
【Python】时间序列分析完整过程
1. 导言
1.1 基本定义
根据维基百科上对时间序列的定义,我们简单将其理解为:
时间序列:一系列以时间顺序作为索引的数据点的集合。
因此,时间序列中的数据点,是围绕着相对确定的时间戳组织在一起的,与随机样本相比,它们包含了一些我们待提取的其他信息。
咱们先来看看,对时间序列数据分析,需要用到哪些库吧 ~
import numpy as np # 向量和矩阵运算
import pandas as pd # 表格与数据处理
import matplotlib.pyplot as plt # 绘图
import seaborn as sns # 更多绘图功能
sns.set()
from dateutil.relativedelta import relativedelta # 日期数据处理
from scipy.optimize import minimize # 优化函数
import statsmodels.formula.api as smf # 数理统计
import statsmodels.tsa.api as smt
import statsmodels.api as sm
import scipy.stats as scs
from itertools import product # 一些有用的函数
from tqdm import tqdm_notebook
import warnings # 勿扰模式
warnings.filterwarnings('ignore'
作为例子,本文以真实手游数据为例,来看一下我们玩家每小时观看的广告量和每天的游戏币消费情况 这两个时间序列数据:
ads = pd.read_csv('../../data/ads.csv', index_col=['Time'], parse_dates=['Time'])
currency = pd.read_csv('../../data/currency.csv', index_col=['Time'], parse_dates=['Time'])
plt.figure(figsize=(15, 7))
plt.plot(ads.Ads)
plt.title('Ads watched (hourly data)')
plt.grid(True)
plt.show()
plt.figure(figsize=(15, 7))
plt.plot(currency.GEMS_GEMS_SPENT)
plt.title('In-game currency spent (daily data)')
plt.grid(True)
plt.show()
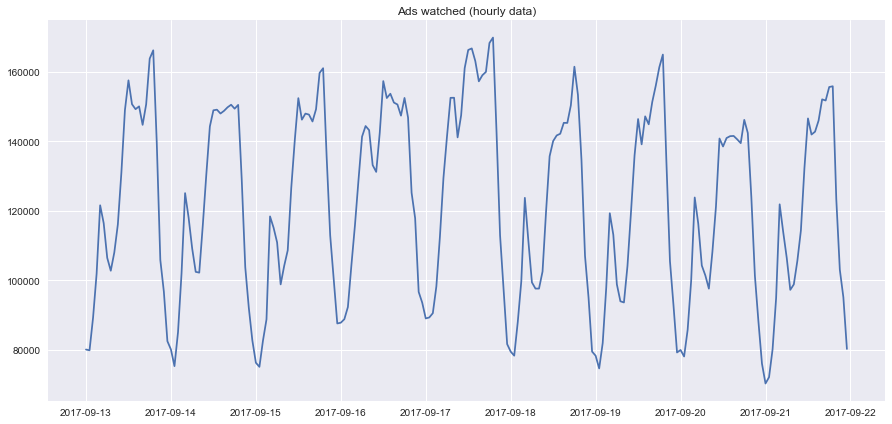
- 玩家在2017-09-13到2017-09-22这十天内,每小时广告阅读量的折线图:
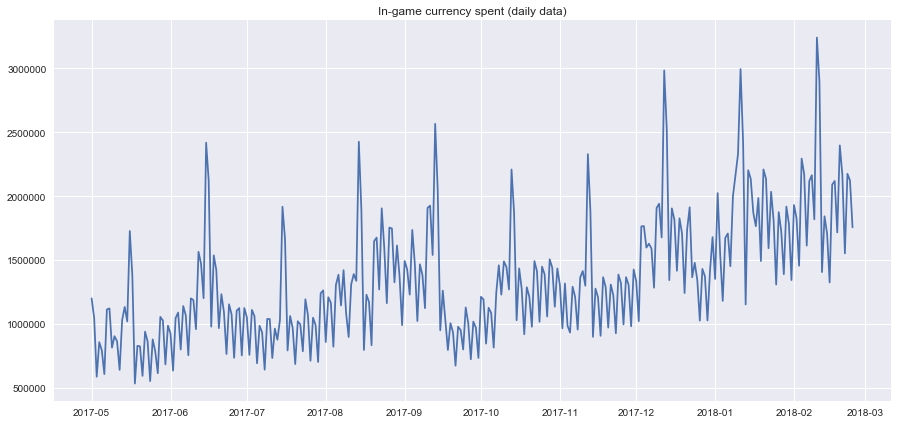
- 玩家在2017-05到2018-03这十一个月内,每天游戏币消费的折线图:
1.2 预测评估指标
在我们开始预测时间序列数据之前,先来了解一些比较流行的模型评估指标。
- R squared:R 2 R^2R2 分数,表示确定系数(在计量经济学中,它可以理解为描述模型方差的百分比),描述模型的泛化能力,取值区间 ( − i n f , 1 ] (-inf, 1](−inf,1],值为1时模型的性能最好;
