

数据采集作业3
作业3
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
代码和结果:
代码
整体分为「配置层→工具函数层→核心爬取层→信号处理层」
(一)配置层:全局参数定义(常量配置法)
所用方法:硬编码常量配置 + 请求头模拟
点击查看代码
import os
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
import signal
# 配置参数
TARGET_URL = "http://www.weather.com.cn"
MAX_PAGES = 88
MAX_IMAGES = 108
IMAGE_DIR = "images"
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
# 全局变量
visited_links = set()
is_interrupted = False
collected_img_urls = set()
点击查看代码
def init_image_dir():
if not os.path.exists(IMAGE_DIR):
os.makedirs(IMAGE_DIR)
print(f" 图片存储目录:{os.path.abspath(IMAGE_DIR)}")
def get_valid_image_url(img_src):
if not img_src or is_interrupted:
return None
invalid_keywords = ["icon_16", "icon_24", "small_icon", "mini_icon"]
if any(kw in img_src.lower() for kw in invalid_keywords) and "gif" in img_src.lower():
return None
if img_src.startswith("//"):
return "http:" + img_src
elif img_src.startswith("/"):
return TARGET_URL + img_src
elif img_src.startswith("http"):
return img_src
return None
def download_image_with_retry(img_url, save_path, max_retries=3):
global is_interrupted
if is_interrupted:
print(f" 下载中断:{img_url}")
return False
for retry in range(max_retries):
try:
time.sleep(0.1)
response = requests.get(img_url, headers=HEADERS, timeout=15)
response.raise_for_status()
if not response.headers.get("Content-Type", "").startswith("image"):
return False
with open(save_path, "wb") as f:
f.write(response.content)
print(f" 下载成功:{img_url}")
return True
except KeyboardInterrupt:
is_interrupted = True
print(f" 下载被中断:{img_url}")
return False
except Exception:
if retry < max_retries - 1:
time.sleep(0.5)
else:
print(f" 下载失败:{img_url}")
return False
def crawl_page_for_data(url):
global is_interrupted
if is_interrupted or url in visited_links:
return [], []
visited_links.add(url)
img_urls = []
page_links = []
try:
print(f"\n 爬取页面:{url}")
response = requests.get(url, headers=HEADERS, timeout=20)
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, "html.parser")
img_tags = soup.find_all("img")
for img in img_tags:
if is_interrupted or len(collected_img_urls) >= MAX_IMAGES + 20:
break
img_sources = [img.get("src"), img.get("data-src"), img.get("srcset"), img.get("data-srcset")]
for src in img_sources:
if not src:
continue
if "," in src:
src = src.split(",")[0].strip().split(" ")[0]
img_url = get_valid_image_url(src)
if img_url and img_url not in collected_img_urls:
collected_img_urls.add(img_url)
img_urls.append(img_url)
if not is_interrupted:
for a in soup.find_all("a", href=True):
link = a["href"]
if link.startswith("/"):
link = TARGET_URL + link
if link.startswith(TARGET_URL) and link not in visited_links and link not in page_links:
page_links.append(link)
print(f" 页面爬取完成:{url} | 有效图片数:{len(img_urls)} | 新链接数:{len(page_links)}")
except KeyboardInterrupt:
is_interrupted = True
print(f" 页面爬取被中断:{url}")
except Exception as e:
print(f" 页面爬取失败:{url} | 错误:{str(e)[:30]}")
return img_urls, page_links
def handle_interrupt(signum, frame):
global is_interrupted
if not is_interrupted:
is_interrupted = True
print("\n\n 收到中断信号,正在退出...")
signal.signal(signal.SIGINT, handle_interrupt)
try:
signal.signal(signal.SIGTERM, handle_interrupt)
except AttributeError:
pass
点击查看代码
# 单线程爬取(修复冗余global声明)
def single_thread_crawl():
print("="*60)
print(" 开始单线程爬取")
print(f"目标网站:{TARGET_URL}")
print(f"限制:最多{MAX_PAGES}页 | 目标{MAX_IMAGES}张图片")
print("="*60)
init_image_dir()
global is_interrupted
visited_links.clear()
collected_img_urls.clear() # 操作集合元素
is_interrupted = False
link_queue = [TARGET_URL]
all_img_urls = []
page_count = 0
# 收集URL
while not is_interrupted and page_count < MAX_PAGES and len(collected_img_urls) < MAX_IMAGES + 20 and link_queue:
url = link_queue.pop(0)
img_urls, page_links = crawl_page_for_data(url)
for img_url in img_urls:
if len(all_img_urls) < MAX_IMAGES + 20 and img_url not in all_img_urls:
all_img_urls.append(img_url)
page_count += 1
link_queue.extend([link for link in page_links if link not in link_queue])
# 下载图片
print(f"\n 开始单线程下载图片(共{len(all_img_urls)}个URL)")
downloaded_count = 0
backup_idx = MAX_IMAGES
for i in range(min(MAX_IMAGES, len(all_img_urls))):
if is_interrupted or downloaded_count >= MAX_IMAGES:
break
img_url = all_img_urls[i]
filename = f"single_image_{i+1:03d}.jpg"
save_path = os.path.join(IMAGE_DIR, filename)
if download_image_with_retry(img_url, save_path):
downloaded_count += 1
else:
# 补下
if backup_idx < len(all_img_urls):
backup_url = all_img_urls[backup_idx]
print(f" 补下第{i+1}张:{backup_url}")
if download_image_with_retry(backup_url, save_path):
downloaded_count += 1
backup_idx += 1
# 统计
print("\n" + "="*60)
print(" 单线程爬取结束" if not is_interrupted else " 单线程爬取被中断")
print(f"实际爬取页数:{page_count}")
print(f"最终下载图片数:{downloaded_count}")
print("="*60)
点击查看代码
# 多线程爬取
def multi_thread_crawl(max_workers=12):
print("\n" + "="*60)
print(" 开始线程池多线程爬取")
print(f"目标网站:{TARGET_URL}")
print(f"限制:最多{MAX_PAGES}页 | 目标{MAX_IMAGES}张图片")
print(f"线程数:{max_workers}")
print("="*60)
init_image_dir()
global is_interrupted
visited_links.clear()
collected_img_urls.clear() # 操作集合元素,
is_interrupted = False
page_count = 0
all_img_urls = []
link_queue = [TARGET_URL]
# 收集URL
print("\n 开始多线程收集图片URL...")
