



第三天
内容概要
- GEO地理位置信息
- 持久化方案
- 主从复制原理和方案
- 哨兵高可用
- 集群原理及搭建
- 缓存优化
GEO地理位置信息
-
GEO(地理位置定位):存储经纬度,计算两地距离,范围等
根据经纬度---》确定具体地址的---》高德开发api---》返回具体地址
-
redis 可以存储经纬度,存储可以做运算
比如:两个经纬度之间距离(直线距离)
比如:统计某个经纬度范围内有哪些好友,餐馆
-
经纬度如何获取
跟后端没关系:只需要存
app,有定位功能
网页,集成高德地图,定位功能
redis存储
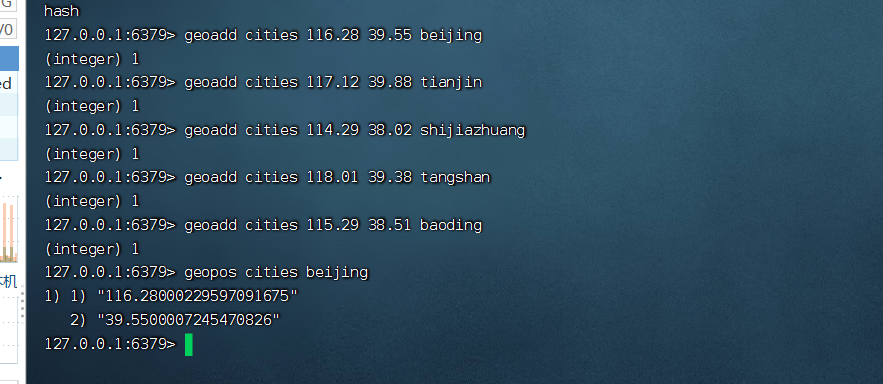
geoadd key 经度 维度 名字
添加
geoadd cities:locations 116.28 39.55 beijing #把北京地理信息天津到cities:locations中
geoadd cities:locations 117.12 39.88 tianjin
geoadd cities:locations 114.29 38.02 shijiazhuang
geoadd cities:locations 118.01 39.38 tangshan
geoadd cities:locations 115.29 38.51 baoding
