

计算视觉——SIFT特征提取与检索
- 一、SIFT介绍
- 1 SIFT(尺度不变特征变换)原理
SIFT包括兴趣点检测器和描述子。SIFT描述子具有非常强的稳健性,经常和许多不同的兴趣点检测器结合使用。SIFT特征对于尺度,旋转和亮度都具有不变性,因此,它可用于三维视角和噪声的可靠匹配。
SIFT 描述子h(x, y,θ)是对特征点附近邻域内高斯图像梯度统计结果的一种表示,它是一个三维的阵列,但通常将它表示成一个矢量。矢量是通过对三维阵列按一定规律进行排列得到的。特征描述子与特征点所在的尺度有关,因此,对梯度的求取应在特征点对应的高斯图像上进行。
- 2 SIFT算法的实现步骤
构建尺度空间,检测极值点,获得尺度不变性;
特征点过滤并进行精确定位,剔除不稳定的特征点;
在特征点处提取特征描述符,为特征点分配方向值;
生成特征描述子,利用特征描述符寻找匹配点;
计算变换参数。
- 3 SIFT算法的数学表达
确定描述子采样区域
SIFI 描述子h(x, y,θ)是对特征点附近邻域内高斯图像梯度统计结果的一种表示。将特征点附近邻域划分成BpX Bp个子区域,每个子区域的尺寸为mσ个像元,其中,m=3,Bp=4。σ为特征点的尺度值。考虑到实际计算时,需要采用双线性插值,计算的图像区域为mσ(Bp+ 1)。如果再考虑旋转的因素,那么,实际计算的图像区域应大mσ(Bp+ 1)√2。
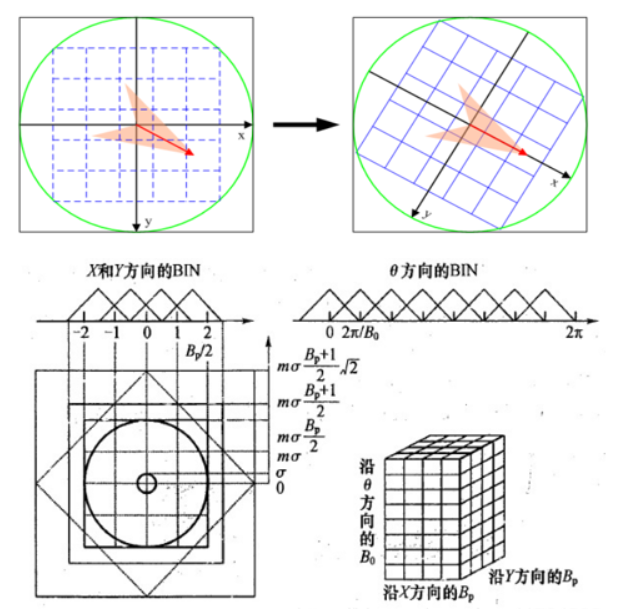
生成描述子
2.1 旋转图像至主方向
为了保证特征矢量具有旋转不变性,需要以特征点为中心,将特征点附近邻域内(mσ(Bp+ 1)√2 x mσ(Bp+ 1)√2)图像梯度的位置和方向旋转一个方向角θ,即将原图像x轴转到与主方向相同的方向。旋转公式如下:
在特征点附近邻域图像梯度的位置和方向旋转后,再以特征点为中心,在旋转后的图像中取一个mσBp x mσBp大小的图像区域。并将它等间隔划分成Bp X Bp个子区域,每个间隔为mσ像元。
2.2 生成特征向量
在每子区域内计算8个方向的梯度方向直方图,绘制每个梯度方向的累加值,形成一个种子点。与求特征点主方向时有所不同,此时,每个子区域的梯度方向直方图将0° -360°划分为8个方向范围,每个范围为45°,这样,每个种子点共有8个方向的梯度强度信息。由于存在4X4(Bp X Bp)个子区域,所以,共有4X4X8=128个数据,最终形成128维的SIFT特征矢量。
3.归一化特征向量
为了去除光照变化的影响,需对上述生成的特征向量进行归一化处理,在归一化处理后,对特征矢量大于α的要进行截断处理,即大于α的值只取α,然后重新进行一次归一化处理,其目的是为了提高鉴别性
- 实验结果及分析
- SIFT特征提取

起初选取15张图片作为数据集,但因各种原因导致像素不同无法运行,后加入数张其他图片,最终数据集总量为20张
1.结果及代码展示

2.结果分析
1)SIFT特征提取和检测算法提取到的特征点明显多于Harris角点检测,由于在一定程度上增加了图像的特征点,从后续的特征匹配的工作角度上考虑可知:SIFT算法明显优于Harris算法。在一定程度上这体现了SIFT特征提取与检测算法的优越性。
2) 从时间效率上来分析,SIFT特征提取和检测消耗了大量的时间,对于一些特征点丰富且像素点较多的图像的检测时间多达5分钟左右,但其提取特征的准确性不可忽略,大可忽略其时间效率影响。可进行进一步分析,对SIFT算法进行简单优化。
SIFT特征匹配
1.结果及代码展示

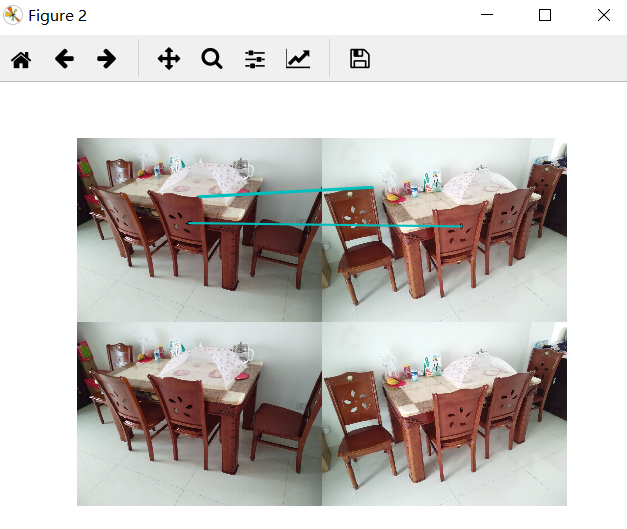

以1.jpg这张图片作为匹配图
匹配结果如下


2.结果分析
1)匹配的时候通过把每张图的特征向量表示出来,然后找到特征向量重合度最高的图片。一开始运行速度很慢,后压缩图片格式,将图片大小减小为200kb左右,运行速度有了显著提升。
- 地理匹配
由于上次使用的数据集已删除,故此次实验选用的是以前照的其他相片
1.第一次运行后,发现运行结果是这样的
经百度后得知这是因为图片没有选择绝对路径,下面是修改后的实验结果
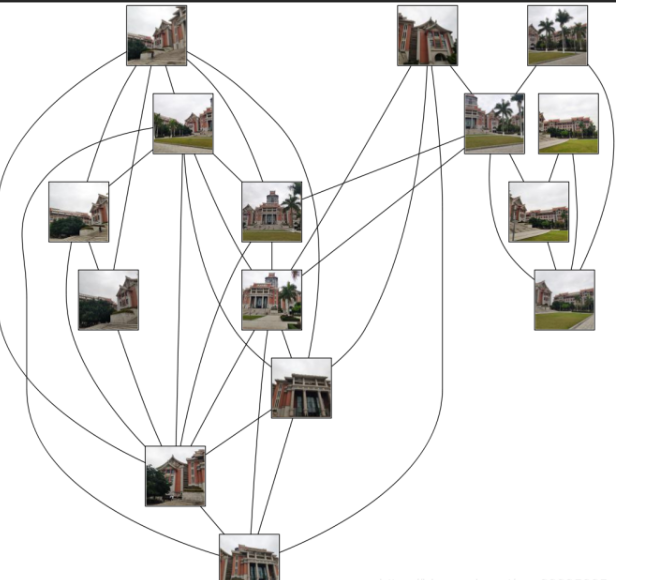
分析