with ThreadPoolExecutor(max_workers=max_workers) as page_executor:
while not is_interrupted and page_count < MAX_PAGES and len(collected_img_urls) < MAX_IMAGES + 20 and link_queue:
current_links = link_queue[:MAX_PAGES - page_count]
link_queue = link_queue[MAX_PAGES - page_count:]
future_to_link = {}
for link in current_links:
if is_interrupted:
break
future = page_executor.submit(crawl_page_for_data, link)
future_to_link[future] = link
for future in as_completed(future_to_link):
if is_interrupted or len(collected_img_urls) >= MAX_IMAGES + 20:
break
try:
img_urls, page_links = future.result()
for img_url in img_urls:
if len(all_img_urls) < MAX_IMAGES + 20 and img_url not in all_img_urls:
all_img_urls.append(img_url)
link_queue.extend([link for link in page_links if link not in visited_links and link not in link_queue])
page_count += 1
except Exception:
pass
# 下载图片
print(f"\n 开始多线程下载图片(共{len(all_img_urls)}个URL)")
downloaded_count = 0
failed_indices = []
future_to_info = {}
with ThreadPoolExecutor(max_workers=max_workers) as download_executor:
for i in range(min(MAX_IMAGES, len(all_img_urls))):
if is_interrupted:
break
img_url = all_img_urls[i]
filename = f"multi_image_{i+1:03d}.jpg"
save_path = os.path.join(IMAGE_DIR, filename)
future = download_executor.submit(download_image_with_retry, img_url, save_path)
future_to_info[future] = (i+1, save_path)
for future in as_completed(future_to_info):
if is_interrupted:
break
img_idx, save_path = future_to_info[future]
try:
if future.result():
downloaded_count += 1
else:
failed_indices.append((img_idx, save_path))
except Exception:
failed_indices.append((img_idx, save_path))
# 补下失败图片
backup_idx = MAX_IMAGES
with ThreadPoolExecutor(max_workers=max_workers//2) as retry_executor:
future_to_backup = {}
for img_idx, save_path in failed_indices:
if is_interrupted or downloaded_count >= MAX_IMAGES or backup_idx >= len(all_img_urls):
break
backup_url = all_img_urls[backup_idx]
future = retry_executor.submit(download_image_with_retry, backup_url, save_path)
future_to_backup[future] = img_idx
backup_idx += 1