查看位置信息
geopos cities:locations beijing # 获取北京地理信息
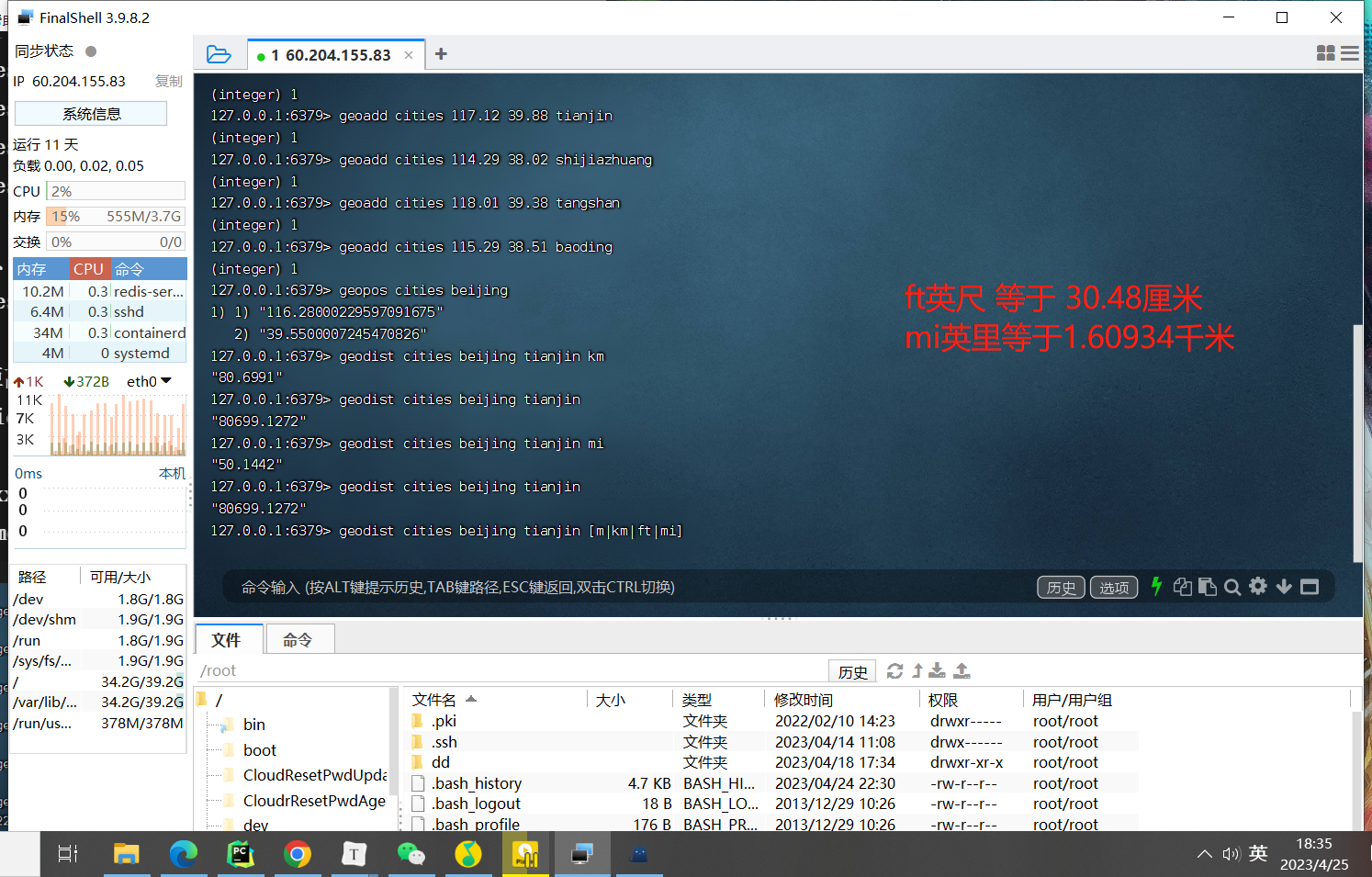
计算两个点距离
geodist cities:lcoations beijing tianjin km
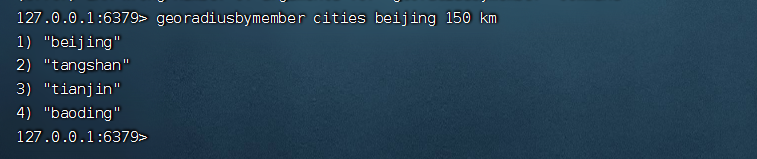
计算附近的 xx
georadiusbymember cities:locations beijing 150 km
持久化方案
什么是持久化
redis的所有数据保存在内存中,把内存中的数据同步到硬盘上,这个过程称之为持久化
持久化的实现方式
快照:某是某刻数据的一个完成备份
- mysql的Dump
- redis的RDB
写日志:任何操作记录日志,要恢复数据,只要把日志重新走一遍即可
mysql的binlog 热禁止日志
redis的AOF 二进制日志
RDB
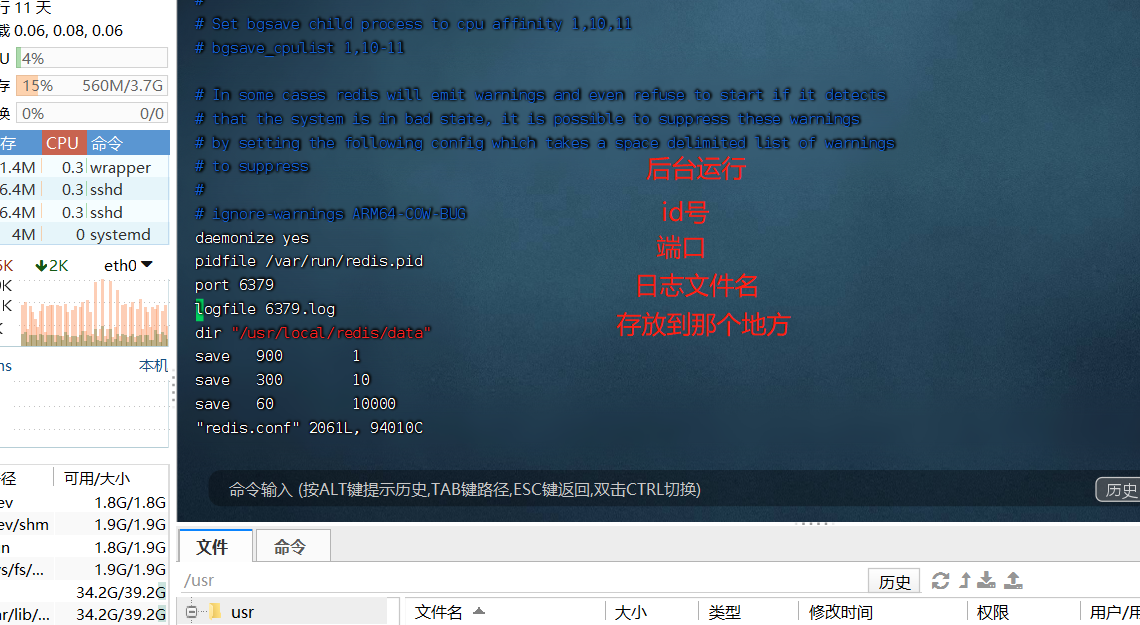
rdb持久化配置方式
方式一:通过命令---》同步操作
save:生成rdb持久化文件
方式二:异步持久化---》不会阻塞住其他命令的执行bgsave
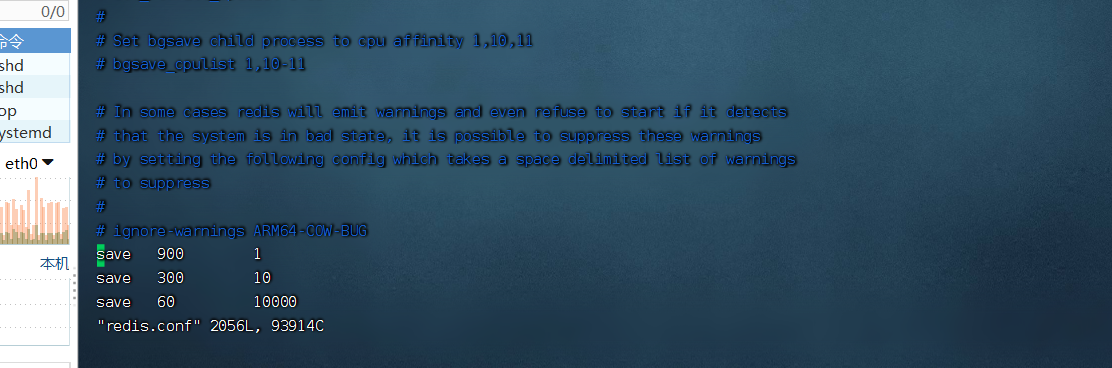