从结论上说起,可以说SIFT算法准确。左侧这组中图中延奎图书馆侧面的图片归为这一类,因为建筑的纹理相仿,但是不足的是有两张图书馆的图片跑到右边去了,右边照片明显以草丛特征居多,特征点较多的原因导致分类不准确,说明SIFT算法对于拍摄图像特征点周围纹理多且复杂,如树等,分类效果不佳。
右侧这组分类其实觉得不算特别准确,首先在四张陆大楼的照片中混入了两张延奎图书馆,这个前面说了,可能是由于特征点较多导致分类错误。还有明显属于不同于其他图片的,比如右上角,这显然是一张植被图,也被归为一类,可能因为不同楼房和植物图出现的部分楼房颜色相近,导致分类不准确,说明SIFT算法当拍摄图像特征点周围纹理相近,颜色相近,分类效果不佳。 但也由于这次拍摄的图片没有进行较好的分类拍摄,类别区分过少,树的图片出现部分的楼房,可能对分类造成影响,总体来说SIFT算法分类较为准确。
2.代码
# -*- coding: utf-8 -*- %matplotlib inline from pylab import * from PIL import Image from PCV.localdescriptors import sift from PCV.tools import imtools import pydot import os os.environ['PATH'] = os.environ['PATH'] + (';c:\\Program Files (x86)\\Graphviz2.38\\bin\\') """ This is the example graph illustration of matching images from Figure 2-10. To download the images, see ch2_download_panoramio.py.""" #download_path = "panoimages" # set this to the path where you downloaded the panoramio images #path = "/FULLPATH/panoimages/" # path to save thumbnails (pydot needs the full system path) download_path = "C:/Users/mangowu/Desktop/11" # set this to the path where you downloaded the panoramio images path = "C:/Users/mangowu/Desktop/11/" # path to save thumbnails (pydot needs the full system path) # list of downloaded filenames imlist = imtools.get_imlist(download_path) nbr_images = len(imlist) # extract features featlist = [imname[:-3] + 'sift' for imname in imlist] for i, imname in enumerate(imlist): sift.process_image(imname, featlist[i]) matchscores = zeros((nbr_images, nbr_images)) for i in range(nbr_images): for j in range(i, nbr_images): # only compute upper triangle print ('comparing ', imlist[i], imlist[j]) l1, d1 = sift.read_features_from_file(featlist[i]) l2, d2 = sift.read_features_from_file(featlist[j]) matches = sift.match_twosided(d1, d2) nbr_matches = sum(matches > 0) print ('number of matches = ', nbr_matches) matchscores[i, j] = nbr_matches print ("The match scores is: \n", matchscores) # copy values for i in