for future in as_completed(future_to_backup):
if is_interrupted or downloaded_count >= MAX_IMAGES:
break
try:
if future.result():
downloaded_count += 1
except Exception:
pass
# 统计
print("\n" + "="*60)
print(" 多线程爬取结束" if not is_interrupted else " 多线程爬取被中断")
print(f"实际爬取页数:{page_count}")
print(f"最终下载图片数:{downloaded_count}")
print("="*60)
点击查看代码
if __name__ == "__main__":
# 二选一运行
single_thread_crawl()
#multi_thread_crawl(max_workers=12)


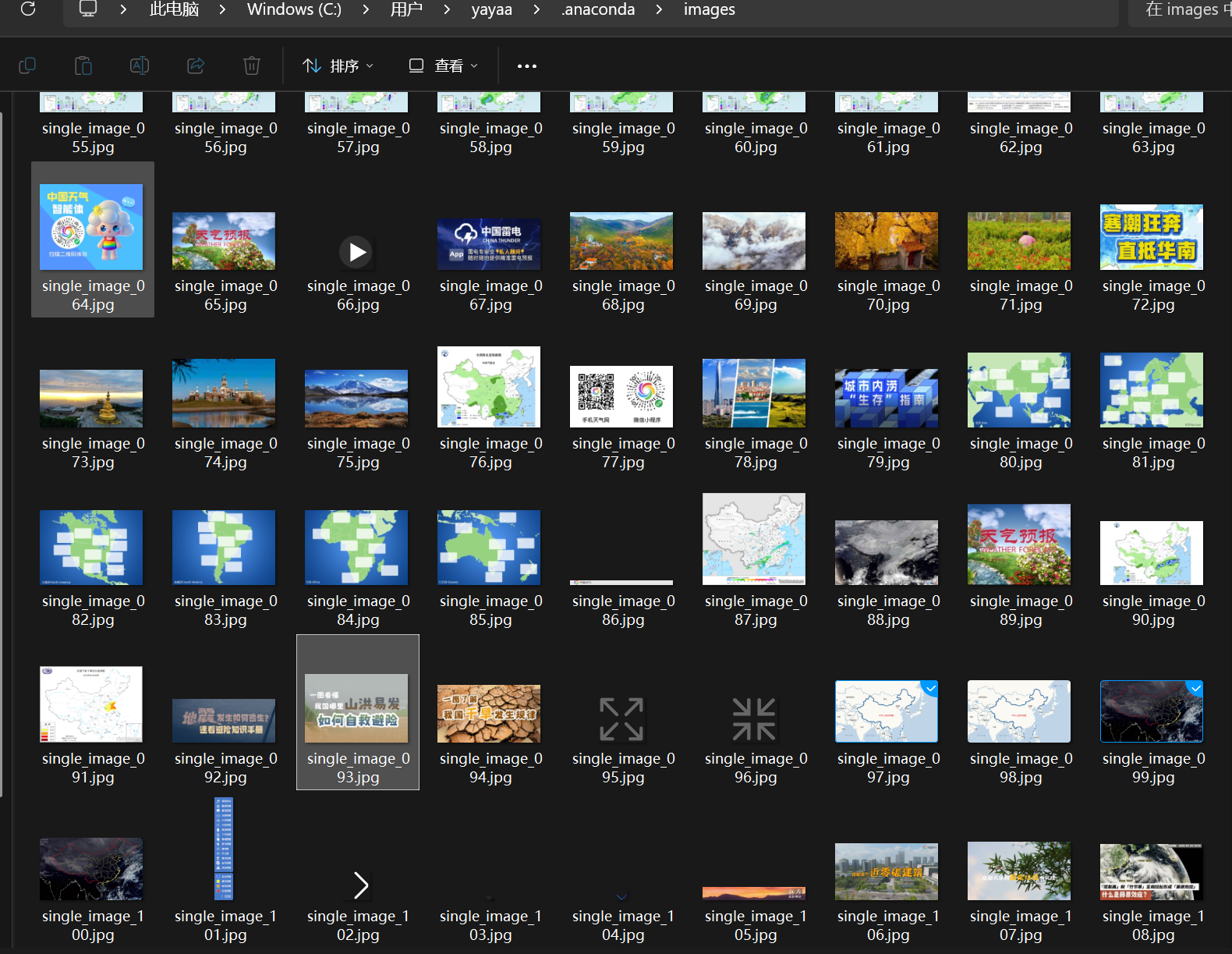
实验心得
通过实验,感受到单线程和多线程的核心差异——单线程虽然执行慢,但逻辑简单、不用考虑并发问题,对网站反爬压力也小,适合测试或反爬严格的场景;而多线程靠线程池实现并发,爬取和下载效率提升特别明显,尤其是处理多个任务时,能把整体时间大幅缩短,但得控制好线程数,不然容易给服务器带来过大压力,还得注意用全局变量做去重和状态同步,避免重复爬取或冲突。这次实验也让我明白,根据实际需求选对执行方式才是关键,单线程胜在稳定,多线程赢在效率,合理搭配就能既保证任务完成度,又兼顾执行效果。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
代码和结果
代码:
我们建立一个scapy项目
1.结构如下
stock_spider_project/ # 项目根目录
├── stock_spider/ # 爬虫核心目录
│ ├── stock_spider/ # 项目配置目录
│ │ ├── init.py
│ │ ├── items.py # 数据模型定义
│ │ ├── middlewares.py # 中间件
│ │ ├── pipelines.py # 数据存储管道
│ │ ├── settings.py # 项目配置
│ │ └── spiders/ # 爬虫脚本目录
│ │ ├── init.py
│ │ └── stock_spider.py# 爬虫核心脚本
│ └── scrapy.cfg # Scrapy 配置文件
├── stock.db # 数据库文件
└── query_stock.py # 数据查询脚本
2. items.py(数据模型定义)
定义爬取数据的字段,与数据库表字段一一对应
点击查看代码
import scrapy
class StockItem(scrapy.Item):
# MySQL自增主键(无需手动赋值)
id = scrapy.Field()
# 股票代码
stock_code = scrapy.Field()
# 股票名称
stock_name = scrapy.Field()
# 最新报价
latest_price = scrapy.Field()
# 涨跌幅(%)
price_change_rate = scrapy.Field()
# 涨跌额
price_change_amount = scrapy.Field()
# 成交量(手)
volume = scrapy.Field()
# 成交额(万元)
turnover = scrapy.Field()
# 振幅(%)
amplitude = scrapy.Field()
# 最高
highest_price = scrapy.Field()
# 最低
lowest_price = scrapy.Field()
# 今开
opening_price = scrapy.Field()
# 昨收
previous_close = scrapy.Field()
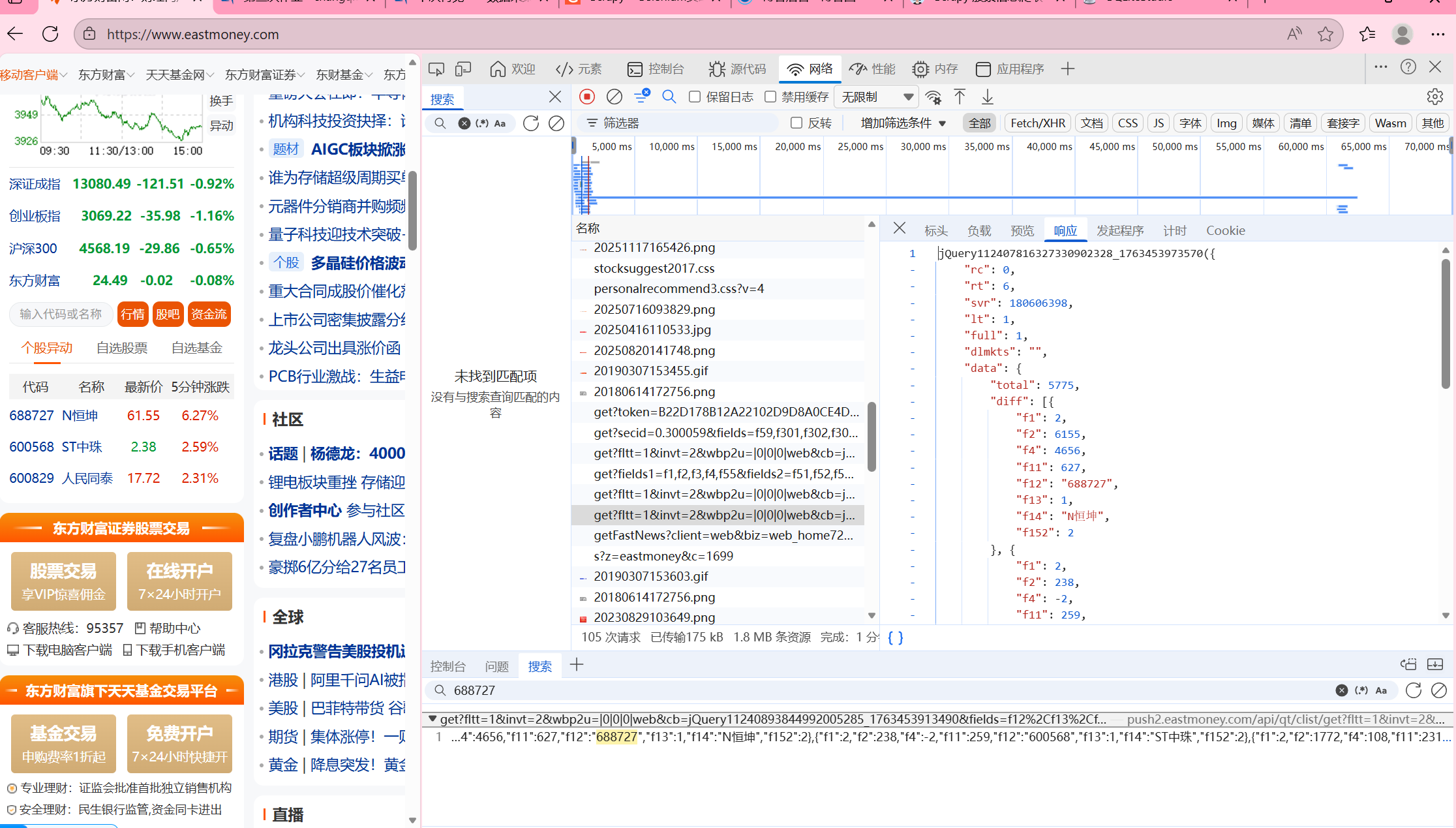
因为我们发现目标网站时js动态加载的,所以我们找到后端提供数据的 AJAX 接口,直接请求接口获取 JSON 数据,再通过 XPath 选择器解析网页 HTML 结构,提取股票相关字段
参数通过抓包分析可得
点击查看代码
import scrapy
import json
from stock_spider.items import StockItem
from urllib.parse import urlencode # 用于手动拼接URL参数
class EastMoneySpider(scrapy.Spider):
name = 'eastmoney'