方式三:配置文件配置--》这个条件触发,就执行bgsave
save 900 1
save 300 10
save 60 10000
dbfilename dump.rdb
dir "/root/redis-6.2.9/data"
如果60s中改变了1w条数据,自动生成rdb
如果300s中改变了10条数据,自动生成rdb
如果900s中改变了1条数据,自动生成rdb

AOF方案
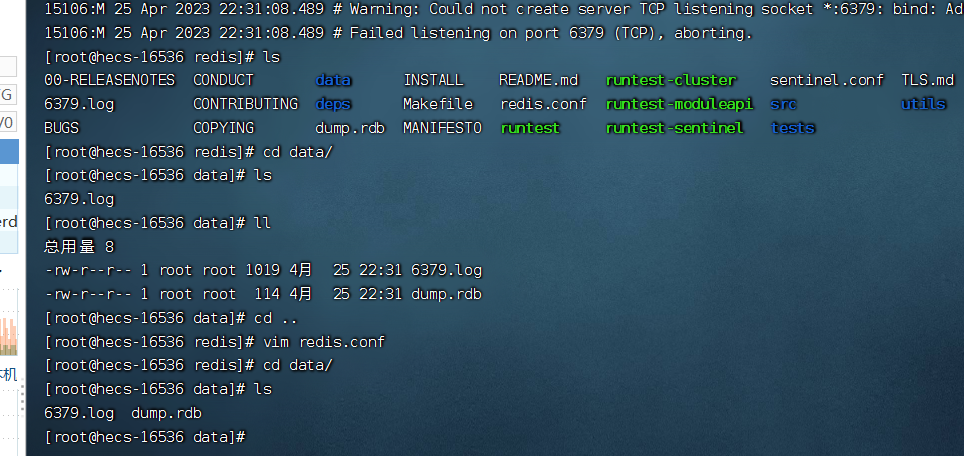
因为rdb文件,当你的redis服务意外宕掉,文件不会保存
aof是什么:客户端每写入一条命令,都记录一条日志,放到日志文件中,如果出现宕机,可以将数据完全恢复
AOF的三种策略
日志不是直接写到硬盘上,而是先放在缓冲区,缓冲区根据一些策略,写到硬盘上
always:redis-》写命令刷新的缓冲区-》每条命令fsync到硬盘--》AOF文件
everysec(默认值):redis---》写命令刷新的缓冲区--》每秒把缓冲区fsync到硬盘--》AOF文件
no: redis---》写命令刷新的缓冲区--》操作系统决定,缓冲区发sync到硬盘--》AOF文件
AOF重写配置参数
随着命令的逐渐写入,并发量的变大,AOF文件会越来越大,通过AOF重写来解决该问题
本质就是把过期的,无用的,重复的,可以优化的命令,来优化,这样可以减少磁盘占用量,加速恢复速度