sklearn.metrics.r2_score - Mean Absolute Error:平均绝对值损失,一种预测值与真实值之间的度量标准,也称作 l 1 l_1l1-norm 损失,取值区间 [ 0 , + i n f ) [0,+inf)[0,+inf);
sklearn.metrics.mean_absolute_error - Median Absolute Error:绝对值损失的中位数,抗干扰能力强,对于有异常点的数据集的鲁棒性比较好,取值区间 [ 0 , + i n f ) [0,+inf)[0,+inf);
sklearn.metrics.median_absolute_error - Mean Squared Error:均方差损失,常用的损失度量函数之一,对于真实值与预测值偏差较大的样本点给予更高(平方)的惩罚,反之亦然,取值区间 [ 0 , + i n f ) [0,+inf)[0,+inf);
sklearn.metrics.mean_squared_error - Mean squared logarithmic error:均方对数误差,定义形式特别像上面提的MSE,只是计算的是真实值的自然对数与预测值的自然对数之差的平方,通常适用于 target 有指数的趋势时,取值区间 [ 0 , + i n f ) [0,+inf)[0,+inf);
sklearn.metrics.mean_squared_log_error - Mean Absolute Percentage Error:作用和MAE一样,只不过是以百分比的形式,用来解释模型的质量,但是在sklearn的库中,没有提供这个函数的接口,取值区间 [ 0 , + i n f ) [0, +inf)[0,+inf);
导入上面提到的损失度量函数:
from sklearn.metrics import r2_score, median_absolute_error, mean_absolute_error
from sklearn.metrics import median_absolute_error, mean_squared_error, mean_squared_log_error
def mean_absolute_percentage_error(y_true, y_pred):
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
2. 移动、平滑、评估
2.1 滑动窗口估计
在开始学习时序预测之前,我们得先做一个基本的假设,即 “明天将和今天一样” ,但是并不是用类似 y ^ t = y t − 1 \hat{y}_{t}=y_{t-1}y^t=yt−1 的形式(虽然说这种方式可以作为一个baseline在时序数据的预测中)。
2.1.1 moving average
我们假设未来某个值的预测,取决于它前面的 n 个数的平均值,因此,我们将用 moving average (移动平均数) 作为 target 的预测值,数学表达式为:y ^ t = 1 k ∑ n = 0 k − 1 y t − n \hat{y}_{t}=\frac{1}{k} \sum_{n=0}^{k-1} y_{t-n}y^t=k1n=0∑k−1yt−n