allowed_domains = ['eastmoney.com']
# 后端AJAX接口
base_url = 'https://push2.eastmoney.com/api/qt/clist/get'
def start_requests(self):
# 从第1页开始爬取,每页50条数据
yield self.build_ajax_request(pn=1)
def build_ajax_request(self, pn):
""构造AJAX请求手动拼接参数)""
params = {
'pn': pn, # 页码
'pz': 50, # 每页条数
'po': 1, # 排序方向
'np': 1, # 固定参数
'ut': 'bd1d9ddb04089700cf9c27f6f7426281',
'fltt': 2, # 过滤条件
'invt': 2, # 固定参数
'fid': 'f3', # 排序字段(涨跌幅)
'fs': 'm:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048', # A股全量
'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f11,f12,f13,f14,f15,f16,f17,f18',
'_': 1755600000000 + pn, # 时间戳(防缓存)
}
# 手动拼接URL参数(兼容旧版Scrapy)
url_with_params = self.base_url + '?' + urlencode(params)
return scrapy.Request(
url=url_with_params,
method='GET',
callback=self.parse_ajax_data,
meta={'current_pn': pn} # 传递当前页码
)
def parse_ajax_data(self, response):
"""解析AJAX返回的JSON数据"""
try:
# 解析JSON响应
result = json.loads(response.text)
# 接口返回rc=0表示成功
if result.get('rc') != 0:
self.logger.error(f"接口请求失败:页码{response.meta['current_pn']},错误信息:{result.get('msg')}")
return
# 获取股票列表(核心数据在 data.diff 中)
stock_list = result.get('data', {}).get('diff', [])
if not stock_list:
self.logger.info("已爬取完所有股票数据!")
return
# 遍历解析每只股票
for stock in stock_list:
item = StockItem()
# 字段映射(接口加密字段 → 目标字段)
item['stock_code'] = str(stock.get('f12', '')) # 股票代码
item['stock_name'] = stock.get('f14', '') # 股票名称
item['latest_price'] = stock.get('f2', 0) # 最新报价
item['price_change_rate'] = stock.get('f3', 0) # 涨跌幅(%)
item['price_change_amount'] = stock.get('f4', 0)# 涨跌额
item['volume'] = stock.get('f5', 0) # 成交量(手)
item['turnover'] = stock.get('f6', 0) # 成交额(万元)
item['amplitude'] = stock.get('f7', 0) # 振幅(%)
item['highest_price'] = stock.get('f15', 0) # 最高
item['lowest_price'] = stock.get('f16', 0) # 最低
item['opening_price'] = stock.get('f17', 0) # 今开
item['previous_close'] = stock.get('f18', 0) # 昨收
item['id'] = '' # id由SQLite自增,留空
yield item # 提交到Pipeline存储
# 爬取下一页
current_pn = response.meta['current_pn']
next_pn = current_pn + 1
self.logger.info(f"已完成第{current_pn}页爬取,准备爬取第{next_pn}页...")
