
HBase面试
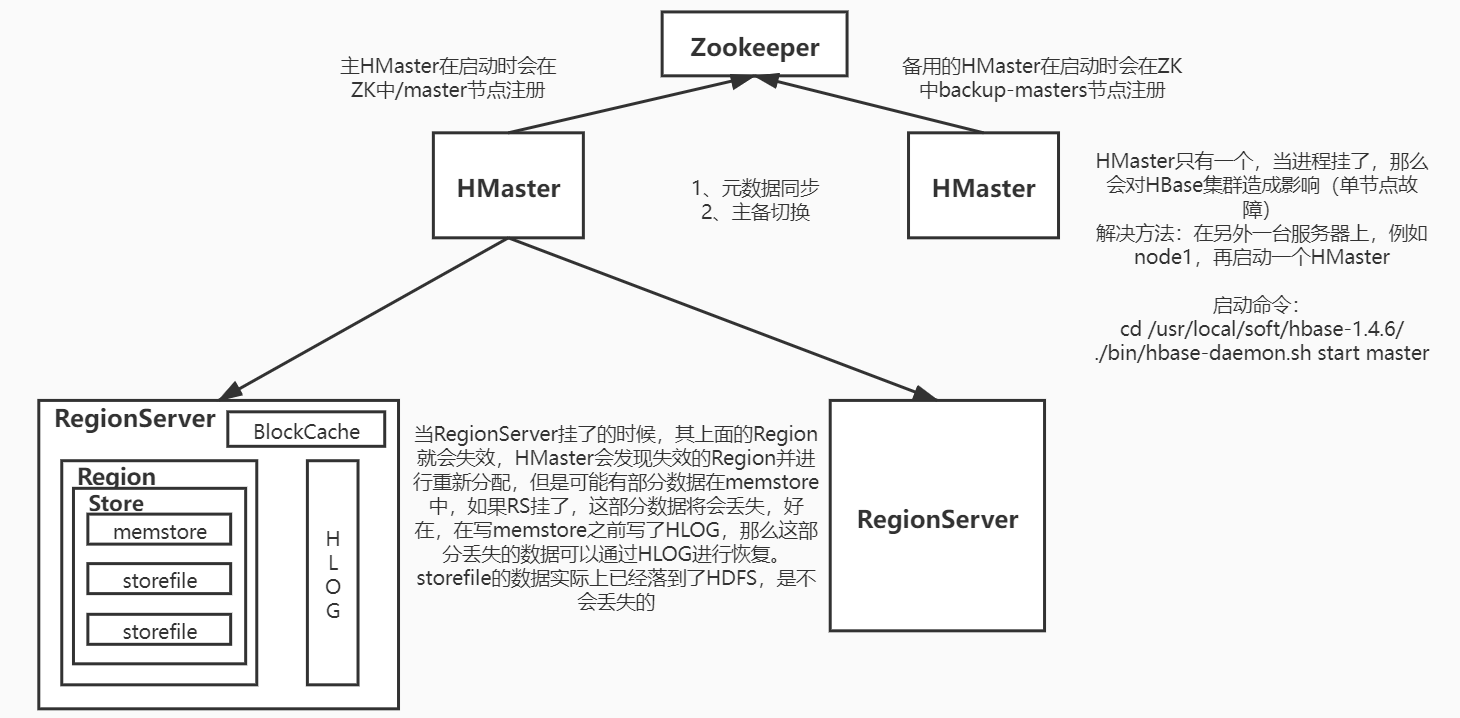
宕机问题:
MapReduce读写HBase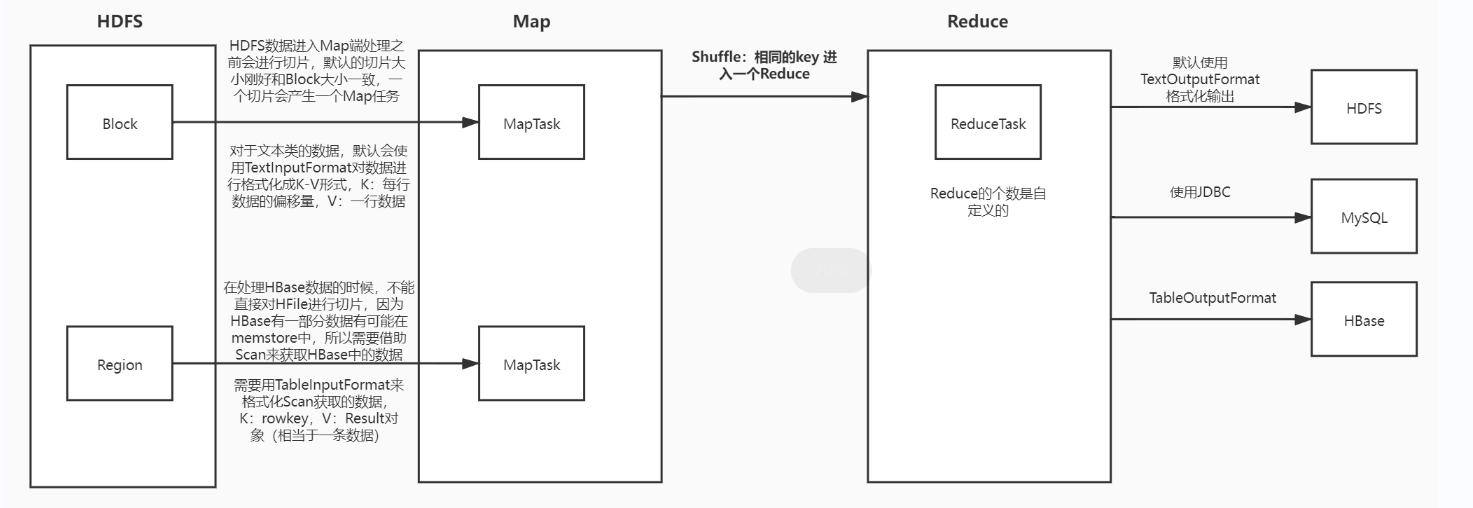
HBase特点:
1.大:一个表可以有上亿行,上百万列
2.面向列:面向列表(蔟)的存储和权限控制,列(蔟)独立检索
3.稀疏:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计非常稀疏
4.无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列
5.数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本号自动分配, 版本号就是单元格插入时的时间戳。
6.数据类型单一:HBase中的数据都是字节数组,没有类型。
ROWKEY
与NoSQL数据库一样,ROW KEY是用来检索记录的主键
访问 HBase table 中的行,只有三种方式:
* 直接通过单个RowKey
* 指定RowKey的范围
* 还可以指定跟RowKey有关的正则表达式去访问
最大长度是64KB,实际应用中长度一般为 10 ~ 100bytes
按照字典顺序存储的(1 11 111 1111 2 22 3 4 5......)
列蔟
属于表的Schema的一部分,在建表的时候必须指定至少一个Columns Family
HBase中的列归属于某一个列蔟
HBase在储存、权限控制、版本控制都是在列蔟层面上进行的
一个列蔟对应一个store
时间戳
就是一直提到的版本的概念,每条数据插入的时候都会记录插入时间(时间戳,64位整型)
如果有多个版本,会按照时间戳的倒序(时间戳越大,表示数据越新)储存数据,在获取的时候,如果不指定版本,那么会默认最新一条的数据
如果设置了TTL(Time to Live),那么HBase将会根据TTL以及数据的时间戳去删除过期的数据
Cell
Cell 是由 {row key,column(=< family> + < label>),version} 唯一确定的单元。
Cell 中的数据是没有类型的,全部是字节码形式存储。
Region的分裂策略
region中存储的是一张表的数据,当region中的数据条数过多的时候,会直接影响查询效率。当region过大的时候,region会被拆分为两个region,HMaster会将分裂的region分配到不同的regionserver上,这样可以让请求分散到不同的RegionServer上,已达到负载均衡 , 这也是Hbase的一个优点 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号