用 numpy.average() 函数实现上述的功能:
def moving_average(series, n):
"""
Calculate average of last n observations
"""
return np.average(series[-n:])
moving_average(ads, 24) # 对过去24小时的广告浏览量的预测不幸的是,上面这种方式,不适合我们进行长期的预测(为了预测下一个值,我们需要实际观察的上一个值)。但是 移动平均数 还有另一个应用场景,即对原始的时间序列数据进行平滑处理,以找到数据的变化趋势。
pandas 提供了一个实现接口DataFrame.rolling(window).mean(),滑动窗口 window 的值越大,意味着变化趋势将会越平滑,对于那些噪音点很多的数据集(尤其是金融数据),使用 pandas的这个接口,有助于探测到数据中存在的共性(common pattern)。
def plotMovingAverage(series, window, plot_intervals=False, scale=1.96, plot_anomalies=False):
"""
series - dataframe with timeseries
window - rolling window size
plot_intervals - show confidence intervals
plot_anomalies - show anomalies
"""
rolling_mean = series.rolling(window=window).mean()
plt.figure(figsize=(15,5))
plt.title("Moving average\n window size = {}".format(window))
plt.plot(rolling_mean, "g", label="Rolling mean trend")
# Plot confidence intervals for smoothed values
if plot_intervals:
mae = mean_absolute_error(series[window:], rolling_mean[window:])
deviation = np.std(series[window:] - rolling_mean[window:])
lower_bond = rolling_mean - (mae + scale * deviation)
upper_bond = rolling_mean + (mae + scale * deviation)
plt.plot(upper_bond, "r--", label="Upper Bond / Lower Bond")
plt.plot(lower_bond, "r--")
# Having the intervals, find abnormal values
if plot_anomalies:
anomalies = pd.DataFrame(index=series.index, columns=series.columns)
anomalies[series<lower_bond] = series[series<lower_bond]