AOF持久化的配置
auto-aof-rewrite-min-size: 500m
auto-aof-rewrite-percentage: 增长率
appendonly yes # 将该选项设置为yes 打开
appendfilename "appendonly.aof" # 文件保存的名字
appendfsync everusec # 采用第二种策略
no-appendfsync-on-rewrite res
# 在aof重写的时候,是否要做aof的append操作,因为aof重写消耗性能,磁盘消耗,正常aof写磁盘有一定的冲突,这段期间的数据,允许丢失。

混合持久化
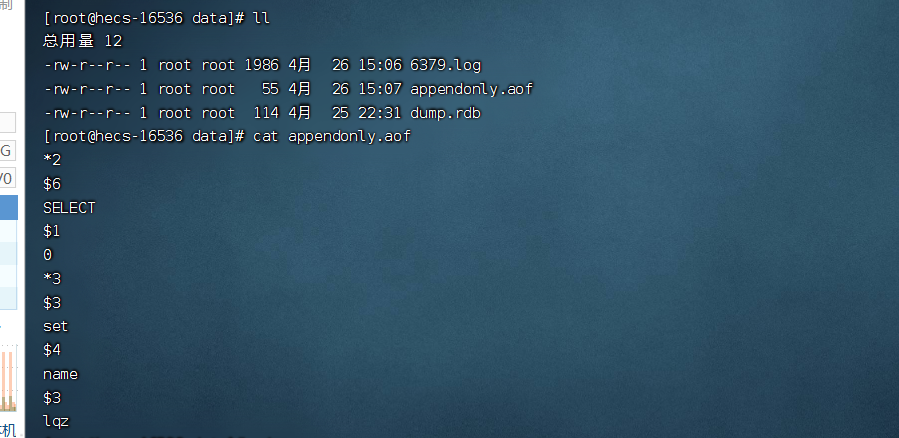
可以同时开启aof和rdb,他们是相互不影响的
redis4.x 以后 出现了混合持久化,其实就是aof+rdb,解决恢复速度问题
开启了混合持久化,AOF在重写时,不在是单纯将内存数据转换为RESP命令写入AOF文件,而是将重写这一刻之前的内存做RDB快照处理
配置参数:必须先开启AOF
开启 aof
appendonly yes
开启 aof重写
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