yield self.build_ajax_request(pn=next_pn)
except json.JSONDecodeError:
self.logger.error(f"JSON解析失败:页码{response.meta['current_pn']}")
except Exception as e:
self.logger.error(f"解析数据失败:{str(e)},页码{response.meta['current_pn']}")
点击查看代码
import sqlite3
from scrapy.exceptions import DropItem
import os
class StockSqlitePipeline:
"""使用SQLite存储(Python自带,无需安装,生成本地.db文件)"""
def __init__(self):
# 数据库文件路径(项目根目录下生成 stock.db)
self.db_path = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(__file__))), 'stock.db')
self.conn = None
self.cursor = None
# 爬虫启动时:连接SQLite + 创建表
def open_spider(self, spider):
try:
# 连接SQLite(文件不存在则自动创建)
self.conn = sqlite3.connect(self.db_path)
self.cursor = self.conn.cursor()
spider.logger.info(f"SQLite数据库连接成功!文件路径:{self.db_path}")
# 创建股票表(传入spider参数,用于日志打印)
self.create_stock_table(spider)
except Exception as e:
spider.logger.error(f"SQLite连接失败:{str(e)}")
raise e
# 创建股票表(接收spider参数,用于日志)
def create_stock_table(self, spider):
create_sql = """
CREATE TABLE IF NOT EXISTS stock_info (
id INTEGER PRIMARY KEY AUTOINCREMENT,
stock_code TEXT NOT NULL,
stock_name TEXT NOT NULL,
latest_price REAL,
price_change_rate REAL,
price_change_amount REAL,
volume INTEGER,
turnover REAL,
amplitude REAL,
highest_price REAL,
lowest_price REAL,
opening_price REAL,
previous_close REAL,
UNIQUE (stock_code)
);
"""
try:
self.cursor.execute(create_sql)
self.conn.commit()
# 用spider的logger打印日志(正确用法)
spider.logger.info("股票表创建成功(或已存在)!")
except Exception as e:
self.conn.rollback()
raise DropItem(f"创建股票表失败:{str(e)}")
# 处理数据并插入SQLite
def process_item(self, item, spider):
# 数据序列化:处理空值
def serialize_val(value):
return value if value != 0 and value is not None else None
# 插入/更新SQL(SQLite的UPSERT语法)
insert_sql = """
INSERT OR REPLACE INTO stock_info (
stock_code, stock_name, latest_price, price_change_rate, price_change_amount,
volume, turnover, amplitude, highest_price, lowest_price, opening_price, previous_close
) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?);
"""
# 组装数据
data = [
serialize_val(item['stock_code']),
serialize_val(item['stock_name']),
serialize_val(item['latest_price']),
