文本特征提取
英文文本特征提取
方法步骤:
①导入相关API
from sklearn.feature_extraction.text import CountVectorizer
②实例化CountVectorizer
text=CountVectorizer()
③调用fit_transform()方法进行特征提取
results=text.fit_transform(data)
主要代码:
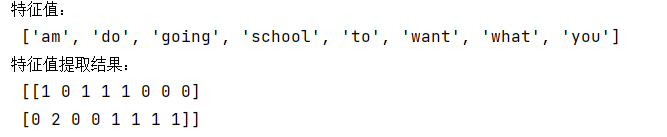
def text_demo(): data=["I am going to school","What do you want to do"] #实例化CountVectorizer text=CountVectorizer() #调用fit_transform()方法 results=text.fit_transform(data) print("特征值:\n",text.get_feature_names()) print("特征值提取结果:\n",results.toarray()) #results.toarray()将稀疏矩阵转换为二维数组的形式
运行结果:
中文文本特征提取
中文文本特征提取步骤与英文类似,主要区别在于中文文本特征提取需要进行分词处理,否则就会出现如下结果,将一句话作为一个词处理:

一、 中文分词(使用jieba):
①导入jieba
import jieba
②将目标进行分词处理
jieba.cut(text)
③将分词处理结果转化为列表形式
list(jieba.cut(text))
④将列表转化为字符串形式
" ".join(list(jieba.cut(text)))
主要代码:
def cut_text(text): result=" ".join(list(jieba.cut(text))) # print(result) return result
二、中文文本特征提取
①定义一个空数组,并利用该空数组接收中文分词后的结果
data_cut=[] #定义一个空数组 for i in data: data_cut.append(cut_text(i)) #利用空数组接收分词后的结果
②实例化CountVectorizer
CountVectorizer()
③调用fit_transform()方法
text.fit_transform(data_cut)
主要代码:
def chinese_text_demo(): data=["我们也可以将数据存储在文件中","但是在文件中读写数据速度相对较慢","优秀的文件很优秀"] data_cut=[] #定义一个空数组 for i in data: data_cut.append(cut_text(i)) #利用空数组接收分词后的结果 #实例化CountVectorizer text=CountVectorizer() #调用fit_transform()方法 results=text.fit_transform(data_cut) print("特征值:\n",text.get_feature_names()) print("特征值提取结果:\n",results.toarray())
运行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号