轮数,从而使问题简单化。
2.3 题目及解题代码
题目
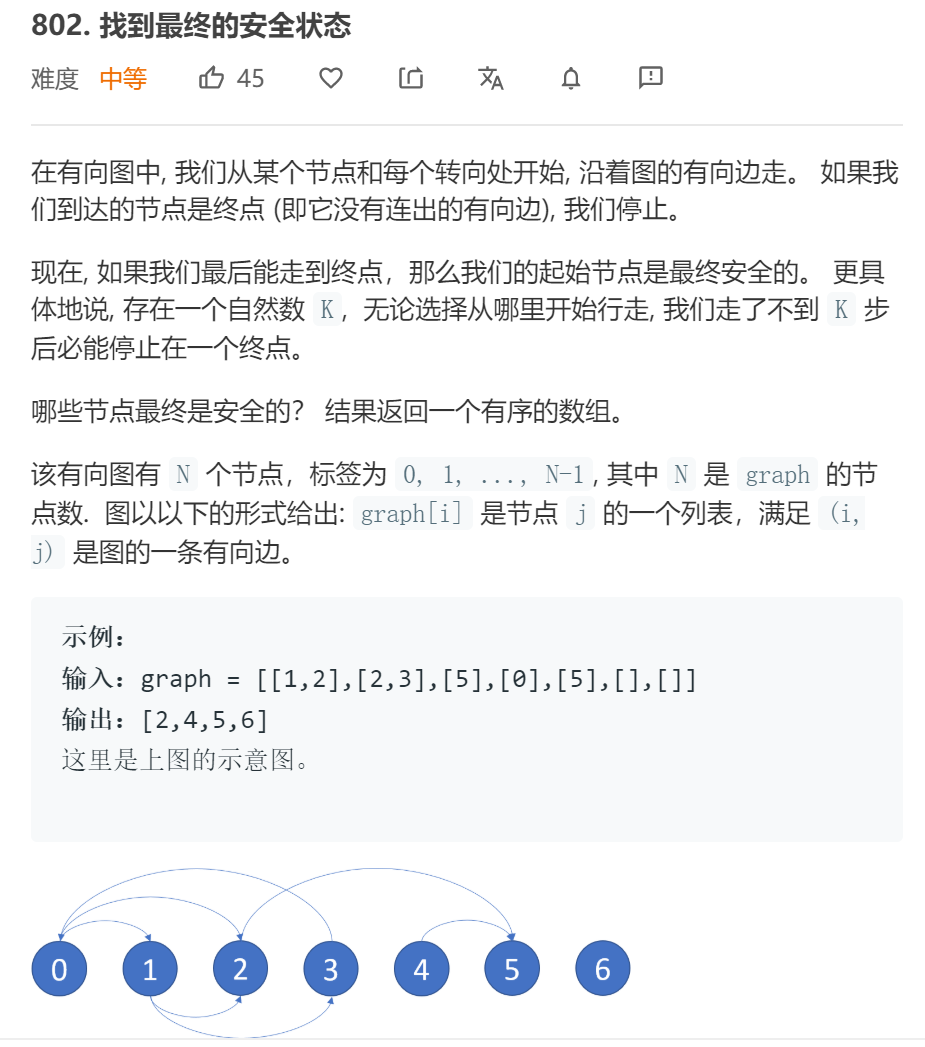
题解
class Solution {
public:
vector<int> eventualSafeNodes(vector<vector<int>>& graph) {
int n = graph.size();
vector<int> outDegree(n, 0); // 维护出度
vector<vector<int>> revGraph(n, vector<int>{});
vector<int> ans;
for (int i =0; i < n; i++){
outDegree[i] = graph[i].size();
for (auto &end : graph[i]){
revGraph[end].push_back(i);
}
}
queue<int> q;
for (int i =0; i< n ; i++){
if (outDegree[i] == 0) q.push(i);
}
while (!q.empty()){
int f = q.front();
ans.push_back(f);
q.pop();
for (auto start: revGraph[f]){
outDegree[start]--;
if (outDegree[start] == 0) q.push(start);
}
}
sort(ans.begin(), ans.end());
return ans;
}
};
2.3.1 该题的设计思路
设计思路
定义安全的点:路径终点,也就是出度为0的点
定义最终安全的点:从起始节点开始,可以沿某个路径到达终点,那么起始节点就是最终安全的点。
1.找到出度为0的顶点,这些点是安全的点
2.逆向删除以出度为0的顶点为弧头的边,弧尾的出度减一
3.重复上面两步,直到不存在出度为0的顶点
- 时间复杂度:O(n²)。for循环统计出度并同时逆转有向边,最后进行拓扑排序
- 空间复杂度:O(n²)。需要记录出度和逆向边
2.3.2 该题的伪代码
伪代码
定义vector<int> outDegree统计出度
定义vector<vector<int>> revGraph(n, vector<int>{})记录逆向边
for i=0 to 顶点数
统计出度
for 遍历顶点i的边结点
逆转边关系
end for
end for
for i=0 to 顶点数
入队出度为0的顶点
end for
while 队列不空
出队f,记录顶点
for 遍历逆向邻接表
边结点的出度-1
if 边结点出度为0 then 入队
end for
end for
对结果数组排序
返回结果数组
2.3.3 运行结果

2.3.4分析该题目解题优势及难点
本题的实质也是拓扑排序,不过不同的是出度为0的先输出。题解在计算出度的同时也将逆向边的关系记录到revGraph,方便了后面出度的删减,其他的操作可以类比拓扑排序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号