range(nbr_images): for j in range(i + 1, nbr_images): # no need to copy diagonal matchscores[j, i] = matchscores[i, j] #可视化 threshold = 2 # min number of matches needed to create link g = pydot.Dot(graph_type='graph') # don't want the default directed graph for i in range(nbr_images): for j in range(i + 1, nbr_images): if matchscores[i, j] > threshold: # first image in pair im = Image.open(imlist[i]) im.thumbnail((100, 100)) filename = path + str(i) + '.png' im.save(filename) # need temporary files of the right size g.add_node(pydot.Node(str(i), fontcolor='transparent', shape='rectangle', image=filename)) # second image in pair im = Image.open(imlist[j]) im.thumbnail((100, 100)) filename = path + str(j) + '.png' im.save(filename) # need temporary files of the right size g.add_node(pydot.Node(str(j), fontcolor='transparent', shape='rectangle', image=filename)) g.add_edge(pydot.Edge(str(i), str(j))) g.write_png('whitehouse.png')
基于RANSAC对SIFT特征匹配进行分析
RANSAC
RANSAC为RANdom SAmple Consensus的缩写,它是根据一组包含异常数据的样本数据集,计算出数据的数学模型参数,得到有效样本数据的算法。它于1981年由 Fischler和Bolles最先提出[1]。
RANSAC算法的基本假设是样本中包含正确数据(inliers,可以被模型描述的数据),也包含异常数据(Outliers,偏离正常范 围很远、无法适应数学模型的数据),即数据集中含有噪声。这些异常数据可能是由于错误的测量、错误的假设、错误的计算等产生的。同时RANSAC也假设, 给定一组正确的数据,存在可以计算出符合这些数据的模型参数的方法。
RANSAC基本思想
①考虑一个最小抽样集的势为n的模型(n为初始化模型参数所需的最小样本数)和一个样本集P,集合P的样本数num(P)>n,从P中随机 抽取包含n个样本的P的子集S初始化模型M;
②余集SC=P\S中与模型M的误差小于某一设定阈值t的样本集以及S构成S*。S*认为是内点集,它们构成S的一致集(Consensus Set);
③若#(S*)≥N,认为得到正确的模型参数,并利用集S*(内点inliers)采用最小二乘等方法重新计算新的模型M*;重新随机抽取新 的S,重复以上过程。
④在完成一定的抽样次数后,若为找到一致集则算法失败,否则选取抽样后得到的最大一致集判断内外点,算法结束。
由上可知存在两个可能的算法优化策略。①如果在选取子集S时可以根据某些已知的样本特性等采用特定的选取方案或有约束的随机选取来代替原来的 完全随机选取;②当通过一致集S*计算出模型M*后,可以将P中所有与模型M*的误差小于t的样本加入S*,然后重新计算M*。
RANSAC算法包括了3个输入的参数:①判断样本是否满足模型的误差容忍度t。t可以看作为对内点噪声均方差的假设,对于不同的输入数据需 要采用人工干预的方式预设合适的门限,且该参数对RANSAC性能有很大的影响;②随机抽取样本集S的次数。该参数直接影响SC中样本参与模型参数的检验 次数,从而影响算法的效率,因为大部分随机抽样都受到外点的影响;③表征得到正确模型时,一致集S*的大小N。为了确保得到表征数据集P的正确模型,一般 要求一致集足够大;另外,足够多的一致样本使得重新估计的模型参数更精确。