anomalies[series>upper_bond] = series[series>upper_bond]
plt.plot(anomalies, "ro", markersize=10)
plt.plot(series[window:], label="Actual values")
plt.legend(loc="upper left")
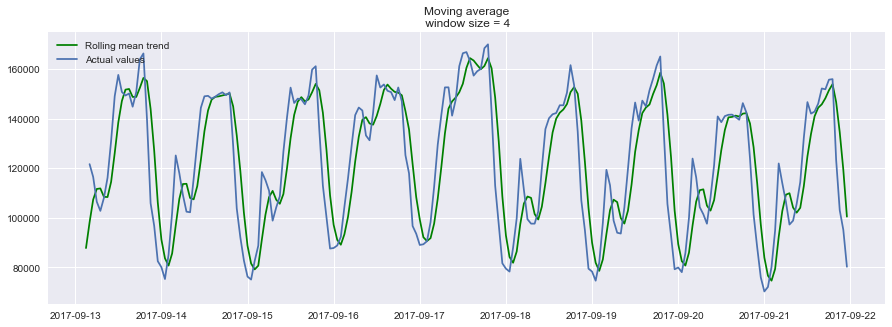
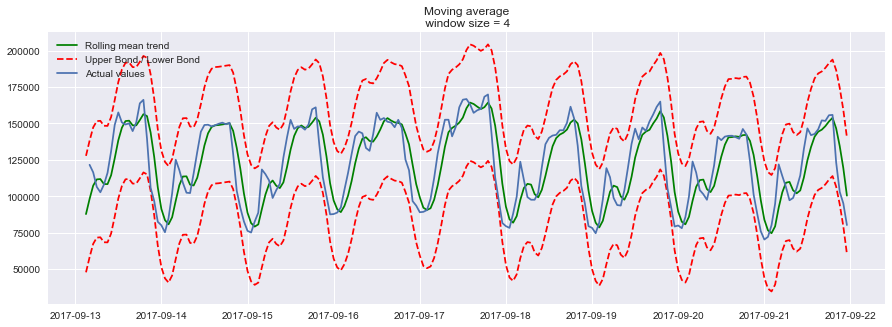
plt.grid(True)- 设置滑动窗口值为4(小时),
plotMovingAverage(ads, 4),绘制预测结果:![]()
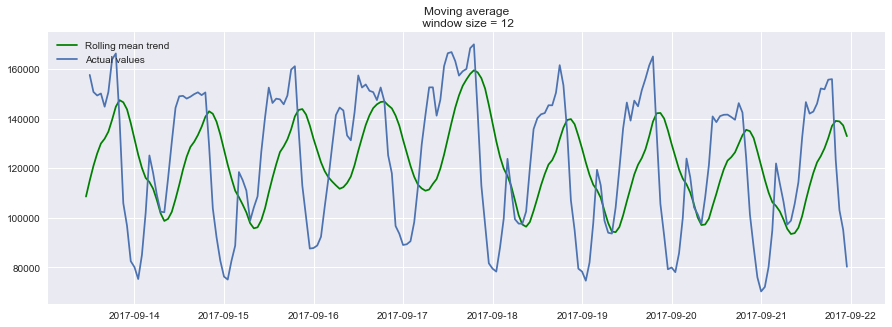
- 设置滑动窗口值为12(小时),
plotMovingAverage(ads, 12),绘制预测结果:![]()
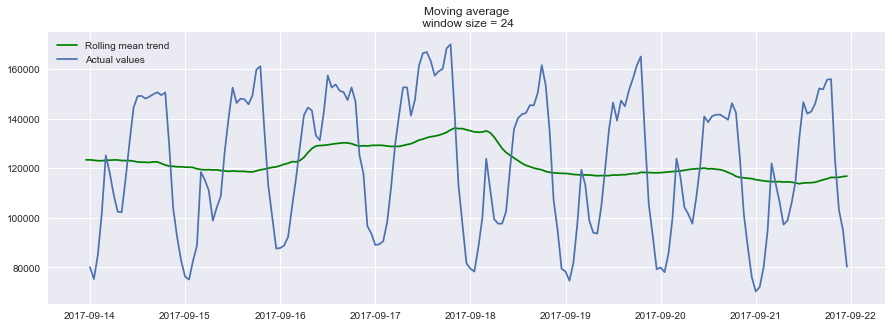
- 设置滑动窗口值为24(小时),
plotMovingAverage(ads, 24),绘制预测结果:![]()
以24小时作为滑动窗口的大小,来分析玩家每小时阅读广告量的信息时,可以清晰地发现广告浏览量的变化趋势,周末时广告浏览量较高,工作日广告浏览量较低。 - 我们还可以给我们的 平滑值 添上置信区间
plotMovingAverage(ads, 4, plot_intervals=True)![]()
现在我们再用 moving average 创建一个简单的异常检测系统(即如果数据点在置信区间之外,则认为是异常值),显然在我们上面的时间系列数据中,数据点都在置信区间以内,因此我们故意把数据中的某个值改为异常值。
ads_anomaly = ads.copy()
ads_anomaly.iloc[-20] = ads_anomaly.iloc[-20] * 0.2 # say we have 80% drop of ads 我们来瞧一下,上面这个简单的方法,是否能够找到异常值。plotMovingAverage(ads_anomaly, 4, plot_intervals=True, plot_anomalies=True)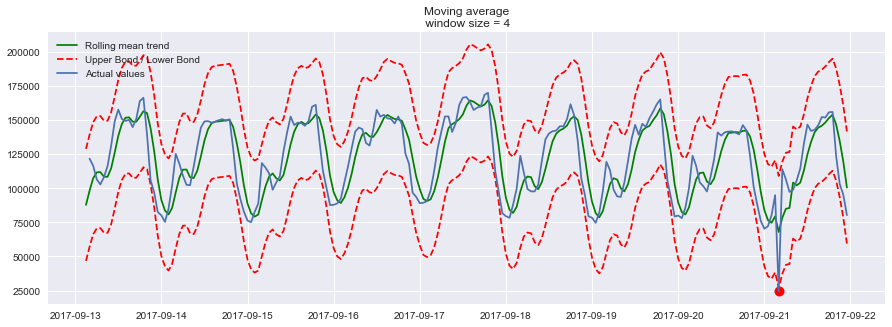
瞧!我们的方法,找到了异常点的位置(2017-09-21),那我们再来试试第二个数据序列(每天游戏币的消费情况),并且设置滑动窗口大小为7,看看是什么效果。plotMovingAverage(currency, 7, plot_intervals=True, plot_anomalies=True)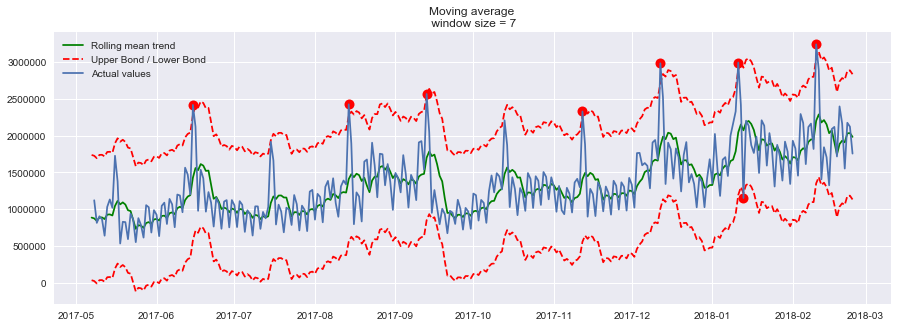
Oh no!这就暴露出我们简单方法的缺点了。它没有在我们的数据中捕捉到每个月中出现的季节性变化,反倒几乎把所有每隔30天出现的峰值标记为异常。
如果你不想有那么多的错误警报,那么最好考虑更复杂的模型。
2.1.2 weighted average
上面提到了用 移动平均值对原始数据做平滑处理,接下来要说的是加权平均值,它是对上面 移动平均值 的简单改良。
也就是说,前面 k 个观测数据的值,不再是直接求和再取平均值,而是计算它们的加权和(权重和为1)。通常来说,时间距离越近的观测点,权重越大。数学表达式为:
