

粒子群算法的寻优算法-非线性函数极值寻优
一、粒子群算法
定义
粒子群优化算法(Particle Swarm optimization,PSO)又翻译为粒子群算法、微粒群算法、或微粒群优化算法。是通过模拟鸟群觅食行为而发展起来的一种基于群体协作的随机搜索算法。通常认为它是群集智能 (Swarm intelligence, SI) 的一种。它可以被纳入多主体优化系统(Multiagent Optimization System, MAOS).粒子群优化算法是由Eberhart博士和kennedy博士发明。
模拟捕食
PSO模拟鸟群的捕食行为。一群鸟在随机搜索食物,在这个区域里只有一块食物。所有的鸟都不知道食物在那里。但是他们知道当前的位置离食物还有多远。那么找到食物的最优策略是什么呢。最简单有效的就是搜寻离食物最近的鸟的周围区域。
启示
PSO从这种模型中得到启示并用于解决优化问题。PSO中,每个优化问题的解都是搜索空间中的一只鸟。我们称之为“粒子”。所有的粒子都有一个由被优化的函数决定的适应值(fitnessvalue),每个粒子还有一个速度决定他们飞翔的方向和距离。然后粒子们就追随当前的最优粒子在解空间中搜索。
PSO初始化
PSO初始化为一群随机粒子(随机解),然后通过迭代找到最优解,在每一次叠代中,粒子通过跟踪两个“极值”来更新自己。第一个就是粒子本身所找到的最优解,这个解叫做个体极值pBest,另一个极值是整个种群找到的最优解,这个极值是全局极值gBest。另外也可以不用整个种群而只是用其中一部分最优粒子的邻居,那么在所有邻居中的极值就是局部极值。
二、算法介绍
在找到这两个最优值时,粒子根据如下的公式来更新自己的速度和新的位置
v[ ] = v[ ] + c1 * rand( ) * (pbest[ ] - present[ ]) + c2 * rand( ) * (gbest[ ] - present[ ]) (a)
present[ ] = present[ ] + v[ ] (b)
v[ ] 是粒子的速度, present[ ] 是当前粒子的位置. pbest[ ] and gbest[ ] 如前定义 rand ( ) 是介于(0, 1)之间的随机数. c1, c2 是学习因子. 通常 c1 = c2 = 2.
伪代码实现
For each particle
Initialize particle
END
Do
For each particle
Calculate fitness value
If the fitness value is better than the best fitness value (pBest) in history
set current value as the new pBest
End
Choose the particle with the best fitness value of all the particles as the gBest
For each particle
Calculate particle velocity according equation (a)
Update particle position according equation (b)
End
While maximum iterations or minimum error criteria is not attained
在每一维粒子的速度都会被限制在一个最大速度Vmax,如果某一维更新后的速度超过用户设定的Vmax,那么这一维的速度就被限定为Vmax。
与遗传算法的比较编辑
共同点
①种群随机初始化。
②对种群内的每一个个体计算适应值(fitness value)。适应值与最优解的距离直接有关。
③种群根据适应值进行复制。
④如果终止条件满足的话,就停止,否则转步骤② 。
从以上步骤,我们可以看到PSO和遗传算法有很多共同之处。两者都随机初始化种群,而且都使用适应值来评价系统,而且都根据适应值来进行一定的随机搜索。两个系统都不是保证一定找到最优解。但是,PSO没有遗传操作如交叉(crossover)和变异(mutation),而是根据自己的速度来决定搜索。粒子还有一个重要的特点,就是有记忆。
不同点
与遗传算法比较,PSO的信息共享机制是很不同的。在遗传算法中,染色体(chromosomes)互相共享信息,所以整个种群的移动是比较均匀的向最优区域移动。在PSO中, 只有gBest (orlBest) 给出信息给其他的粒子, 这是单向的信息流动。整个搜索更新过程是跟随当前最优解的过程。与遗传算法比较, 在大多数的情况下,所有的粒子可能更快的收敛于最优解。
优缺点
演化计算的优势,在于可以处理一些传统方法不能处理的。例子例如不可导的节点传递函数或者没有梯度信息存在。
但是缺点在于:
1、在某些问题上性能并不是特别好。
2.网络权重的编码而且遗传算子的选择有时比较麻烦。
最近已经有一些利用PSO来代替反向传播算法来训练神经网络的论文。研究表明PSO 是一种很有潜力的神经网络算法。PSO速度比较快而且可以得到比较好的结果。而且还没有遗传算法碰到的问题。
三、代码实现
参数


四、结果分析
1)c1=1.90,c2=1.50;w权重0.8
c1的值为1.9过大,使微粒过多的徘徊,使得多次测得的数据相差较大;最大时测得为9.998,最小时测得1.998