serialize_val(item['price_change_rate']),
serialize_val(item['price_change_amount']),
serialize_val(item['volume']),
serialize_val(item['turnover']),
serialize_val(item['amplitude']),
serialize_val(item['highest_price']),
serialize_val(item['lowest_price']),
serialize_val(item['opening_price']),
serialize_val(item['previous_close'])
]
# 数据校验
if not data[0] or not data[1]:
raise DropItem(f"无效数据:{item}")
# 执行插入
try:
self.cursor.execute(insert_sql, data)
self.conn.commit()
spider.logger.info(f"成功存储股票:{data[0]} {data[1]}")
except Exception as e:
self.conn.rollback()
raise DropItem(f"存储数据失败:{str(e)} | 数据:{item}")
return item
# 爬虫关闭时关闭连接
def close_spider(self, spider):
if self.cursor:
self.cursor.close()
if self.conn:
self.conn.close()
spider.logger.info(f"SQLite数据库已关闭!文件保存路径:{self.db_path}")
点击查看代码
BOT_NAME = "stock_spider"
SPIDER_MODULES = ["stock_spider.spiders"]
NEWSPIDER_MODULE = "stock_spider.spiders"
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1.5 # 延长延迟,防封IP
DEFAULT_REQUEST_HEADERS = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Referer": "https://quote.eastmoney.com/",
"X-Requested-With": "XMLHttpRequest",
}
# Configure item pipelines(启用SQLite存储)
ITEM_PIPELINES = {
"stock_spider.pipelines.StockSqlitePipeline": 300,
}
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
# 日志配置
LOG_LEVEL = "INFO"
LOG_FILE = "stock_spider.log"
LOG_ENCODING = "utf-8"
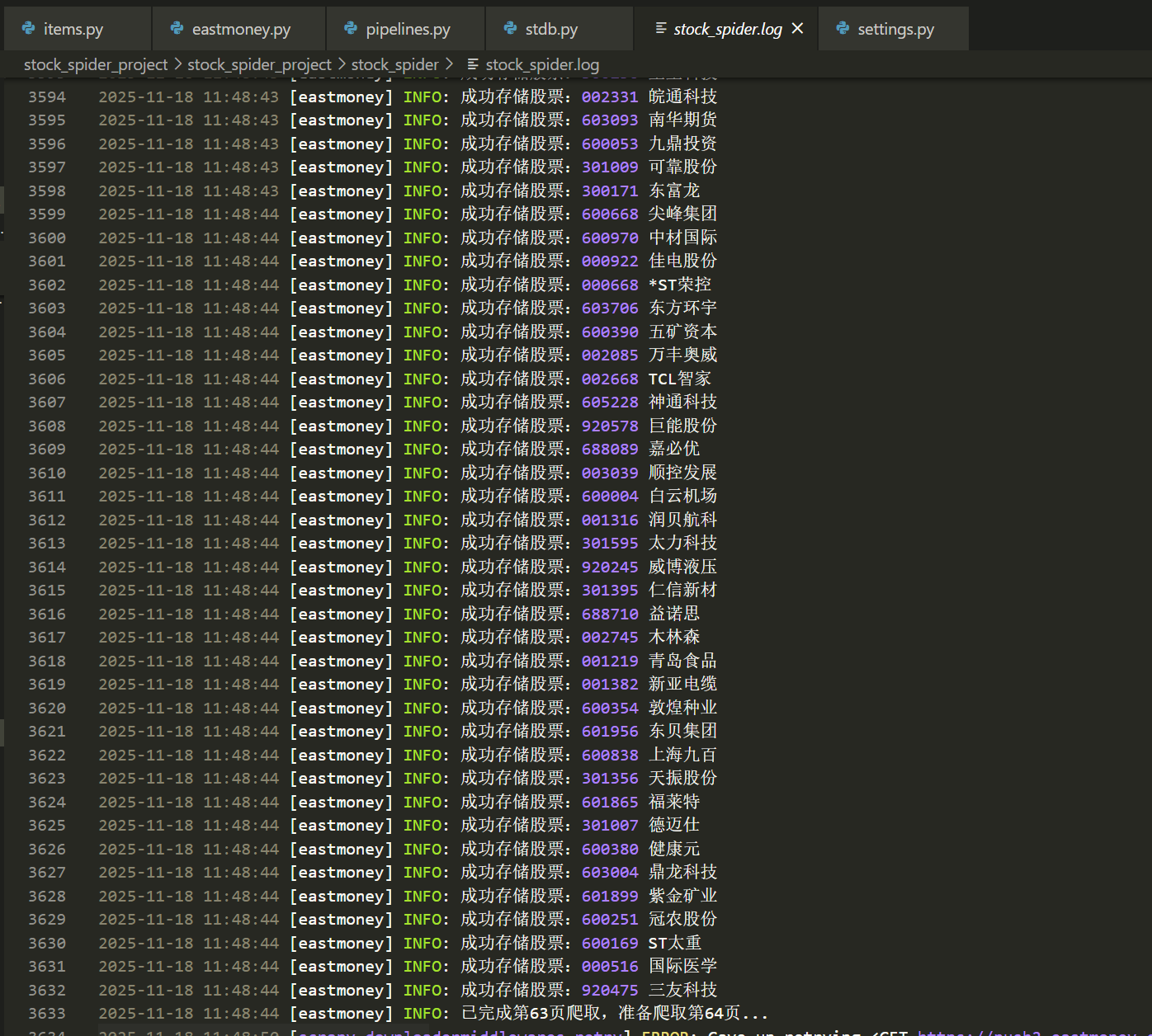
我们读取数据库文件控制台输出查询结果
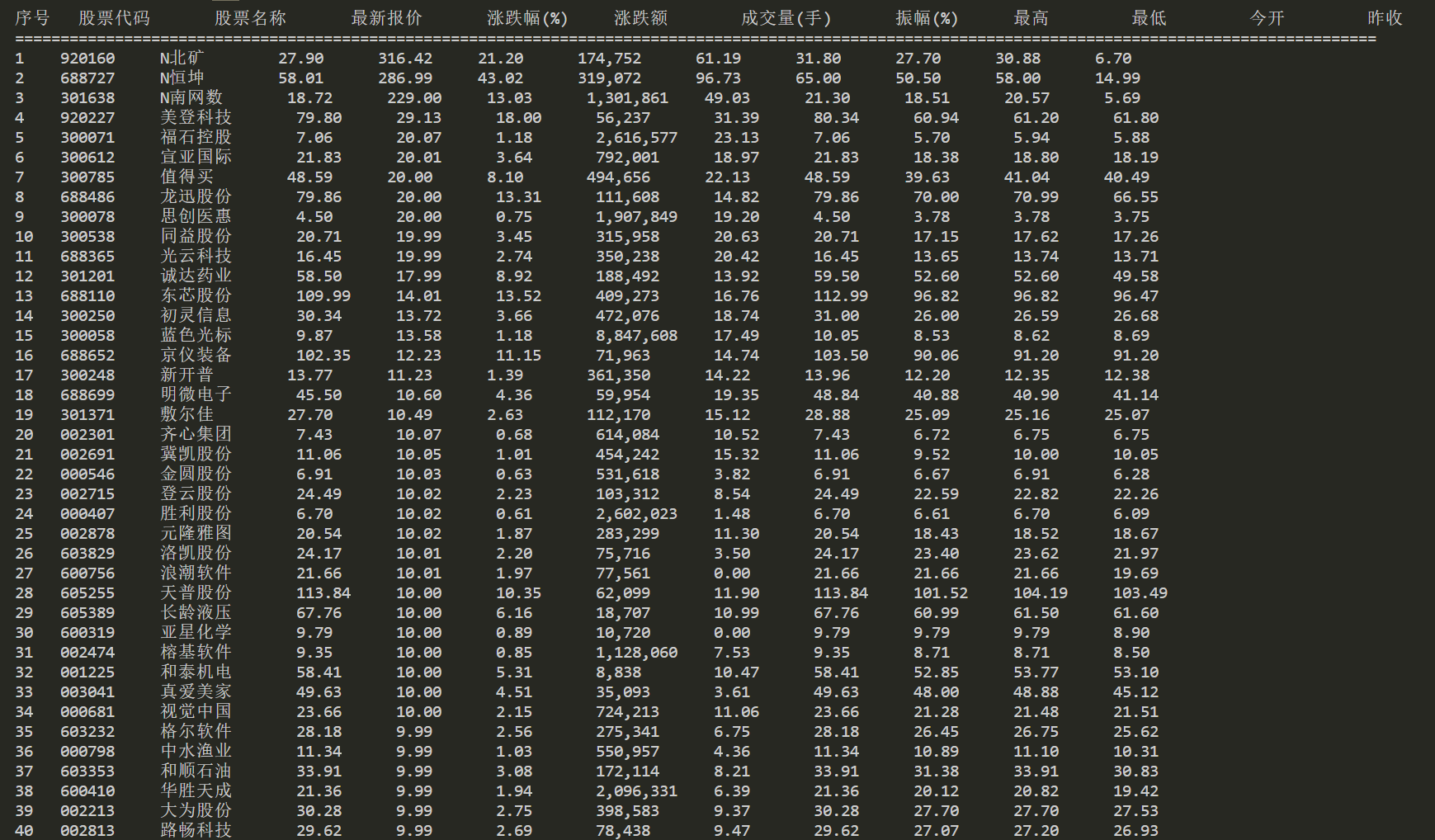
实验心得
股票数据爬取的核心心得:初期数据藏在 <div class="stock-list"> 下的嵌套 <li> 标签里,我们XPath写得宽泛(比如直接用 //li/text()),不仅定位混乱,还总漏抓“成交量”字段。后来精准锁定数据容器 <ul class="stock-data">,改用 ./li[@data-field="price"]/text()、./li[@data-field="volume"]/text() 这类带属性的选择器,直接提取价格、成交量;对动态加载的“实时涨跌幅”,通过浏览器网络请求找到了 /api/stock/realtime 接口,从返回的JSON里直接取 change_rate 字段。这让我明确,数据提取必须先找准具体的容器标签或真实接口,再用精准选择器,才能不丢数据、不抓错数据。
作业③
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
代码和结果
代码:
1 项目结构设计
forex_spider/ # 项目根目录
├── forex_spider/ # 核心代码目录
│ ├── init.py # 包初始化文件
│ ├── items.py # 数据模型定义(字段约束)
│ ├── middlewares.py # 中间件(默认启用,处理请求/响应)
│ ├── pipelines.py # 数据存储管道(SQLite 交互)