开启 混合持久化
aof-use-rdb-preamble yes # 这正有用是这句话
# 关闭 rdn
save "" # 什么都不写就关闭了
# aof重写可以使用配置文件触发,也可以手动触发:
bgrewriteaof
主从复制原理和方案
为什么需要主从
可能会有以下问题:
- 机器故障
- 容器瓶颈
- QPS瓶颈
主从解决了qps问题,机器故障问题
主从实现的功能
一主一从,一主多从
做读写分离
做数据副本
提高并发量
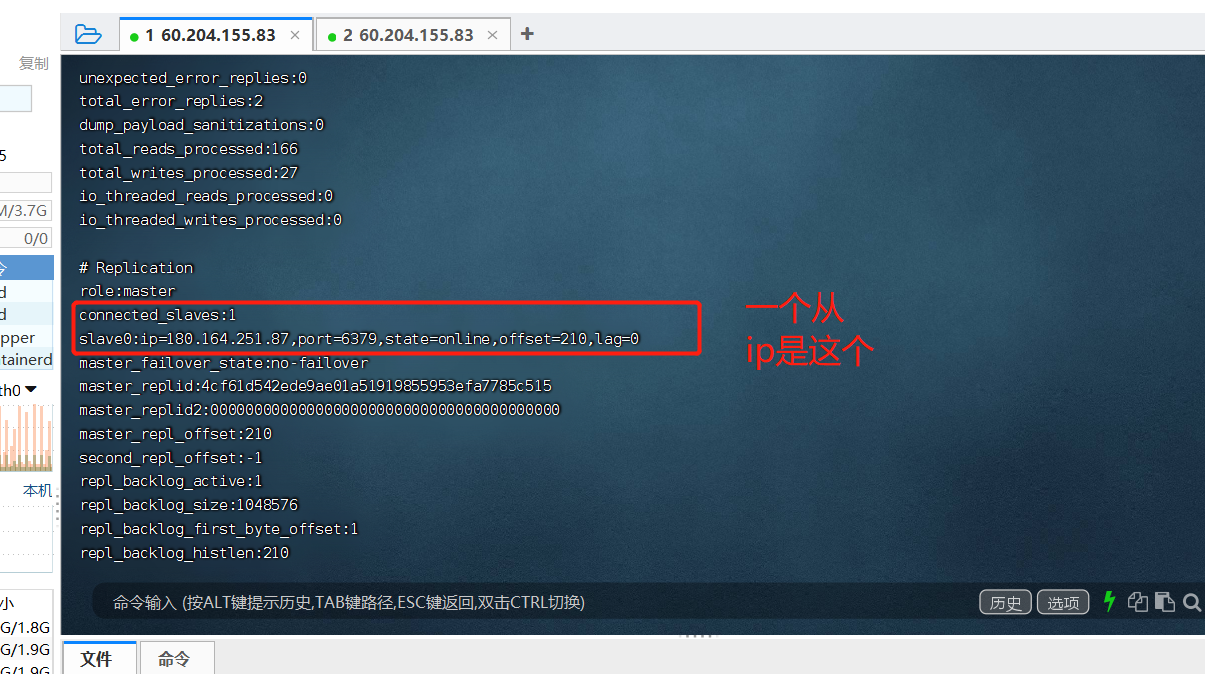
一个master可以有多个slave
一个slave只能有一个master
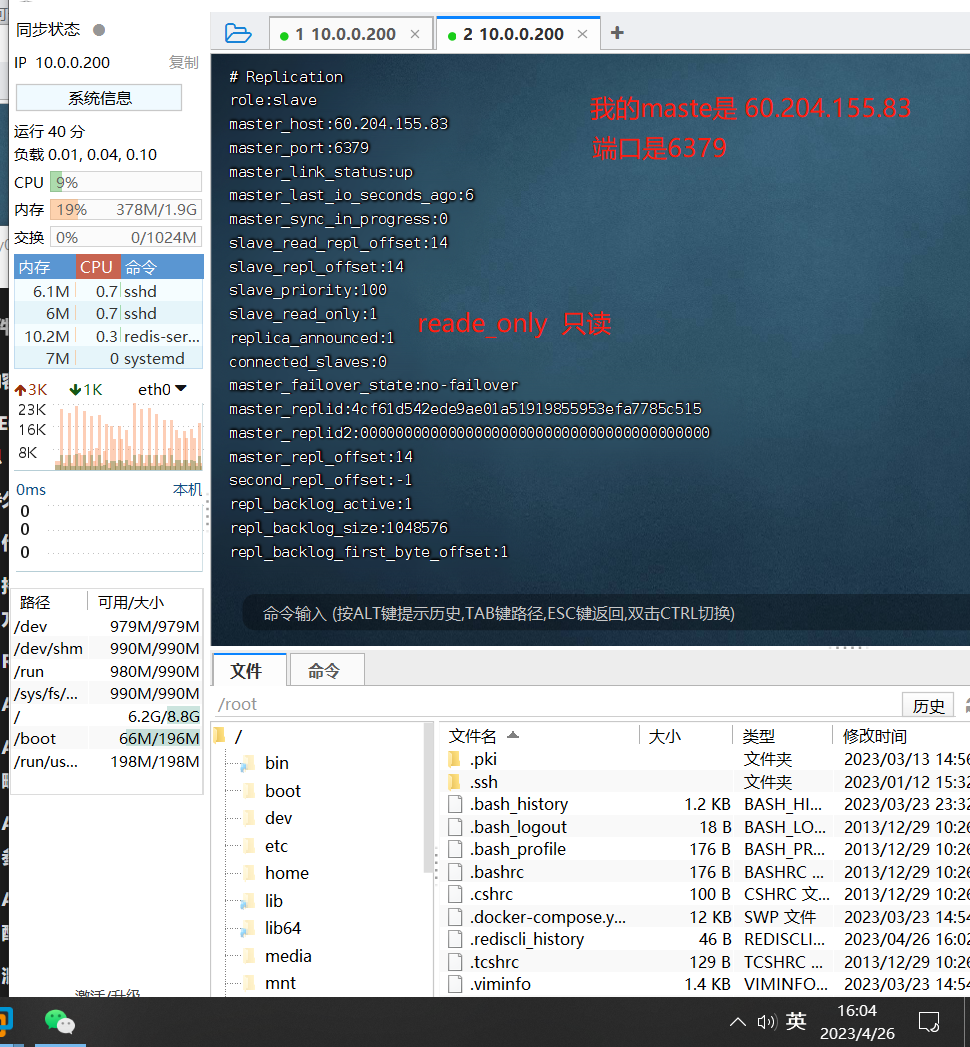
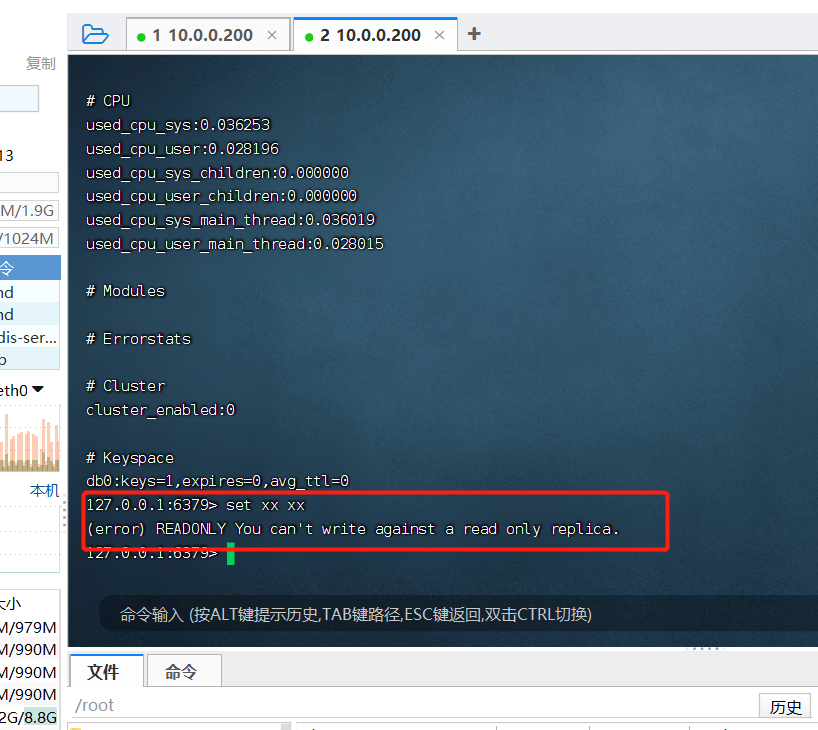
数据流向是单向的,从master到slave,从库只能读,不能写,主库既能读有能写
redis主从复制流程,原理
1. 副本(从)库通过slaveof 127.0.0.1 6379命令,连接主库,并发SYNC给主库
2.主库收到SYNC,会立即触发BGSAVE,后台保存RDB,发送给副本库
3.副本库接收后会应用RDB快照,load进内存
4.主库会陆续将中间产生的新的操作,保存并发送给副本库
5.到此,我们主从复制就可以正常工作了