RANSAC算法经常用于计算机视觉中。例如,在立体视觉领域中同时解决一对相机的匹配点问题及基本矩阵的计算。
RANSAC去除错配
CvMat* ransac_xform( struct feature* features, int n, int mtype, ransac_xform_fn xform_fn, int m, double p_badxform, ransac_err_fn err_fn, double err_tol, struct feature*** inliers, int* n_in ) { //matched:所有具有mtype类型匹配点的特征点的数组,也就是样本集 //sample:单个样本,即4个特征点的数组 //consensus:当前一致集; //consensus_max:当前最大一致集(即当前的最好结果的一致集) struct feature** matched, ** sample, ** consensus, ** consensus_max = NULL; struct ransac_data* rdata;//每个特征点的feature_data域的ransac数据指针 CvPoint2D64f* pts, * mpts;//每个样本对应的两个坐标数组:特征点坐标数组pts和匹配点坐标数组mpts CvMat* M = NULL;//当前变换矩阵 //p:当前计算出的模型的错误概率,当p小于p_badxform时迭代停止 //in_frac:内点数目占样本总数目的百分比 double p, in_frac = RANSAC_INLIER_FRAC_EST; //nm:输入的特征点数组中具有mtype类型匹配点的特征点个数 //in:当前一致集中元素个数 //in_min:一致集中元素个数允许的最小值,保证RANSAC最终计算出的转换矩阵错误的概率小于p_badxform所需的最小内点数目 //in_max:当前最优一致集(最大一致集)中元素的个数 //k:迭代次数,与计算当前模型的错误概率有关 int i, nm, in, in_min, in_max = 0, k = 0; //找到特征点数组features中所有具有mtype类型匹配点的特征点,放到matched数组(样本集)中,返回值nm是matched数组的元素个数 nm = get_matched_features( features, n, mtype, &matched ); //若找到的具有匹配点的特征点个数小于计算变换矩阵需要的最小特征点对个数,出错 if( nm < m ) { //出错处理,特征点对个数不足 fprintf( stderr, "Warning: not enough matches to compute xform, %s" \ " line %d\n", __FILE__, __LINE__ ); goto end; } /* initialize random number generator */ srand( time(NULL) );//初始化随机数生成器 //计算保证RANSAC最终计算出的转换矩阵错误的概率小于p_badxform所需的最小内点数目 in_min = calc_min_inliers( nm, m, RANSAC_PROB_BAD_SUPP, p_badxform ); //当前计算出的模型的错误概率,内点所占比例in_frac越大,错误概率越小;迭代次数k越大,错误概率越小 p = pow( 1.0 - pow( in_frac, m ), k ); i = 0; //当前错误概率大于输入的允许错误概率p_badxform,继续迭代 while( p > p_badxform ) { //从样本集matched中随机抽选一个RANSAC样本(即一个4个特征点的数组),放到样本变量sample中 sample = draw_ransac_sample( matched, nm, m ); //从样本中获取特征点和其对应匹配点的二维坐标,分别放到输出参数pts和mpts中 extract_corresp_pts( sample, m, mtype, &pts, &mpts ); //调用参数中传入的函数xform_fn,计算将m个点的数组pts变换为mpts的矩阵,返回变换矩阵给M M = xform_fn( pts, mpts, m );//一般传入lsq_homog()函数 if( ! M )//出错判断 goto iteration_end; //给定特征点集,变换矩阵,误差函数,计算出当前一致集consensus,返回一致集中元素个数给in in = find_consensus( matched, nm, mtype, M, err_fn, err_tol, &consensus); //若当前一致集大于历史最优一致集,即当前一致集为最优,则更新最优一致集consensus_max if( in > in_max ) { if( consensus_max )//若之前有最优值,释放其空间 free( consensus_max ); consensus_max = consensus;//更新最优一致集 in_max = in;//更新最优一致集中元素个数 in_frac = (double)in_max / nm;//最优一致集中元素个数占样本总个数的百分比 } else//若当前一致集小于历史最优一致集,释放当前一致集 free( consensus ); cvReleaseMat( &M ); iteration_end: release_mem( pts, mpts, sample ); p = pow( 1.0 - pow( in_frac, m ), ++k ); } //根据最优一致集计算最终的变换矩阵 /* calculate final transform based on best consensus set */ //若最优一致集中元素个数大于最低标准,即符合要求 if( in_max >= in_min ) { //从最优一致集中获取特征点和其对应匹配点的二维坐标,分别放到输出参数pts和mpts中 extract_corresp_pts( consensus_max, in_max, mtype, &pts, &mpts ); //调用参数中传入的函数xform_fn,计算将in_max个点的数组pts变换为mpts的矩阵,返回变换矩阵给M M = xform_fn( pts, mpts, in_max ); /***********下面会再进行一次迭代**********/ //根据变换矩阵M从样本集matched中计算出一致集consensus,返回一致集中元素个数给in in = find_consensus( matched, nm, mtype, M, err_fn, err_tol, &consensus); cvReleaseMat( &M ); release_mem( pts, mpts, consensus_max ); //从一致集中获取特征点和其对应匹配点的二维坐标,分别放到输出参数pts和mpts中 extract_corresp_pts( consensus, in, mtype, &pts, &mpts ); //调用参数中传入的函数xform_fn,计算将in个点的数组pts变换为mpts的矩阵,返回变换矩阵给M M = xform_fn( pts, mpts, in ); if( inliers ) { *inliers = consensus;//将最优一致集赋值给输出参数:inliers,即内点集合 consensus = NULL; } if( n_in ) *n_in = in;//将最优一致集中元素个数赋值给输出参数:n_in,即内点个数 release_mem( pts, mpts, consensus ); } else if( consensus_max ) { //没有计算出符合要求的一致集 if( inliers ) *inliers = NULL; if( n_in ) *n_in = 0; free( consensus_max ); } //RANSAC算法结束:恢复特征点中被更改的数据域feature_data,并返回变换矩阵M end: for( i = 0; i < nm; i++ ) { //利用宏feat_ransac_data来提取matched[i]中的feature_data成员并转换为ransac_data格式的指针 rdata = feat_ransac_data( matched[i] ); //恢复feature_data成员的以前的值 matched[i]->feature_data = rdata->orig_feat_data; free( rdata );//释放内存 } free( matched ); return M;//返回求出的变换矩阵M }
