Hudi安装配置
简介
Hudi(Hadoop Upserts Delete and Incremental)是下一代流数据湖平台。Apache Hudi将核心仓库和数据库功能直接引入数据湖。Hudi提供了表、事务、高效的upserts/delete、高级索引、流摄取服务、数据集群/压缩优化和并发,同时保持数据的开源文件格式。Hudi不仅非常适合于流工作负载,而且还允许创建高效的增量批处理管道。Hudi可以轻松地在任何云存储平台上使用。Hudi的高级性能优化,使分析工作负载更快的任何流行的查询引擎,包括Apache Spark、Flink、Presto、Trino、Hive等。
以下是一个简单的 Hudi 安装和配置文档。请注意,此文档只适用于特定环境下无须编译的情况,但是在
hudi安装配置
1、将maven相关安装包解压到/opt/module/目录下(若路径不存在,则需新建)并配置maven本地库为/opt/software/RepMaven/,远程仓库使用阿里云镜像,配置maven的环境变量,并在/opt/下执行mvn -v
# 解压
tar -zxvf apache-maven-3.6.3-bin.tar.gz -C /opt/module
# 配置maven环境变量
vi /etc/profile
export MAVEN_HOME=/opt/module/apache-maven-3.6.3-bin
export PATH=$PATH:$MAVEN_HOME/bin
source /etc/profile
# 测试安装成功
mvn -v
# 配置maven的仓库地址
cd /opt/module/apache-maven-3.6.3-bin/conf
vi settings.xml
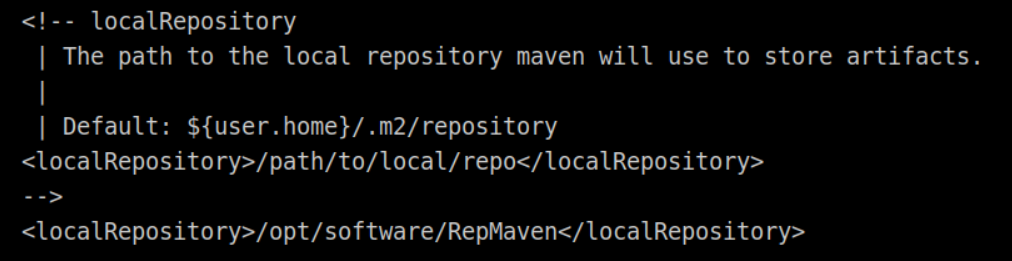
# 在mirrors标签中加入
<!-- 添加阿里云镜像-->
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
2、将Hudi相关安装包解压到/opt/module/目录下
tar -zxvf hudi-0.12.0.src.tgz -C /opt/module
3、完成解压安装及配置后使用maven对Hudi进行构建(spark3.1,scala-2.12),编译完成后与Spark集成,集成后使用spark-shell操作Hudi,将spark-shell启动使用spark-shell运行下面给到的案例
# 案例:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.common.model.HoodieRecord
val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
val dataGen = new DataGenerator
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
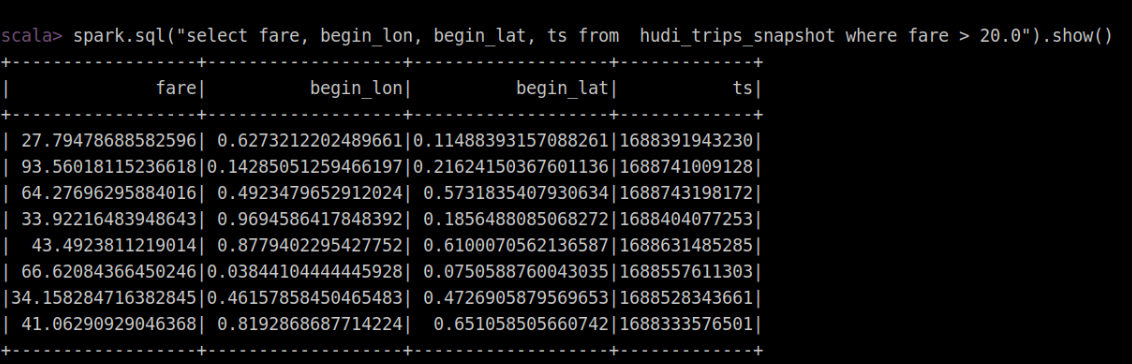
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
在此处无须编译(特定环境下无须编译)直接执行下面命令并执行上述案例:
spark-shell --jars /opt/software/hudi-spark3.1-bundle_2.12-0.12.0.jar --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
执行案例结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号