│ ├── settings.py # 项目配置(爬虫参数、管道启用等)
│ └── spiders/ # 爬虫脚本目录
│ ├── init.py
│ └── boc_forex.py # 核心爬虫脚本
├── forex.db # 自动生成的 SQLite 数据库文件
├── fordb.py # 数据查询脚本
└── scrapy.cfg # Scrapy 项目配置文件
2 数据模型定义(items.py)
这里我们查看网站的信息,编写对应字段

每个字段通过scrapy.Field()定义,Scrapy 会自动对字段进行类型校验和数据传递
点击查看代码
import scrapy
class ForexSpiderItem(scrapy.Item):
currency = scrapy.Field() # 货币名称
tbp = scrapy.Field() # 现汇买入价(TBP)
cbp = scrapy.Field() # 现钞买入价(CBP)
tsp = scrapy.Field() # 现汇卖出价(TSP)
csp = scrapy.Field() # 现钞卖出价(CSP)
time = scrapy.Field() # 发布时间
- 数据存储管道(pipelines.py)
点击查看代码
import sqlite3 # Python 内置模块,无需安装
from scrapy.exceptions import DropItem
class ForexSqlitePipeline:
"""外汇数据 SQLite 存储管道(Python 自带数据库,零依赖)"""
def open_spider(self, spider):
"""爬虫启动时:连接数据库+创建数据表"""
# SQLite 数据库文件路径(项目根目录下生成 forex.db)
self.db_path = 'forex.db'
# 连接数据库(文件不存在则自动创建)
self.conn = sqlite3.connect(self.db_path)
self.cursor = self.conn.cursor()
spider.logger.info(f"SQLite 数据库连接成功!文件路径:{self.db_path}")
# 自动创建数据表(若不存在)
self.create_forex_table()
def create_forex_table(self):
"""创建数据表:字段与 Item 一一对应,定义约束(SQLite 兼容语法)"""
# 修复:SQLite 不支持 # 注释,改用 -- 单行注释
create_sql = """
CREATE TABLE IF NOT EXISTS forex_rates (
id INTEGER PRIMARY KEY AUTOINCREMENT, -- 自增主键
currency TEXT NOT NULL, -- 货币名称
tbp REAL, -- 现汇买入价(TBP)
cbp REAL, -- 现钞买入价(CBP)
tsp REAL, -- 现汇卖出价(TSP)
csp REAL, -- 现钞卖出价(CSP)
time TEXT, -- 发布时间
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 入库时间
UNIQUE (currency, time) -- 唯一约束:避免同一货币同一时间重复存储
)
"""
try:
self.cursor.execute(create_sql)
self.conn.commit()
print("外汇数据表创建成功(或已存在)")
except sqlite3.Error as e:
self.conn.rollback()
raise DropItem(f"创建数据表失败:{e}")
def process_item(self, item, spider):
"""处理每条 Item 数据,序列化写入 SQLite"""
try:
# 处理空值:网页中"-"转为 None
tbp_val = float(item['tbp']) if item['tbp'] != '-' else None
cbp_val = float(item['cbp']) if item['cbp'] != '-' else None
tsp_val = float(item['tsp']) if item['tsp'] != '-' else None
csp_val = float(item['csp']) if item['csp'] != '-' else None
# 插入数据(INSERT OR REPLACE 处理重复数据)
insert_sql = """
INSERT OR REPLACE INTO forex_rates
(currency, tbp, cbp, tsp, csp, time)
VALUES (?, ?, ?, ?, ?, ?)