y ^ t = ∑ n = 1 k ω n y t + 1 − n \hat{y}_{t}=\sum_{n=1}^{k} \omega_{n} y_{t+1-n}y^t=n=1∑kωnyt+1−n
def weighted_average(series, weights):
"""
Calculate weighter average on series
"""
result = 0.0
weights.reverse()
for n in range(len(weights)):
result += series.iloc[-n-1] * weights[n]
return float(result)
weighted_average(ads, [0.6, 0.3, 0.1])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.2 指数平滑
2.2.1 exponential smoothing
如果不用上面提到的,每次对当前序列中的前k个数的加权平均值作为模型的预测值,而是直接对目前所有的已观测数据进行加权处理,并且每一个数据点的权重,呈指数形式递减。
这个就是指数平滑的策略,具体怎么做的呢?一个简单的数学式为:
y ^ t = α ⋅ y t + ( 1 − α ) ⋅ y ^ t − 1 \hat{y}_{t}=\alpha \cdot y_{t}+(1-\alpha) \cdot \hat{y}_{t-1}y^t=α⋅yt+(1−α)⋅y^t−1 式子中的 α \alphaα 表示平滑因子,它定义我们“遗忘”当前真实观测值的速度有多快。α \alphaα 越小,表示当前真实观测值的影响力越小,而前一个模型预测值的影响力越大,最终得到的时间序列将会越平滑。(这个结论要记住哦,有助于理解接下来的绘图)
那么指数体现在哪呢?指数就隐藏在递归函数之中,我们上面的函数,每次都要用( 1 − α ) (1-\alpha)(1−α)乘以模型的上一个预测值。
def exponential_smoothing(series, alpha):
"""
series - dataset with timestamps
alpha - float [0.0, 1.0], smoothing parameter
"""
result = [series[0]] # first value is same as series
for n in range(1, len(series)):
result.append(alpha * series[n] + (1 - alpha) * result[n-1])
return result
def plotExponentialSmoothing(series, alphas):
"""
Plots exponential smoothing with different alphas
series - dataset with timestamps
alphas - list of floats, smoothing parameters
"""
with plt.style.context('seaborn-white'):
plt.figure(figsize=(15, 7))