2)c1=1.70,c2=1.50;w权重0.8
c1的值为1.7过大,使微粒在局部徘徊,陷入局部最优结
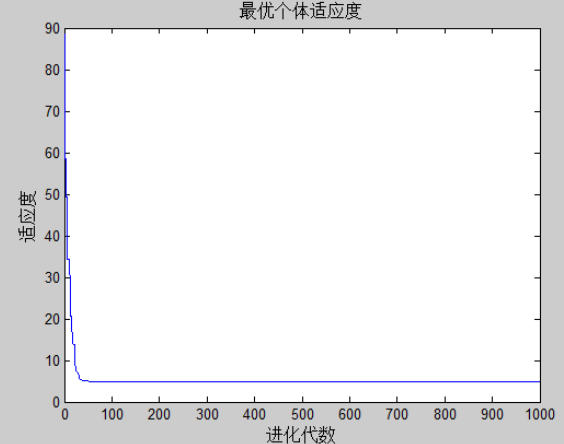

3)w不变,c1,c2对实验的影响
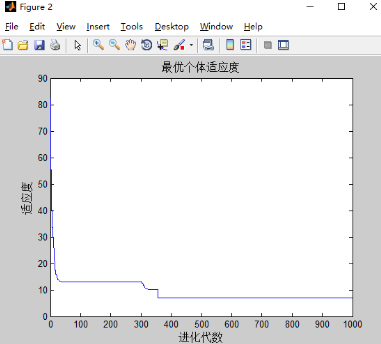
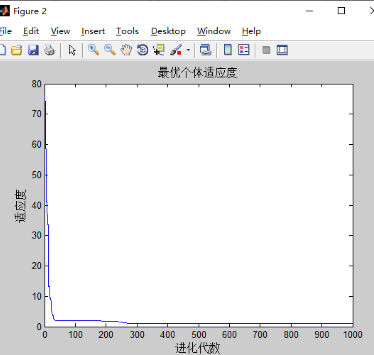
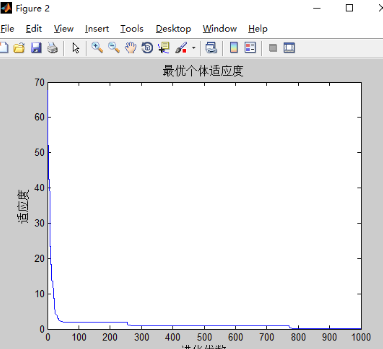
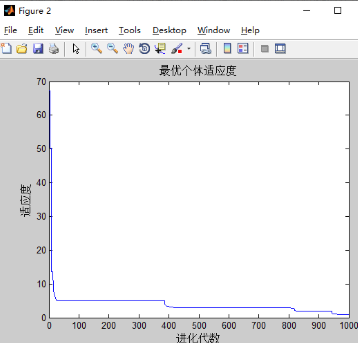
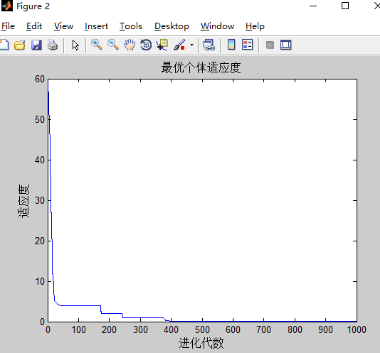
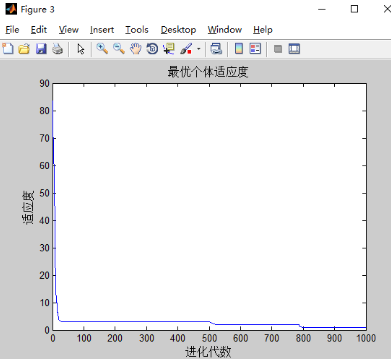
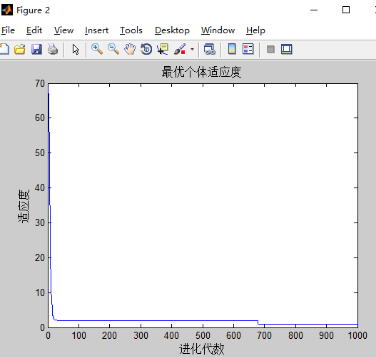
4)w不变,c1,c2对实验的影响
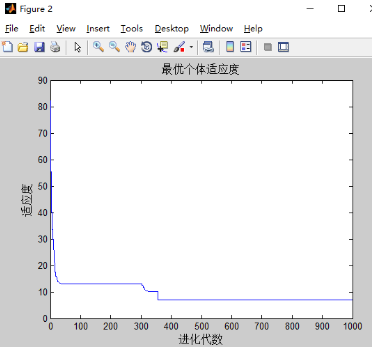
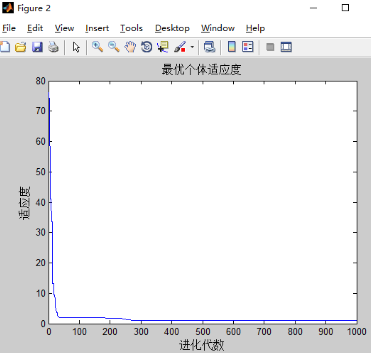
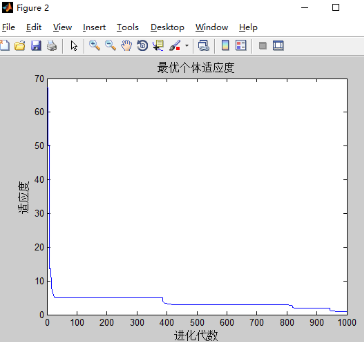
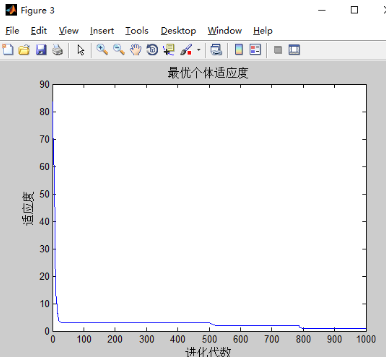
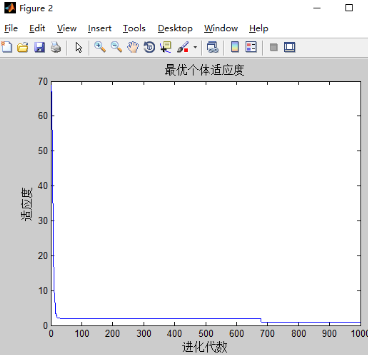
和之前只有w改变的实验结果差不多,可能三个都改变的影响下,w的改变占主导地位。w的影响最大。
5)sizepop和dim对实验的影响
维度为3,迭代次数为300
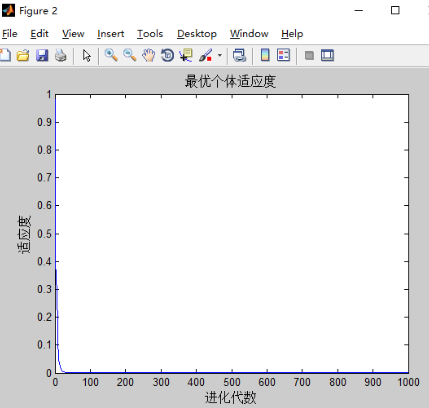
维度为3,迭代次数为300
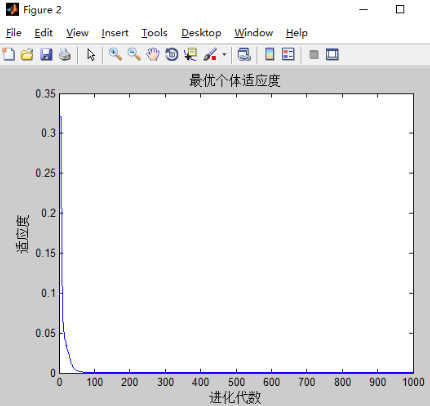
.维度为9,迭代次数为300
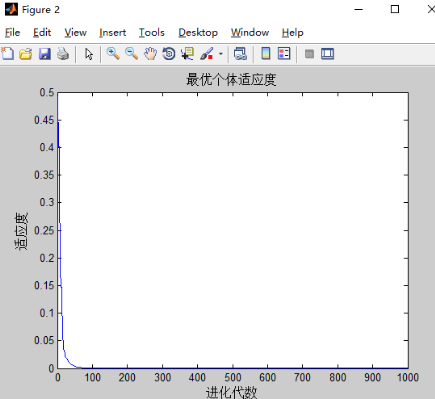
维度为9,迭代次数为800
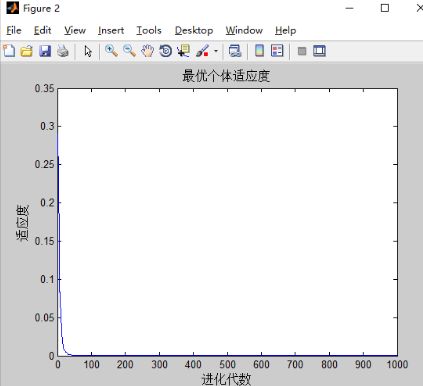
维度为12,迭代次数为800