//特征提取和匹配 void match(IplImage *img1,IplImage *img2) { IplImage *img1_Feat = cvCloneImage(img1);//复制图1,深拷贝,用来画特征点 IplImage *img2_Feat = cvCloneImage(img2);//复制图2,深拷贝,用来画特征点 struct feature *feat1, *feat2;//feat1:图1的特征点数组,feat2:图2的特征点数组 int n1, n2;//n1:图1中的特征点个数,n2:图2中的特征点个数 struct feature *feat;//每个特征点 struct kd_node *kd_root;//k-d树的树根 struct feature **nbrs;//当前特征点的最近邻点数组 int matchNum;//经距离比值法筛选后的匹配点对的个数 struct feature **inliers;//精RANSAC筛选后的内点数组 int n_inliers;//经RANSAC算法筛选后的内点个数,即feat1中具有符合要求的特征点的个数 //默认提取的是LOWE格式的SIFT特征点 //提取并显示第1幅图片上的特征点 n1 = sift_features( img1, &feat1 );//检测图1中的SIFT特征点,n1是图1的特征点个数 export_features("feature1.txt",feat1,n1);//将特征向量数据写入到文件 draw_features( img1_Feat, feat1, n1 );//画出特征点 cvShowImage("img1_Feat",img1_Feat);//显示 //提取并显示第2幅图片上的特征点 n2 = sift_features( img2, &feat2 );//检测图2中的SIFT特征点,n2是图2的特征点个数 export_features("feature2.txt",feat2,n2);//将特征向量数据写入到文件 draw_features( img2_Feat, feat2, n2 );//画出特征点 cvShowImage("img2_Feat",img2_Feat);//显示 Point pt1,pt2;//连线的两个端点 double d0,d1;//feat1中每个特征点到最近邻和次近邻的距离 matchNum = 0;//经距离比值法筛选后的匹配点对的个数 //将2幅图片合成1幅图片,上下排列 stacked = stack_imgs( img1, img2 );//合成图像,显示经距离比值法筛选后的匹配结果 stacked_ransac = stack_imgs( img1, img2 );//合成图像,显示经RANSAC算法筛选后的匹配结果 //根据图2的特征点集feat2建立k-d树,返回k-d树根给kd_root kd_root = kdtree_build( feat2, n2 ); //遍历特征点集feat1,针对feat1中每个特征点feat,选取符合距离比值条件的匹配点,放到feat的fwd_match域中 for(int i = 0; i < n1; i++ ) { feat = feat1+i;//第i个特征点的指针 //在kd_root中搜索目标点feat的2个最近邻点,存放在nbrs中,返回实际找到的近邻点个数 int k = kdtree_bbf_knn( kd_root, feat, 2, &nbrs, KDTREE_BBF_MAX_NN_CHKS ); if( k == 2 ) { d0 = descr_dist_sq( feat, nbrs[0] );//feat与最近邻点的距离的平方 d1 = descr_dist_sq( feat, nbrs[1] );//feat与次近邻点的距离的平方 //若d0和d1的比值小于阈值NN_SQ_DIST_RATIO_THR,则接受此匹配,否则剔除 