for alpha in alphas:
plt.plot(exponential_smoothing(series, alpha), label="Alpha {}".format(alpha))
plt.plot(series.values, "c", label = "Actual")
plt.legend(loc="best")
plt.axis('tight')
plt.title("Exponential Smoothing")
plt.grid(True);
plotExponentialSmoothing(ads.Ads, [0.3, 0.05])
plotExponentialSmoothing(currency.GEMS_GEMS_SPENT, [0.3, 0.05])
- 游戏玩家每小时浏览的广告量在不同平滑因子下的时序图:
![]()
- 游戏玩家每天游戏币的消费量在不同平滑因子下的时序图:
![]()
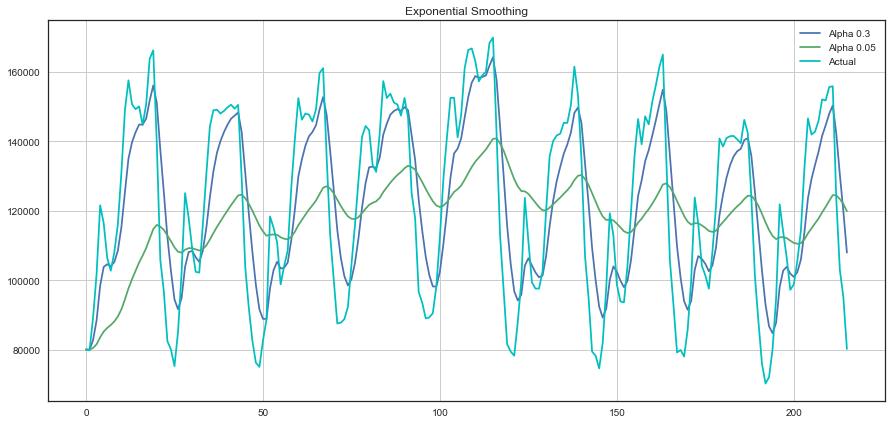
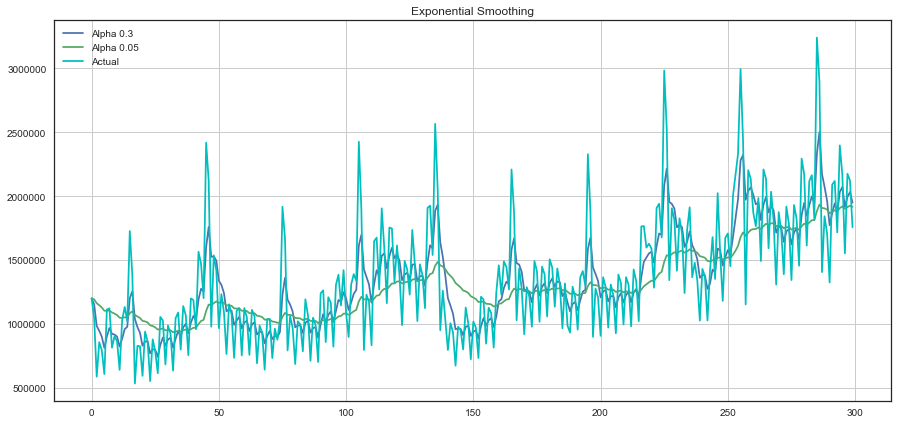
单指数平滑小结
- 单指数平滑的特点: 能够追踪数据变化。预测过程中,添加了最新的样本数据之后,新数据逐渐取代老数据的地位,最终老数据被淘汰。
- 单指数平滑的局限性: 第一,预测值不能反映趋势变动、季节波动等有规律的变动;第二,这个方法多适用于短期预测,而不适合中长期的预测;第三,由于预测值是历史数据的均值,因此与实际序列相比,有滞后的现象。
- 单指数平滑的系数: EViews提供两种确定指数平滑系数的方法:自动给定和人工确定。一般来说,如果序列变化比较平缓,平滑系数值应该比较小,比如小于0.l;如果序列变化比较剧烈,平滑系数值可以取得大一些,如0.3~0.5。若平滑系数值大于0.5才能跟上序列的变化,表明序列有很强的趋势,不能采用一次指数平滑进行预测。
2.2.2 double exponential smoothing
前面在对于单指数平滑的小结中,提到了它的一些局限性。
单指数平滑在产生新的序列的时候,考虑了前面的 K 条历史数据,但是仅仅考虑其静态值,即没有考虑时间序列当前的变化趋势。
如果当前的时间序列数据处于上升趋势,那么当我们对明天的数据进行预测的时候,就不应该仅仅是对历史数据进行”平均“,还应考虑到当前数据变化的上升趋势。同时考虑历史平均和变化趋势,这个就是我们的双指数平滑法。
下面看看它具体是怎么做的:
通过 序列分解法 (series decomposition),我们可以得到两个分量,一个叫 intercept (also, level) ℓ \ellℓ ,另一个叫 trend (also, slope,斜率) b bb. 我们根据前面学习的方法,知道了如何预测 intercept (截距,即序列数据的期望值),我们可以将同样的指数平滑法应用到 trend (趋势)上。时间序列未来变化的方向取决于先前加权的变化。
ℓ x = α y x + ( 1 − α ) ( ℓ x − 1 + b x − 1 ) b x = β ( ℓ x − ℓ x − 1 ) + ( 1 − β ) b x − 1 y ^ x + 1 = ℓ x + b x
ℓx=αyx+(1−α)(ℓx−1+bx−1)bx=β(ℓx−ℓx−1)+(1−β)bx−1y^x+1=ℓx