Pytorch官方教程:用RNN实现字符级的生成任务
数据处理
传送门:官方教程
数据从上面下载。本次的任务用到的数据和第一次一样,还是18个不同国家的不同名字。
但这次需要根据这些数据训练一个模型,给定国家和名字的首字母时,模型可以自动生成名字。
首先还是对数据进行预处理,和第一个任务一样,利用Unicode将不同国家的名字采用相同的编码方式,因为要生成名字,所以需要加上一个终止符,具体作用后面会提到。
import string
import os
import glob
import unicodedata
all_letters = string.ascii_letters + " .,;'-" # string.ascii_letters的作用是生成所有的英文字母
n_letters = len(all_letters) + 1 # 多加的1是指EOS
n_hidden = 128
n_categories = 18
def find_files(path):
"""
:param path:文件路径
:return: 文件列表地址
"""
return glob.glob(path) # glob模块提供了一个函数用于从目录通配符搜索中生成文件列表:
def unicode_to_ascii(str):
"""
:param str:名字
:return:返回均采用NFD编码方式的名字
"""
return ''.join(
c for c in unicodedata.normalize('NFD', str) # 对文字采用相同的编码方式
if unicodedata.category(c) != 'Mn' and c in all_letters
)
def read_lines(files_list):
"""
读取每个文件的内容
:param files_list:文件所在地址列表
:return:{国家:名字列表}
"""
category_lines = {}
all_categories = []
for file in files_list:
# os.path.splitext:分割路径,返回路径名和文件扩展名的元组
# os.path.basename:返回文件名
category = os.path.splitext(os.path.basename(file))[0]
line = [unicode_to_ascii(line) for line in open(file)]
all_categories.append(category)
category_lines[category] = line
return all_categories, category_lines

如同官方教程上的这张图片,当我们训练的数据是Kasparov时,当我们输入K,我们希望它输出a;输入a,希望输出s;... ;输入v,希望输出终止符EOS。所有对于每一个input,都需要构建一个output作为比对,计算损失。
因为名字和国家有关,所以国家类别也要作为input的一部分进行训练,下面的代码实现的是将训练所需的数据转化为张量。
import torch
def category_to_tensor(category):
"""
将类别转换成张量
:param category:类别
:return:张量
"""
li = all_categories.index(category)
tensor = torch.zeros(1, n_categories)
tensor[0][li] = 1
return tensor.to(device)
def input_to_tensor(input):
"""
将输入进行one-hot编码
:param word: 单词
:return: 张量
"""
tensor = torch.zeros(len(input), 1, n_letters)
for i, letter in enumerate(input):
tensor[i][0][all_letters.find(letter)] = 1
return tensor.to(device)
def target_to_tensor(input):
"""
对目标输出进行one-hot编码,即为从第二个字母开始至结束字母的索引,以及EOS的索引
:param input:单词
:return:张量
"""
letter_indexes = [all_letters.find(input[i]) for i in range(1, len(input))]
letter_indexes.append(n_letters - 1) # 最后一位的索引是EOS
return torch.LongTensor(letter_indexes).to(device)
模型构建

class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(n_categories + input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(n_categories + input_size + hidden_size, output_size)
self.o2o = nn.Linear(hidden_size + output_size, output_size)
self.dropout = nn.Dropout(0.1)
self.softmax = nn.LogSoftmax(dim=1) # dim=1表示对第1维度的数据进行logsoftmax操作
def forward(self, category, input, hidden):
input_tmp = torch.cat((category, input, hidden), 1)
hidden = self.i2h(input_tmp)
output = self.i2o(input_tmp)
output_tmp = torch.cat((hidden, output), 1)
output = self.o2o(output_tmp)
output = self.dropout(output)
output = self.softmax(output)
return output, hidden
def init_hidden(self): # 隐藏层初始化0操作
return torch.zeros(1, self.hidden_size).to(device)
模型训练
训练的过程依旧是迭代多次,每次从数据中随机选择,并将所需数据转换为张量。
import random
def random_choice(obj):
return obj[random.randint(0, len(obj)-1)]
def random_training_example():
category = random_choice(all_categories)
input = random_choice(category_lines[category])
category_tensor = category_to_tensor(category)
input_tensor = input_to_tensor(input)
target_tensor = target_to_tensor(input)
return category_tensor, input_tensor, target_tensor
训练代码如下:
import torch.nn as nn
import time
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