6.再次以后,主库只要发生新的操作,都会以命令传播的形式自动发送给副本库
7.所有复制相关信息,从info信息中都可以查到,即使重启任何节点。他的主从关系依然都在
8.如果发生主从关系断开时,从库数据没有任何损坏,在下次重连之后,从库发送PSYNC给主库
9.主库只会将从库确实部分的数据同步给从库应用,达到快速恢复主从的目的
主从复制配置
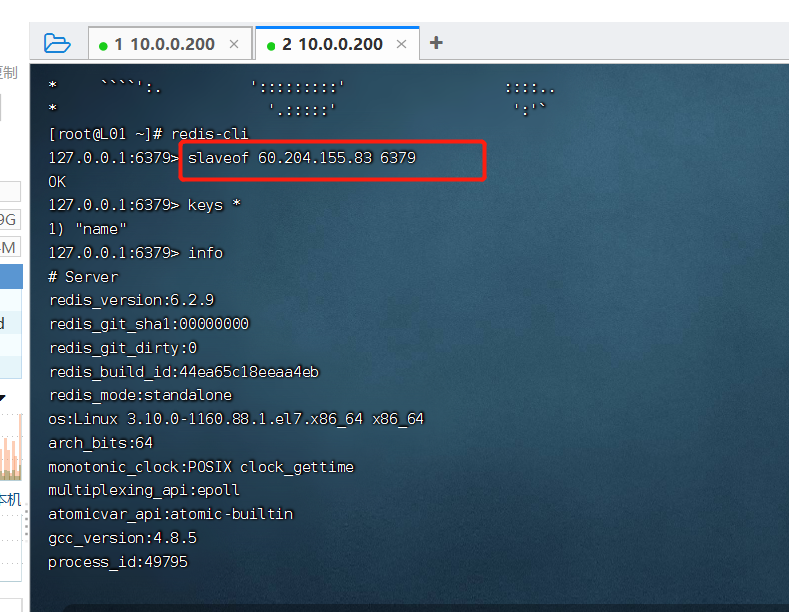
1. 命令方式,在从库上执行
slaveof 主机名 端口 # 异步
执行之后 从库据不能写了,以后只能用来读
slaveof no one # 从库:断开主从关系
2.配置文件方式,在从库加入
slaveof 主机名 端口
slaveof-read-only yes # 从节点只读,因为可读可写,数据会乱
辅助配置
min-slaves-to-write 1
min-slaves-max-lag 3
那么在从服务器的数量少于1个,或者三个从服务器的延迟(lag)
值都大于或等于3秒时。主服务将拒绝执行写命令
哨兵高可用
服务可用性高
主从复制不是高可用
主从存在问题
主从复制,主节点发生故障,需要做故障转移,可以手动转移:让其中一个slave变成mater---》哨兵
主从复制,只能主写数据,所以能以和存储能力有限--》集群