"""
self.cursor.execute(insert_sql, (
item['currency'],
tbp_val,
cbp_val,
tsp_val,
csp_val,
item['time']
))
self.conn.commit() # 提交事务,确保数据写入
spider.logger.info(f"成功写入数据:{item['currency']} {item['time']}")
except sqlite3.Error as e:
self.conn.rollback()
spider.logger.error(f"数据写入失败:{e} | 数据:{item}")
raise DropItem(f"数据写入失败:{e}")
return item
def close_spider(self, spider):
"""爬虫结束时关闭数据库连接"""
self.cursor.close()
self.conn.close()
spider.logger.info("SQLite 数据库连接已关闭!")
点击查看代码
# Scrapy 项目基础配置
BOT_NAME = 'forex_spider'
SPIDER_MODULES = ['forex_spider.spiders']
NEWSPIDER_MODULE = 'forex_spider.spiders'
ROBOTSTXT_OBEY = False
# 启用 SQLite 存储 Pipeline(优先级 300)
ITEM_PIPELINES = {
'forex_spider.pipelines.ForexSqlitePipeline': 300,
}
# 下载延迟(反爬策略:每次请求间隔 1 秒)
DOWNLOAD_DELAY = 1
# 日志级别(仅显示关键信息)
LOG_LEVEL = 'INFO'
# 模拟浏览器请求头(反爬)
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
}
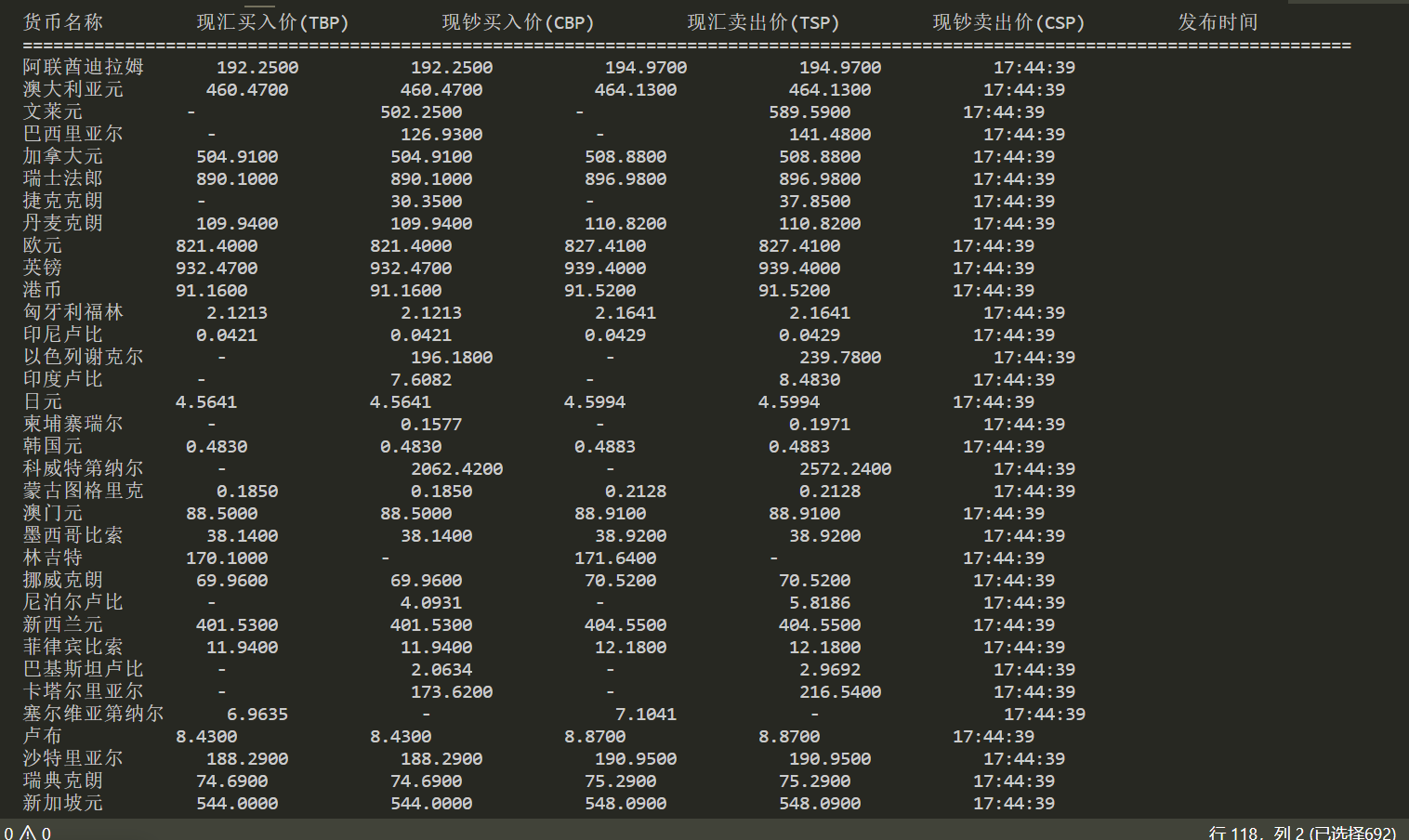
完整数据储存在数据库中
实验心得
本次实验基于Scrapy框架与SQLite数据库,核心通过表头文本反向定位表格的适配方案,解决了网页结构变化导致的XPath定位难题,同时设计空值处理、类型转换等异常机制,保障数据完整性。
初期因依赖固定属性定位网页元素遭遇瓶颈,后续通过优化定位逻辑成功适配网页结构,明白了爬虫的时候可以通过页面细化或者放宽条件查询到数据。
码云地址:
https://gitee.com/yaya-xuan/zyx_project/tree/master/%E6%95%B0%E6%8D%AE%E9%87%87%E9%9B%86/%E4%BD%9C%E4%B8%9A3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号