def train():
rnn = RNN(n_letters, n_hidden, n_letters).to(device)
loss = nn.NLLLoss()
total_loss = 0
all_losses = []
epoch_num = 100000
lr = 0.0005
epoch_start_time = time.time()
for epoch in range(epoch_num):
rnn.zero_grad()
train_loss = 0
hidden = rnn.init_hidden()
category_tensor, input_tensor, target_tensor = random_training_example()
target_tensor.unsqueeze_(-1)
for i in range(input_tensor.size()[0]):
output, hidden = rnn(category_tensor, input_tensor[i], hidden)
train_loss += loss(output, target_tensor[i]) # 每次的loss都需要计算
train_loss.backward()
for p in rnn.parameters():
p.data.add_(p.grad.data, alpha=-lr)
total_loss += train_loss.item() / input_tensor.size()[0] # 该名字的平均损失
if epoch % 5000 == 0:
print('[%05d/%03d%%] %2.2f sec(s) Loss: %.4f' %
(epoch, epoch / epoch_num * 100, time.time()-epoch_start_time, train_loss.item() / input_tensor.size()[0]))
epoch_start_time = time.time()
if (epoch+1) % 500 == 0:
all_losses.append(total_loss / 500)
total_loss = 0
torch.save(rnn.state_dict(), 'rnn_params.pkl') # 保存模型的数据
plt.figure()
plt.plot(all_losses)
plt.show()
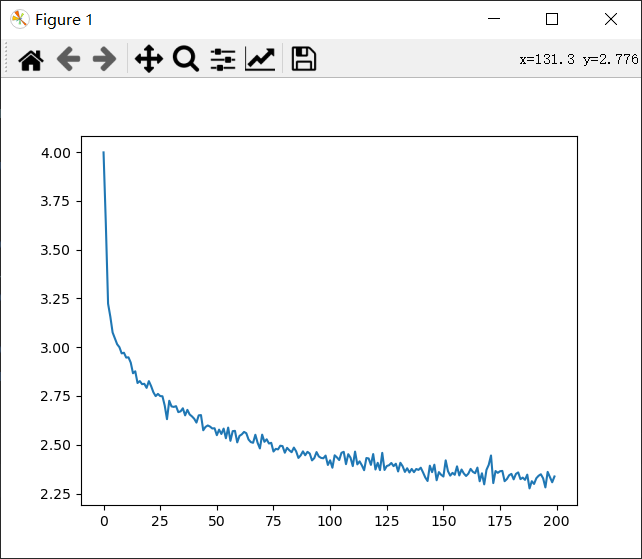
模型预测
def predict(category, start_letter):
rnn = RNN(n_letters, n_hidden, n_letters).to(device)
rnn.load_state_dict(torch.load('rnn_params.pkl')) # 加载模型训练所得到的参数
max_length = 20 # 名字的最大长度
with torch.no_grad():
category_tensor = category_to_tensor(category)
input = input_to_tensor(start_letter)
hidden = rnn.init_hidden()
output_name = start_letter
for i in range(max_length):
output, hidden = rnn(category_tensor, input[0], hidden)
top_v, top_i = output.topk(1) # 选出最大的值,返回其value和index
top_i = top_i.item()
if top_i == n_letters - 1: # n-letters-1是EOS
break
else:
letter = all_letters[top_i]
output_name += letter
input = input_to_tensor(letter) # 更新input,继续循环迭代
return output_name

完整代码
import string
import os
import glob
import unicodedata
import torch
import torch.nn as nn
import random
import time
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
all_letters = string.ascii_letters + " .,;'-" # string.ascii_letters的作用是生成所有的英文字母
n_letters = len(all_letters) + 1 # 多加的1是指EOS
n_hidden = 128
n_categories = 18
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(n_categories + input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(n_categories + input_size + hidden_size, output_size)
self.o2o = nn.Linear(hidden_size + output_size, output_size)
self.dropout = nn.Dropout(0.1)
self.softmax = nn.LogSoftmax(dim=1) # dim=1表示对第1维度的数据进行logsoftmax操作
def forward(self, category, input, hidden):
input_tmp = torch.cat((category, input, hidden), 1)
hidden = self.i2h(input_tmp)
output = self.i2o(input_tmp)
output_tmp = torch.cat((hidden, output), 1)
output = self.o2o(output_tmp)
output = self.dropout(output)
output = self.softmax(output)
return output, hidden
def init_hidden(self): # 隐藏层初始化0操作
return torch.zeros(1, self.hidden_size).to(device)
def find_files(path):
"""
:param path:文件路径
:return: 文件列表地址
"""
return glob.glob(path) # glob模块提供了一个函数用于从目录通配符搜索中生成文件列表:
def unicode_to_ascii(str):
"""
:param str:名字
:return:返回均采用NFD编码方式的名字
"""
return ''.join(
c for c in unicodedata.normalize('NFD', str) # 对文字采用相同的编码方式
if unicodedata.category(c) != 'Mn' and c in all_letters
)
def read_lines(files_list):
"""
读取每个文件的内容
:param files_list:文件所在地址列表
:return:{国家:名字列表}
"""
category_lines = {}
all_categories = []