随着多次对算法的运算和数据的统计,设置c1较大的值,会使微粒过多地在局部范围内徘徊,而较大的c2的值,则又会促使微粒过早收敛到局部最小值。因此加速因子设置在1.35~1.55合适;
较高的w设置促进全局搜索,较低的w设置促进快速的局部搜索.因此w设置0.5~0.8合适
维度的增大导致对算力要求增大,相应的需要增加迭代次数。当维度在8及以上时,迭代次数最少设置为1000
维度的增大,也要增加迭代次数
五、结论
1.c1,c2过小时,自身经验和社会经验在整个寻优过程中所起的作用小,使得寻优过程过于随机。
2.c1,c2过大时,调整的幅度过大,容易陷入局部最优中。
3.c1相对小,c2相对大时,将盲目的向gbest快速聚集,收敛速度加快的同时,盲目性使得粒子容易错过更好解,陷入局部最优中。
4.c1相对大,c2相对小时,粒子寻路线趋于多样化。粒子行为分散,而且进化速度慢,导致收敛速度慢,有时可能难以收敛。
5.种群和维度不会影响粒子群算法对Griewank寻优的结果。sizepop越大,搜索的精度越高,搜索的稳定性越好,但收敛速度较慢,种群规模小可以减少运行时间。
当维度越大时,越难以达到理论的最优解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号