数据增强长尾
The Majority Can Help The Minority: Context-rich Minority Oversampling for Long-tailed Classification arxiv2021
尾类的样本过采样来(受上下文限制)增加样本量。
动机:简单的重采样因为近似的图像上下文过拟合,本文把头类作为背景,尾类作前景进行数据扩充。
分析:由于对多数类样本和少数类样本的插值,因此在决策边界附近产生了多样化的数据,Cutmix可能聚焦点仍然在多数类。
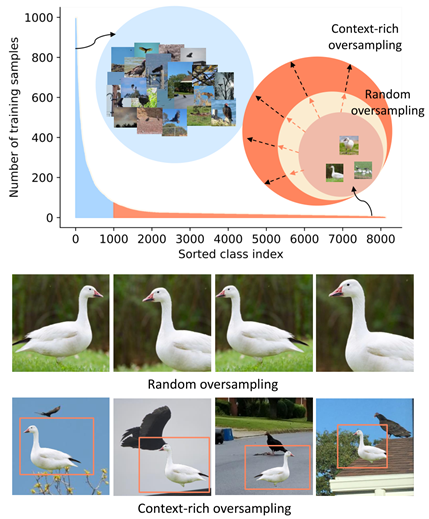

这个环境是人为匹配的,蝴蝶对应花朵的背景等等(????)
Realate:DOS[1]需要在特征空间中寻找最近的邻居,FSA[8]需要预先训练的特征子网和特征增强过程的分类器。最后,MetaSAug[24]要求额外的统一验证样本(relate不全,数据扩充竟没有RSG)
整篇文章就是cutmix,算法步骤一样,仅仅是加了区分前景背景
数据增强(https://blog.csdn.net/yuansiming0920/article/details/115380822)
Cutout(2017):对一张图像随机选取一个小正方形区域,在这个区域的像素值设置为0,分类的结果不变;依据是Cutout能够让CNN更好地利用图像的全局信息,而不是依赖于一小部分特定的视觉特征。

Random Erasing(2017):类似于Cutout,这两者同一年发表的。与Cutout不同的是,Random Erasing mask区域的长宽,以及区域中像素值的替代值都是随机的,Cutout是固定使用正方形,替代值都使用同一个。

Hide-and-Seek(ICCV 2017):主要思想就是将图片划分为S x S的网格,每个网格按一定的概率(0.5)进行mask。其中不可避免地会完全mask掉一个完整的小目标
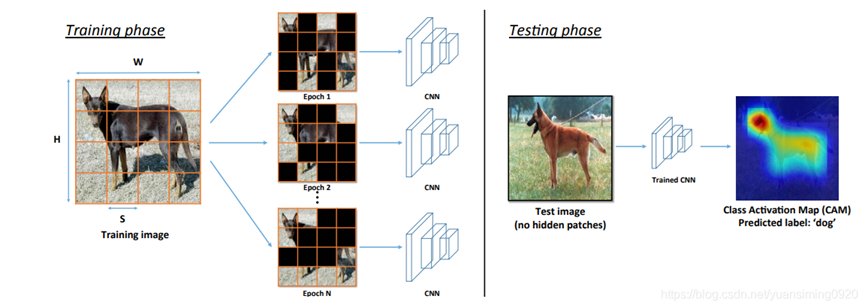
CutMix(ICCV 2019):该方法结合了Cutout、Random erasing和Mixup三者的思想,做了一些中间调和的改变,同样是选择一个小区域,进行mask,但mask的方式却是将另一张图片的该区域覆盖到这里。

GridMask(2020):对前几种方法的改进,由于前几种对于mask区域的选择都是随机的,因此容易出现对重要部位全掩盖的情况。而GridMask则最多出现部分掩盖,且几乎一定会出现部分掩盖。使用的方式是排列的正方形区域来进行掩码(具体实现是通过设定每个小正方形的边长,两个mask之间的距离d来确定mask,从而控制mask细粒度)

FenceMask(arxiv 2020):对前面GridMask的改进,认为使用正方形的掩码会对小目标有很大的影响。因此提出了更好的形状,FenceMask具有更好的细粒度

AutoAugment(CVPR 2019):利用增强学习来找到用于选择和组合不同的标签不变变换(例如,旋转、颜色反转、翻转)的最佳策略,训练一个policy去选择合适的augment参数。 

数据增强在解决很多深度学习的问题上是一个至关重要的的技术。ta增加了有效数据的大小,提升了训练样本的多样性,但是不可避免的在训练过程中引入了噪声和歧义性。因此如果数据增强没有被适当的调整的话,整个性能将会变坏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号