if( d0 < d1 * NN_SQ_DIST_RATIO_THR ) { //将目标点feat和最近邻点作为匹配点对 pt1 = Point( cvRound( feat->x ), cvRound( feat->y ) );//图1中点的坐标 pt2 = Point( cvRound( nbrs[0]->x ), cvRound( nbrs[0]->y ) );//图2中点的坐标(feat的最近邻点) pt2.y += img1->height;//由于两幅图是上下排列的,pt2的纵坐标加上图1的高度,作为连线的终点 cvLine( stacked, pt1, pt2, CV_RGB(255,0,255), 1, 8, 0 );//画出连线 matchNum++;//统计匹配点对的个数 feat1[i].fwd_match = nbrs[0];//使点feat的fwd_match域指向其对应的匹配点 } } free( nbrs );//释放近邻数组 } qDebug()<<tr("经距离比值法筛选后的匹配点对个数:")<<matchNum<<endl; //显示并保存经距离比值法筛选后的匹配图 cvNamedWindow(IMG_MATCH1);//创建窗口 cvShowImage(IMG_MATCH1,stacked);//显示 //利用RANSAC算法筛选匹配点,计算变换矩阵H CvMat * H = ransac_xform(feat1,n1,FEATURE_FWD_MATCH,lsq_homog,4,0.01,homog_xfer_err,3.0,&inliers,&n_inliers); qDebug()<<tr("经RANSAC算法筛选后的匹配点对个数:")<<n_inliers<<endl; //遍历经RANSAC算法筛选后的特征点集合inliers,找到每个特征点的匹配点,画出连线 for(int i=0; i<n_inliers; i++) { feat = inliers[i];//第i个特征点 pt1 = Point(cvRound(feat->x), cvRound(feat->y));//图1中点的坐标 pt2 = Point(cvRound(feat->fwd_match->x), cvRound(feat->fwd_match->y));//图2中点的坐标(feat的匹配点) qDebug()<<"("<<pt1.x<<","<<pt1.y<<")--->("<<pt2.x<<","<<pt2.y<<")"<<endl; pt2.y += img1->height;//由于两幅图是上下排列的,pt2的纵坐标加上图1的高度,作为连线的终点 cvLine(stacked_ransac,pt1,pt2,CV_RGB(255,0,255),1,8,0);//画出连线 } cvNamedWindow(IMG_MATCH2);//创建窗口 cvShowImage(IMG_MATCH2,stacked_ransac);//显示 }
实验结果
景深丰富
- 未剔除

- 剔除后




景深单一
- 未剔除







- 剔除后







实验分析
景深单一实验中使用的是图片中仅有一幢房子,去除前可以发现很多错配点,匹配点较少的原因我觉得和两张图的光线不同关系较大。使用RANSAC去除后,仅剩下几个匹配点,但是去除过后发现正确率也并不高。
景深丰富实验中,使用的图片有角度的差异,可以看到Sift特征匹配得到了很多的匹配点,相应地错误匹配点也很多,使用RANSAC算法去除后匹配的点变少了,但是点大多是匹配正确的,只有少数几个错误的。
- 总结
1.图片可能由横屏或是竖屏拍摄存在尺寸上的差异,可是该算法只能对尺寸相同图片进行匹配,可通过裁剪或者再截图使其化为相同尺寸。
2.SIFT算法比起Harris算法,提取图像的特征点更加准确全面精准,更具有稳健性,效果上比起Harris算法更好。但是SIFT算法的运行速度相对来说慢很多。
3.SIFT算法匹配出的特征点多,即使两张图大小不一样、角度不一致也不会影响匹配结果,具有准确性和稳定性。
4.SIFT算法的可扩展性强,可以很方便的与其他形式的特征向量进行联合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号