【spark】共享变量
Spark中的两个重要抽象是RDD和共享变量。
一般情况下,当Spark在集群的多个不同节点的多个任务上并行运行一个函数的时候,
它会把函数中涉及到的每个变量在每个节点每个任务上都生成一个副本。
Spark 操作实际上操作的是这个函数所用变量的一个独立副本。
这些变量被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。
通常跨任务的读写变量是低效的。
但是,有时候我们需要在多个任务之间共享变量,或者在任务和任务控制节点之间共享变量。
为了满足这种需求,Spark提供了两种有限的共享变量:广播变量( broadcast variable )和累加器( accumulator )。
1.广播变量
广播变量用来把变量在所有节点的内存之间进行共享。
广播变量允许开发人员在每台机器上缓存一个只读的变量,而不是为每台机器上每个任务生成一个副本 。
Spark的任务操作一般会跨越多个阶段,对于每个阶段内的所有任务所需要的公共数据,Spark都会自动进行广播。
语法:
SparkContext.broadcase(v);
广播变量就是对普通变量v的一个包装器,通过调用value方法就可以获取这个广播变量的值。
//建立内容为Array(1,2,3)的广播变量 val broadcastVal = sc.broadcast(Array(1,2,3)) //获取广播变量的值 broadcastVal.value()
注意:我们在把变量v建立成广播变量后,在集群中的任何函数,都应该使用broadcase(v),而不是v本身,
这样就不会把v重复的分发到使用变量v的节点上。此外,我们一旦建立了broadcase(v)之后,就不行再次发生修改。
2.累加器
累加器支持在所有不同节点之间进行累加操作。
累加器是仅仅被相关操作累加的变量,通常可以被用来实现计数器和求和。
Spark原生地支持数值型(numeric)的累加器,也可以自己编写对新类型的累加器。
可以通过SparkContext.longAccumulator()或者SparkContext.doubleAccumulator()来创建累加器。
参数有两个(Int,String),第一个参数为初始累加值,默认为0,第二个参数为累加器的名字。
运行在集群中的任务,就可以使用add()方法来把数值累加到累加器上。
但是任务节点执行做累加操作,不能读取累加器的值,只有任务控制节点(Driver Program)可以使用value方法来读取。
import org.apache.spark._
object MyRdd {
def main(args:Array[String]): Unit ={
//初始化配置:设置主机名和程序主类的名字
val conf = new SparkConf().setMaster("local").setAppName("MyRdd");
//通过conf来创建sparkcontext
val sc = new SparkContext(conf);
val accum = sc.longAccumulator("My Accumulator");//后边是计数器的名字
val list = List(1,2,3,4,5);
val rdd = sc.parallelize(list);
rdd.foreach(x => accum.add(x));//调用累加器求和
accum.value;//注意只有任务控制节点(Driver节点)才能使用value方法来获取累加器的值
}
}
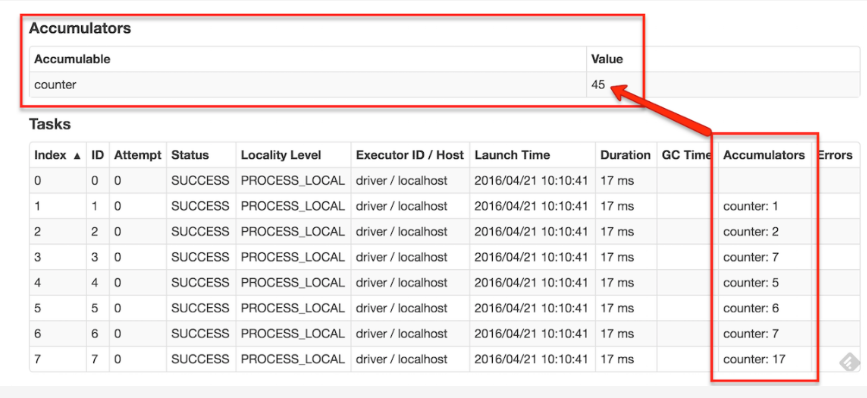
如果创建了一个具名的累加器,它可以在spark的UI中显示。这对于理解运行阶段(running stages)的过程有很重要的作用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号