for file in files_list:
# os.path.splitext:分割路径,返回路径名和文件扩展名的元组
# os.path.basename:返回文件名
category = os.path.splitext(os.path.basename(file))[0]
line = [unicode_to_ascii(line) for line in open(file)]
all_categories.append(category)
category_lines[category] = line
return all_categories, category_lines
def category_to_tensor(category):
"""
将类别转换成张量
:param category:类别
:return:张量
"""
li = all_categories.index(category)
tensor = torch.zeros(1, n_categories)
tensor[0][li] = 1
return tensor.to(device)
def input_to_tensor(input):
"""
将输入进行one-hot编码
:param word: 单词
:return: 张量
"""
tensor = torch.zeros(len(input), 1, n_letters)
for i, letter in enumerate(input):
tensor[i][0][all_letters.find(letter)] = 1
return tensor.to(device)
def target_to_tensor(input):
"""
对目标输出进行one-hot编码,即为从第二个字母开始至结束字母的索引,以及EOS的索引
:param input:单词
:return:张量
"""
letter_indexes = [all_letters.find(input[i]) for i in range(1, len(input))]
letter_indexes.append(n_letters - 1) # 最后一位的索引是EOS
return torch.LongTensor(letter_indexes).to(device)
def random_choice(obj):
return obj[random.randint(0, len(obj)-1)]
def random_training_example():
category = random_choice(all_categories)
input = random_choice(category_lines[category])
category_tensor = category_to_tensor(category)
input_tensor = input_to_tensor(input)
target_tensor = target_to_tensor(input)
return category_tensor, input_tensor, target_tensor
def train():
rnn = RNN(n_letters, n_hidden, n_letters).to(device)
loss = nn.NLLLoss()
total_loss = 0
all_losses = []
epoch_num = 100000
lr = 0.0005
epoch_start_time = time.time()
for epoch in range(epoch_num):
rnn.zero_grad()
train_loss = 0
hidden = rnn.init_hidden()
category_tensor, input_tensor, target_tensor = random_training_example()
target_tensor.unsqueeze_(-1)
for i in range(input_tensor.size()[0]):
output, hidden = rnn(category_tensor, input_tensor[i], hidden)
train_loss += loss(output, target_tensor[i]) # 每次的loss都需要计算
train_loss.backward()
for p in rnn.parameters():
p.data.add_(p.grad.data, alpha=-lr)
total_loss += train_loss.item() / input_tensor.size()[0] # 该名字的平均损失
if epoch % 5000 == 0:
print('[%05d/%03d%%] %2.2f sec(s) Loss: %.4f' %
(epoch, epoch / epoch_num * 100, time.time()-epoch_start_time, train_loss.item() / input_tensor.size()[0]))
epoch_start_time = time.time()
if (epoch+1) % 500 == 0:
all_losses.append(total_loss / 500)
total_loss = 0
torch.save(rnn.state_dict(), 'rnn_params.pkl') # 保存模型的数据
plt.figure()
plt.plot(all_losses)
plt.show()
def predict(category, start_letter):
rnn = RNN(n_letters, n_hidden, n_letters).to(device)
rnn.load_state_dict(torch.load('rnn_params.pkl')) # 加载模型训练所得到的参数
max_length = 20 # 名字的最大长度
with torch.no_grad():
category_tensor = category_to_tensor(category)
input = input_to_tensor(start_letter)
hidden = rnn.init_hidden()
output_name = start_letter
for i in range(max_length):
output, hidden = rnn(category_tensor, input[0], hidden)
top_v, top_i = output.topk(1) # 选出最大的值,返回其value和index
top_i = top_i.item()
if top_i == n_letters - 1: # n-letters-1是EOS
break
else:
letter = all_letters[top_i]
output_name += letter
input = input_to_tensor(letter) # 更新input,继续循环迭代
return output_name
if __name__ == '__main__':
files_list = find_files('./names/*.txt')
all_categories, category_lines = read_lines(files_list)
#train()
print(predict('English', 'V'))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号