哨兵:Sentinel 实现高可用
工作原理
1.多个sentinel发现并确定master有问题
2.选举出一个sentinel作为领导
3.选取一个slave作为新的master
4.通知其余slave成为新的master的slave
5.通知客户端主从变化
6.等待老的master复活成为新master的slave
高可用搭建步骤
第一步:先搭建一主两从
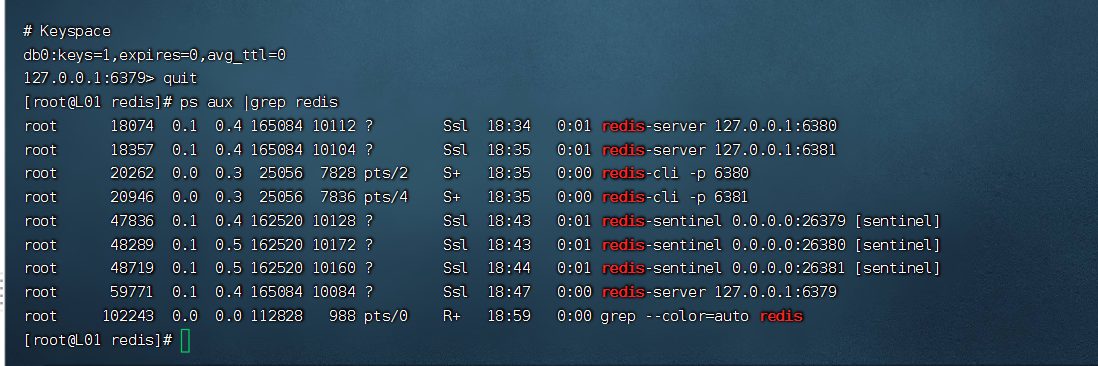
第二步:哨兵配置文件,启动哨兵(redis的进程,也要监听端口,启动进程有配置文件)
port 26379
daemonize yes
dir /usr/local/redis/data
bind 0.0.0.0
logfile "redis_sentinel.log"
sentinel monitor mymaster 127.0.0.1 6379 2 # 主的ip和端口 2是票数
sentinel down-after-milliseconds mymaster 30000 # 30000毫秒没有响应认为宕机
port 26380
daemonize yes
dir /usr/local/redis/data1
bind 0.0.0.0
logfile "redis_sentinel1.log"
sentinel monitor mymaster 127.0.0.1 6379 2 # 主的ip和端口 2是票数
sentinel down-after-milliseconds mymaster 30000 # 30000毫秒没有响应认为宕机
port 26381
daemonize yes
dir /usr/local/redis/data2
bind 0.0.0.0
logfile "redis_sentinel2.log"
sentinel monitor mymaster 127.0.0.1 6379 2 # 主的ip和端口 2是票数
sentinel down-after-milliseconds mymaster 30000 # 30000毫秒没有响应认为宕机
启动哨兵
redis-sentinel sentinel.conf
redis-sentinel sentinel1.conf
redis-sentinel sentinel2.conf
当master宕掉之后,哨兵会选举一个哨兵作为领头哨兵,然后由领头哨兵协调其他哨兵,最终选出一个健康的slave作为新的master。
在新的主服务器被选举后,老的的master就成为新的master的slave了

哨兵的日志文件



 浙公网安备 33010602011771号
浙公网安备 33010602011771号